Do you think IIT Guwahati certified course can help you in your career?
Introduction
In this blog, we will discuss an important problem of counting pairs from two linked lists whose sum is equal to a given value. Such problems based on linked lists are commonly asked in the interviews.
We will dive deep into each detail of this problem, but before discussing the solution to this problem, first, let us check the problem statement of the problem to get a clear understanding of the problem.
Before solving the problem, it’s recommended that a known basic traversal in the Linked List check Linked List.
We will be given a head pointer of two linked lists of size n and m having distinct integer elementsand a target as input. The problem is to count all pairs from both lists whose sum is equal to the given value target, i.e., Count pairs from two linked lists whose sum is equal to a given value target.
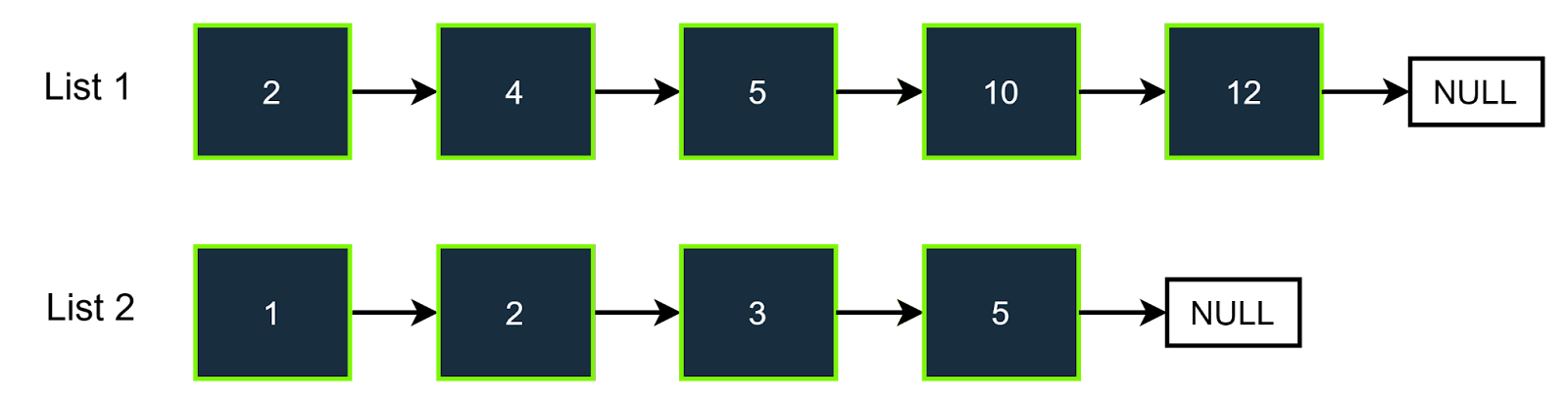
Example 1
Input
Target = 7
Output
3
Explanation
Pairs: {(2,5),(4,3),(5,2)} These are 3 pairs whose sum is equal to target = 7.
