Do you think IIT Guwahati certified course can help you in your career?
Introduction
Hey Ninjas! Many common questions are asked in the companies' interviews and coding rounds. These require knowledge of Data Structures and Algorithms. A common question in the coding interview is counting smaller numbers after self.
Given an array of integers, for each element in the array, count the number of elements to its right that are smaller than it and return an array of counts.
Sample Example
We will take an example so the problem statement will be clear for you.
Input:
[6, 3, 7, 2]
Output:
[2, 1, 1, 0]
Explanation:
Integers to the right of '6', there are 2 smaller integers (3, 2).
Integers to the right of '3', there is 1 smaller integer (2).
Integers to the right of '7', there is 1 smaller integer (2).
BruteForce Approach
We will first head with a naive or straightforward approach to solving this problem, then move on to efficient methods by considering the complexities.
Algorithm
In this case, we'll need two loops.
The items will be collected from the left to the right using an outer loop.
The inner loop will increase the count while iterating through the element's right-side elements.
The new array contains the total number of elements.
Dry Run
Firstly, we define a vector of integers called ans to store the results.
We Iterate over each element in arr using a for loop, with the loop variable i. For each element in arr, we iterate over the remaining elements in arr using another for loop, with the loop variable j starting from i+1.
If the element at index j is less than the element at index i, we increment a counter variable called countnum. After the inner loop is finished, append the value of countnum to the ans vector.
For 6, we find 2 integers smaller to the right of 6 (3, 2).
For 3, we find 1 integer smaller to the right of 3 (2).
For 7, we find 1 integer smaller to the right of 7 (2).
For 2, we find 0 integers smaller to the right of 2.
So the final answer array(arr) we get {2, 1, 1, 0}.
Implementation in C++
#include <bits/stdc++.h>
using namespace std;
int main(){
// declare an array of integers
vector<int> arr = {6, 3, 7, 2};
// set the size of the array
int n = 4;
// create an empty vector to store the results
vector<int> ans;
// iterate through each element in the array
for (int i = 0; i < n; i++){
// initialize a count to zero
int countnum = 0;
// set the current element to the ith element in the array
int curr = arr[i];
// iterate through all elements to the right of the current element
for (int j = i + 1; j < n; j++){
// if the element is smaller than the current element, increment countnum
if (arr[j] < curr){
countnum++;
}
}
// add the value of countnum to the answer vector
ans.push_back(countnum);
}
// print the values of the answer vector
for (int i = 0; i < n; i++){
cout << ans[i] << " ";
}
// print a new line
cout << endl;
}
You can also try this code with Online C++ Compiler
The algorithm employed is a straightforward nested loop with an O(n^2) time complexity, where n is the array's size. Every time the outer loop is iterated, the inner loop is also iterated n times.
Space Complexity
The space complexity of this program is O(n), where n is the size of the answer array.
Bit Indexed Tree(BIT) Approach
The given approach addresses the problem of counting the number of smaller items on the right side of each element using a Binary Indexed Tree (BIT) or Fenwick Tree. A data structure called a "Fenwick tree," commonly referred to as a "binary indexed tree," enables quick updates and searches of an array's prefix sums (cumulative sums). When the array is often updated and accurate prefix sum calculations are required, it is especially helpful.
Algorithm
Create a blank result vector and initialise it to store the counts of smaller items.
Create a Binary Indexed Tree (BIT) with a size of 20005 with all of its elements set to 0.
Add a constant value of 10001 to the input vector to make all of its elements positive.
Go through the elements in nums from right to left, iterating over them.
Use the BIT to query the count of smaller elements to the right of the current element, storing the result.
Add the current element to the BIT, and store the count in the result vector.
Return the result vector.
Dry Run
Initialize an empty result vector to store the counts of smaller elements: result = {0, 0, 0, 0}.
Initialize a Binary Indexed Tree (BIT) with a size of 20005 and set all elements to 0.
To make all elements in the input vector nums positive add a constant value of 10001: nums = {10007, 10004, 10008, 10003}.
For the last element 10003, we use the BIT to query the count of smaller elements on the right side of the current element, smallerCount = getSum(10003-1, bit) = getSum(10002, bit) = 0, we store the count in the result vector: result[3] = 0 and add the current element to the BIT: update(10003, bit) updates bit[10003] to 1.
For the third element 10008, we use the BIT to query the count of smaller elements on the right side of the current element, smallerCount = getSum(10008-1, bit) = getSum(10007, bit) = 1, we store the count in the result vector, result[2] = 1 and add the current element to the BIT: update(10008, bit) updates bit[10008] to 1.
