


























Introduction
Let us discuss the problem statement. We are given two positive integers, N and K. We need to find the count of sequences of length K such that all the numbers in the sequence must line in the range [1, N], and every element in the sequence must be a multiple of the previous element.
Example
Input
N = 3
K = 2
Output
5
Explanation:
The sequences that follow the given constraints are: {1, 1}, {2, 2}, {3, 3}, {1, 2}, {1,3}, a total of 5.
Note that every sequence is of length (K=2), and every element in a sequence is a multiple of the previous element (except for the first because the first element doesn't have any previous element).
Input
N = 10
K = 6
Output
195
Explanation:
It is not possible to count all the valid sequences manually. Further, in the article, we will check this using code.
Solution Approach
Idea
We can use memoization to solve the problem efficiently. We define a dp[i][j] as the number of valid sequences starting with "i" and having a length "j". This problem has overlapping subproblems and optimal substructure. Therefore we go with dp. The following image shows the recursive tree and overlapping subproblems for more clarity. F(start, len) = countSeqHelper(start, len, N), don’t get confused. We omit N as a parameter in F because it is just a visual representation.
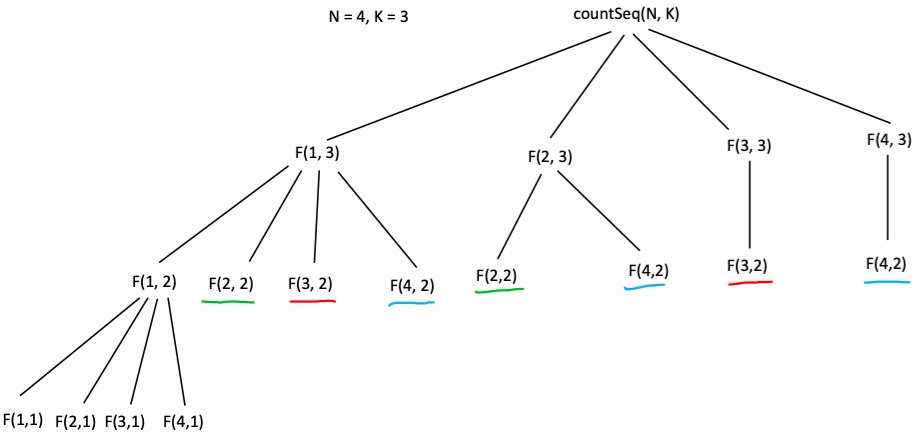
Note equivalent subproblems are underlined in the same colour.
Algorithm
We define a wrapper function countSeq(N, K) as follows:
- Initialize ANS = 0
- Initialize global dp[][] = -1, to store the value of the states.
- Run a loop i: 1 to N and call for countSeqHelper(i, K, N) add the result of this call to the ANS.
- countSeqHelper(i, K, N) returns the number of valid sequences having a length of K and starting from i.
- Finally, we return ANS.
-
Now, we need to define the function countSeqHelper(start, len, N):
- Base case: If i == 1, return 1. It is obvious that the number of sequences of length 1 starting with "i" is 1.
- We check if dp[start][len] != -1, return dp[start][len], as the value of this state is already calculated.
- Initialize ans = 0
- Run a loop i: 1 to (N / start). Note "start * i" will always be a multiple of start.
- Now recursively call for countSeqHelper(start * i, len - 1, N), add the result of this call to ans.
- Return ans.
C++ Code implementation
#include <algorithm>
using namespace std;
// Global dp array for storing states
int dp[1001][1001];
int countSeqHelper(int start, int len, int n)
{
/*
Count of sequences starting with "start"
and having a length of 1 is 1
*/
if (len == 1)
{
return 1;
}
/*
If this state has already been calculated
simply return it.
*/
if (dp[start][len] != -1)
{
return dp[start][len];
}
/*
Calculate the value of dp[start][len],
store it and return it
*/
int ans = 0;
for (int i = 1; i <= n / start; i++)
{
ans += countSeqHelper(start * i, len - 1, n);
}
return dp[start][len] = ans;
}
int countSeq(int n, int k)
{
/*
dp[i][j] = -1 means, this state of
is yet to be calculated
*/
memset(dp, -1, sizeof(dp));
int ans = 0;
for (int i = 1; i <= n; i++)
{
ans += countSeqHelper(i, k, n);
}
return ans;
}
int main()
{
int n = 10, k = 6;
vector<int> seq;
cout << countSeq(n, k) << endl;
return 0;
}
Output
195Complexity Analysis
Time complexity: O(N * K * logN)
The total unique dp states are N K. This can be deduced from the fact that start ranges from 1 to N and len ranges from 1 to K. This implies that the countSeqHelper(start, len, N) is called N K times. In this method, we are running a loop from 1 to (N / start), and start can range from [1,n]. So in some cases, let say when start = N, the loop runs for just 1 time and when start = 1, the loop runs for N times. For any arbitrary value of start say, K, where 1 <= K <= N, the loop runs for N / K times. So, the total number of times the loop runs can be calculated as N + N / 2 + N / 3 + … + N / K + … + 1 = N (1 + ½ + ⅓ + …) = N * logN.
You can read more about it here.
For average we simply divide by N. Therefore, the average time complexity of the loop is O(logN). All other operations in this method take constant time. Therefore, the overall time complexity is O(N*K*logN).
Space Complexity: O(N * K)
The total unique dp states are N * K, as discussed in the previous section. We need an auxiliary array DP to store the values. Hence the space complexity is O(N * K).
FAQs
-
Explain how the total number of unique dp states is N * K (in this problem).
We define a dp state, dp[i][j] as the length of sequences of length j starting with i. Now “i” can vary from 1 to N and “j” can vary from 1 to K as per the problem. Hence the total number of dp states are N*K.
-
To solve DP problems, we can use Memoization and tabulation. How are the two different from one another?
The bottom-up approach (to dynamic programming) i.e. tabulation consists in first looking at the "smaller" subproblems, and then solving the larger subproblems using the solution to the smaller problems.
The top-down approach (to dynamic programming) i.e. memoization consists in solving the problem in a "natural manner" and checking if you have calculated the solution to the subproblem before.
Key Takeaways
In this blog, we discussed a very interesting dp problem. We used memoization to solve the problem efficiently. You will find many questions on this approach in online assessments of various tech- companies. We have also discussed the time and space complexity. Remember, always try to find the time and space complexity of your solutions because you will be asked to find the complexities of your solutions in your interviews. If you love solving coding problems, then please do visit this incredible platform Coding Ninjas Studio.
You can enrol in the interview preparation course to ace your technical interviews.
If you feel that this blog has helped you in any way, then please do share it with your friends. Happy Coding!


 9+ registered
9+ registered 