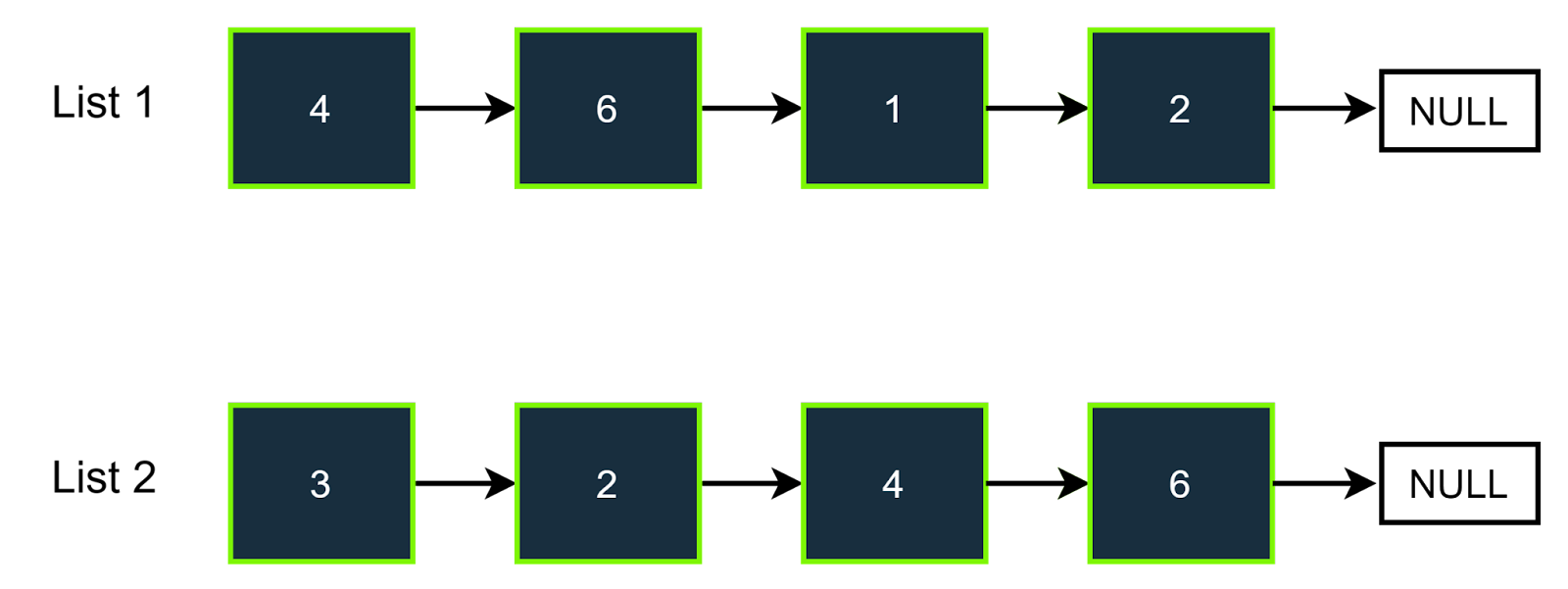
Example 2
Input
Target= 8
Output
3
Explanation
Pairs: {(6,2),(4,4),(2,6)} These are 3 pairs whose sum is equal to target = 9.
Brute Force Approach
First, look at the naive approach that would probably strike anybody’s mind before jumping to an optimal one.
So, the basic approach is to select a node in the first linked list for each selected element. We iterate over every node in the second linked list and count the pair whose sum equals the target value.
Now let’s look at the algorithm.
Algorithm
First, we will make an outer loop that traverses the first linked list and take the current node of the first linked list.
Now, in the outer loop, we will traverse the second linked list using another loop. While doing the iterations, we will check if the value of the current node of the first linked list and the current node of the second linked list equals the target value. If it is, then we will increment the count.
In the end, we will print the count.
CODE IN C++
#include <bits/stdc++.h>
using namespace std;
// Linked list node
class Node
{
public:
int value; // stores data of linked list
Node *next; // pointer for next node
Node(int data)
{ // constructor to construct new node
value = data; // with given data
next = NULL;
}
};
/* function to count pairs from two linked lists whose sum is equal to given value */
int count_pairs(Node *head1, Node *head2, int target)
{
// stores the count of pairs with given sum
int ans = 0;
// traverse the first linked list
while (head1 != NULL)
{
// select a node in first linked list
int data1 = head1->value;
Node *temp = head2;
// traverse the second linked list
while (temp != NULL)
{
int data2 = temp->value;
// check if pair has equal sum or not
if (data1 + data2 == target)
ans++;
temp = temp->next;
}
head1 = head1->next;
}
return ans;
}
int main()
{
// create first linked list with head pointer head1
Node *head1 = new Node(1);
head1->next = new Node(2);
head1->next->next = new Node(3);
head1->next->next->next = new Node(5);
// create second linked list with head pointer head2
Node *head2 = new Node(2);
head2->next = new Node(4);
head2->next->next = new Node(5);
head2->next->next->next = new Node(10);
head2->next->next->next->next = new Node(12);
// store target
int target = 7;
int ans = count_pairs(head1, head2, target);
cout << "The no of pairs is: " << ans << endl;
}
You can also try this code with Online C++ Compiler
Time Complexity: O(n*m) where n = size of first linked list and m=size of second linked list.
This is because we iterate through two nested loops. Hence it’s O(n*m).