For the second element 10004, we use the BIT to query the count of smaller elements on the right side of the current element, smallerCount = getSum(10004-1, bit) = getSum(10003, bit) = 1, Store the count in the result vector, result[1] = 1 and add the current element to the BIT: update(10004, bit) updates bit[10004] to 1.
For the first element 10007, we use the BIT to query the count of smaller elements on the right side of the current element, smallerCount = getSum(10007-1, bit) = getSum(10006, bit) = 2, we store the count in the result vector, result[0] = 2 and add the current element to the BIT, update(10007, bit) updates bit[10007] to 1.
So the result vector becomes {2, 1, 1, 0} which is the required answer.
Implementation in C++
#include <bits/stdc++.h>
using namespace std;
// Update BIT at index
void update(int index, vector<int> &bit){
while (index <= bit.size()){
bit[index]++; // Increment the value at the current index
index += index & -index; // Move to next index in the BIT
}
}
// Get sum of values up to index in BIT
int getSum(int index, vector<int> &bit){
int sum = 0;
while (index > 0){
sum += bit[index]; // Add the value at the current index
index -= index & -index; // Move to previous index in the BIT
}
return sum;
}
vector<int> countSmaller(vector<int> &nums){
vector<int> result(nums.size(), 0); // Initialize result vector
vector<int> bit(20005, 0); // Binary Indexed Tree Array
for (int i = 0; i < nums.size(); i++){
nums[i] += 10001; // Make all numbers positive to fit in BIT
}
for (int i = nums.size() - 1; i >= 0; i--){
int smallerCount = getSum(nums[i] - 1, bit); // Get count of smaller elements
result[i] = smallerCount; // Update result with count of smaller elements
update(nums[i], bit); // Update BIT with current element
}
return result;
}
int main(){
vector<int> arr = {6, 3, 7, 2};
int n = 4;
vector<int> ans = countSmaller(arr);
for (auto x : ans){
cout << x << " ";
}
cout << endl;
return 0;
}
You can also try this code with Online C++ Compiler
O(n log m), where n is the size of the input vector nums, and m is the range of values in nums. This is because the algorithm performs a binary indexed tree (BIT) update and BIT query for each element in nums, and the time complexity of both of these operations is O(log m).
Space Complexity
O(m), since we create a BIT array of size m to store the frequency of values in nums.
Merge Sort Approach
One way to solve this problem is to use the merge sort algorithm, which has a time complexity of O(nlogn). In merge sort, the input array is recursively divided into halves until each sub-array has only one element. Then, the sub-arrays are merged back together in sorted order. While merging the sub-arrays, we can keep track of the number of elements that are smaller than the current element in the right sub-array.
Algorithm
We declare a pair of int B(vector<<pair<int, int >>B) vectors and a Vector ans for counting. We traverse the existing array and add each pair of elements with the relevant index to the new array. For this array, we will use our merge sort algorithm.
To traverse our left and right arrays and merge them in descending order, we declare two pointers, i and j, in the merge function as per usual.
Now that we have traversed these two arrays, we know that every element in the right array is also present in the left array but on the right side of the elements in the left array (in the actual array).
Hence, we increment our count by [V[i].second] += size of the right array - j+1 anytime we find an element in the left array that is higher than the element in the right array (V[i].first > V[j].first). Since our arrays are arranged in decreasing order, all elements immediately adjacent to a given element are smaller than V[i].first.
We sort in decreasing order after increasing the count and advancing our points i and j.
Dry Run
Firstly, just as we do normal merge sort, we recursively split the array and go top-down until each sub-array is of size 1.
Now, we go back bottom-up. We merge [6] and [3] into a result array.
Normally, we just compare the first element of both sub-arrays (6 and 3), take a smaller element (3), and put a smaller element into the "merged" area (now holding only 3).
Let's continue on our original example, from the Sample Example,
result count: 6(0) 3(0) 7(0) 2(0)
6(0) means there are currently 0 elements to the right of 6 which are smaller than 6.
if we merge up one level from the bottom, 3 is smaller than, and to the right of 6, so we increment count for 6.
2 is smaller than, and to the right of 7, so we increment count for 7.
result count: 6(1) 3(0) 7(1) 2(0)
Now we have to merge, left sub-array, [3, 6] and right sub-array [2, 7].
We notice that all elements in the right sub-array, are originally positioned to the right, of all elements in the left sub-array.
2, from the right sub-array, is less than 3 from the left sub-array. That means 2 is positioned right of 3 and smaller than 3, So we should increment the answer result count for 3. 2 is also less than 6 and positioned to the right of 6. In fact, 2 is less than and positioned to the right of all elements in the left subarray after element 3 because the left sub-array was already sorted from previous recursion merge-sort calls. In this example, it would be (2 < 3 < 6) So we must increment the answer result count for 6.
now, the only element in the right sub-array is 7. The elements in the left sub-array [3, 6] are smaller than 7. They are not what the problem is looking for, so move them to the "merged" area, the same as the normal merge sort.
Merge sort is done now. The final answer result count is [2,1,1,0]
Implementation in C++
#include <bits/stdc++.h>
using namespace std;
// merge two sorted arrays and count inversions
void merge(vector<pair<int, int>> &v, vector<int> &ans, int start, int mid, int end){
vector<pair<int, int>> temp; // temporary vector to store the merged result
int i = start; // pointer to the start of the left subarray
int j = mid + 1; // pointer to the start of the right subarray
while (i < mid + 1 && j <= end){ // loop until one of the subarrays is exhausted
if (v[i].first > v[j].first){ // if the left element is greater than the right element
ans[v[i].second] += (end - j + 1); // increment the inversion count for the left element
temp.push_back(v[i]); // push the left element to the temporary vector
i++; // move the left pointer forward
}
else{ // if the right element is greater than or equal to the left element
temp.push_back(v[j]); // push the right element to the temporary vector
j++; // move the right pointer forward
}
}
while (i <= mid){ // copy any remaining elements in the left subarray to the temporary vector
temp.push_back(v[i]);
i++;
}
while (j <= end){ // copy any remaining elements in the right subarray to the temporary vector
temp.push_back(v[j]);
j++;
}
int k = 0;
for (int i = start; i <= end; i++){ // copy the merged and sorted result from the temporary vector back to the original vector
v[i] = temp[k];
k++;
}
}
// recursively sort and count inversions in an array
void mergesort(vector<pair<int, int>> &v, vector<int> &ans, int i, int j){
if (i < j){ // if the array has more than one element
int mid = (i + j) / 2; // find the midpoint
mergesort(v, ans, i, mid); // recursively sort the left half
mergesort(v, ans, mid + 1, j); // recursively sort the right half
merge(v, ans, i, mid, j); // merge the two sorted halves and count inversions
}
}
int main(){
int arr[] = {6, 3, 7, 2}; // input array
int n = 4;
vector<pair<int, int>> B; // vector of pairs to store the elements and their original indices
for (int i = 0; i < n; i++){
B.push_back({arr[i], i}); // add each element and its index to the vector
}
vector<int> ans(n, 0); // vector to store the inversion counts
mergesort(B, ans, 0, n - 1); // sort the array and count inversions
for (auto x : ans){ // print the inversion counts
cout << x << " ";
}
cout << endl;
return 0;
}
You can also try this code with Online C++ Compiler
O(NlogN), Used for Merge Sort. The merge sort always divides the array into two halves which takes logN time and takes linear time to merge two halves.
Space Complexity
O(N), Which is the Space used to store the pair values in a different array and answer array.
Frequently Asked Questions
What do you mean by Binary Search Tree?
In a binary search tree, the left subtree of each node only contains nodes whose values are smaller than the node. The only elements in the node's right subtree are those with more than the node's value. Moreover, the left and right subtrees must also be binary search trees.
What is the Merge Sort Algorithm?
It is one of the most important algorithms for interviews. It is basically a Divide and conquer algorithm. It divides the array into two halves, makes a call to itself, and then merges the two sorted halves.
What are the best approaches to solve this problem?
There can be more approaches to solve this problem. One of the approaches is Segment Tree, AVL Tree, and many more. Count of smaller numbers is efficiently solved using these techniques.
What is time complexity?
The time an algorithm or code takes to execute each instruction is known as its time complexity.
What is space complexity?
The total memory space used by an algorithm or code, including the space of input values, is referred to as "space complexity".
This article discusses the topic of Counting inversions on the right. In detail, we have seen the problem statement, sample example, algorithm, dry run, and implementation in two languages. Along with this, we also saw the time and space complexity.
We hope this blog has helped you enhance your knowledge of the count of cycles in a connected undirected graph. If you want to learn more, then check out our articles.
But suppose you have just started your learning process and are looking for questions from tech giants like Amazon, Microsoft, Uber, etc. In that case, you must look at the problems, interview experiences, and interview bundles for placement preparations.
However, you may consider our paid courses to give your career an edge over others!

































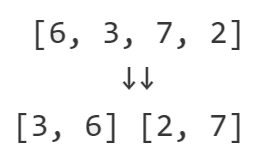



 8+ registered
8+ registered 