Space Complexity: O(1) at the worst case because no extra space is used.
The above algorithm works in O(n*m) time which is pretty slow. This gives us the motivation to improve our algorithm.
So let’s think about an efficient approach to solve the problem.
Optimal Approach-1
We can improve the time complexity of the above approach; to improve the complexity, we can use a hash table to store the values in the map. Let’s look at the algorithm for a better understanding.
Algorithm
We store all elements of the first linked list in a HashSet.
Now iterate over the second linked list.
We must check whether (target - element) exists in the hash set and increase the answer accordingly for each element.
Dry Run
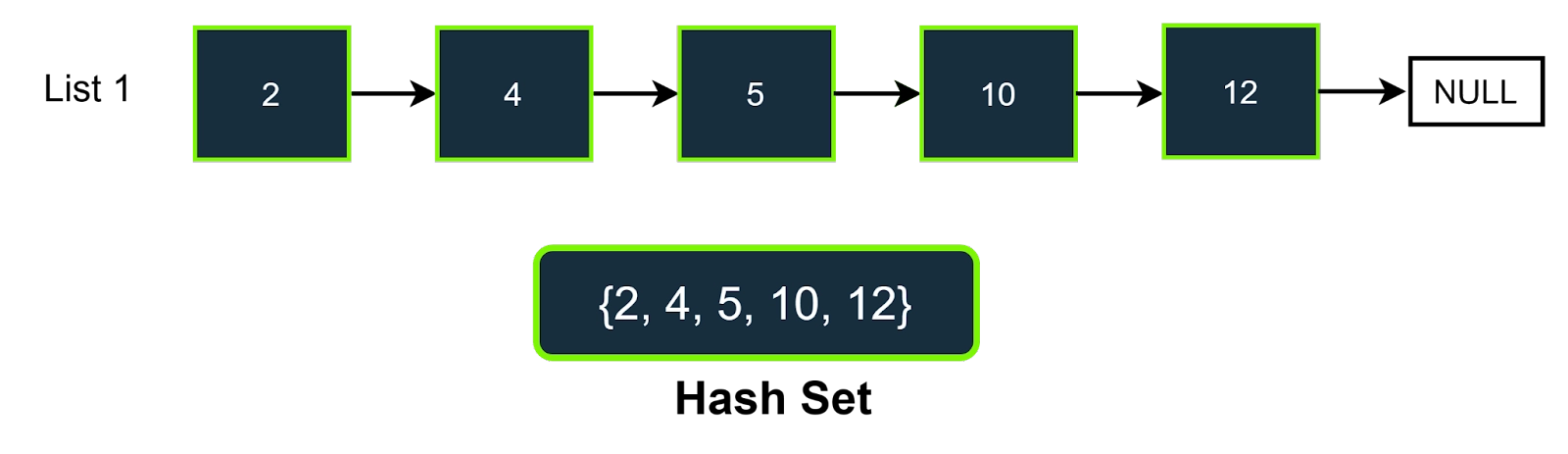
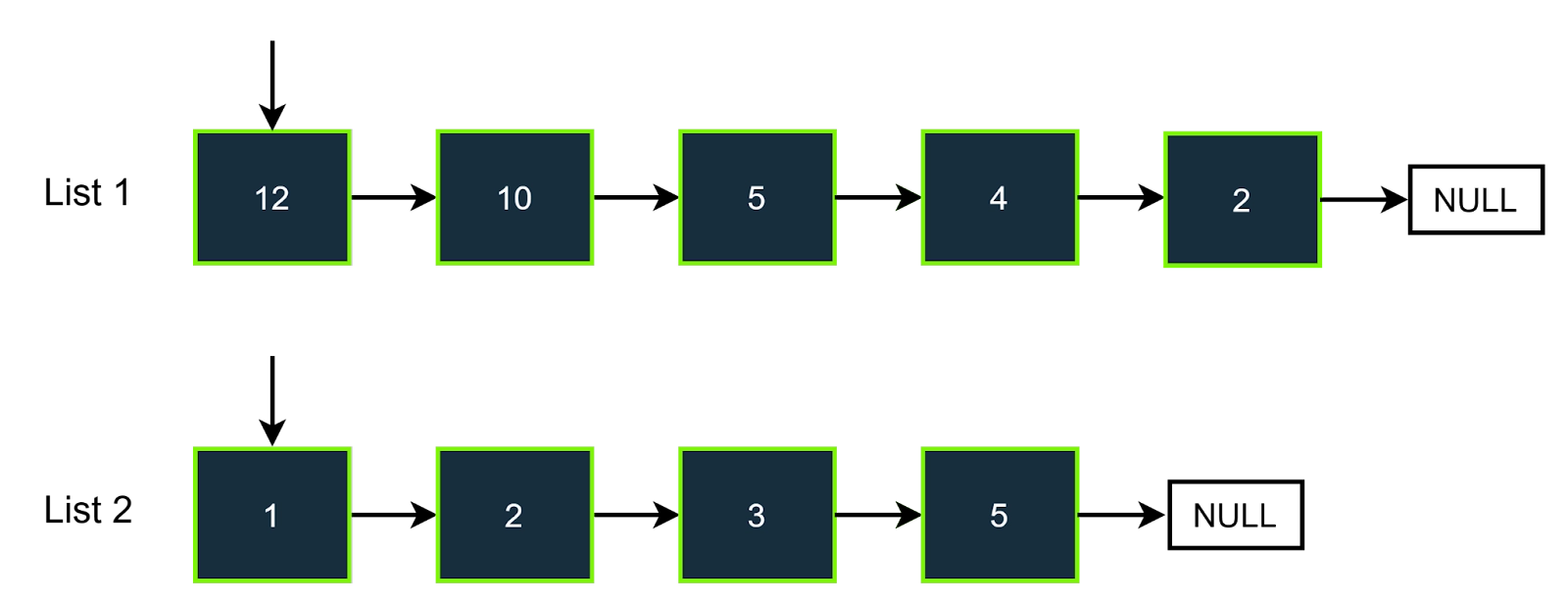
Let us consider the following example,
Here target value is 7.
Step-1
Store all the values of the first linked list in a hast set.
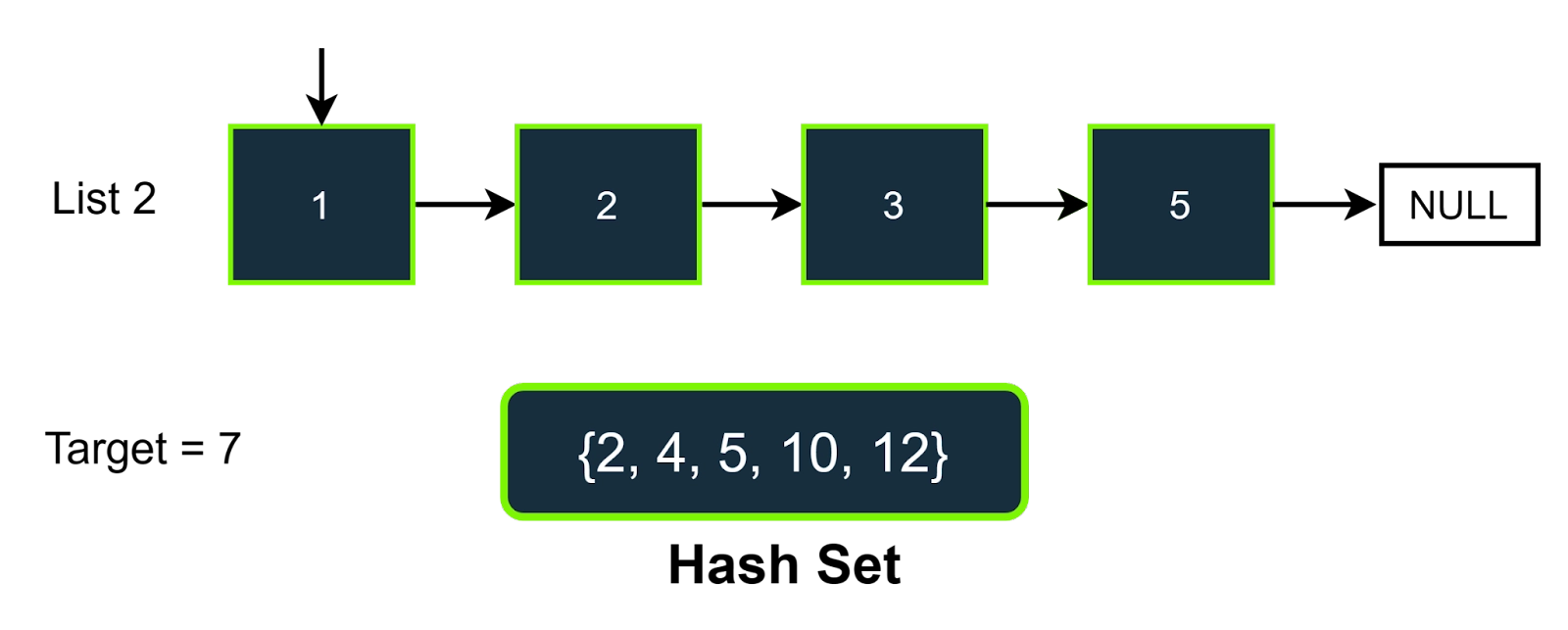
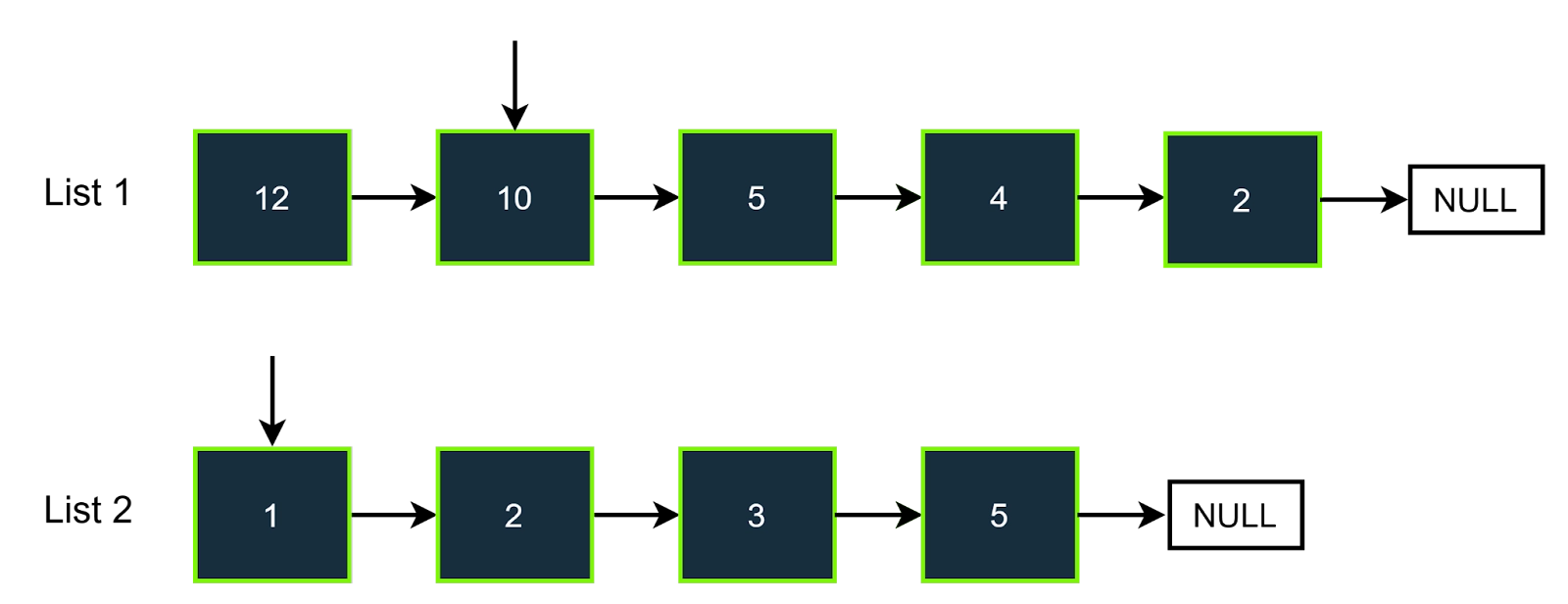
Step-2
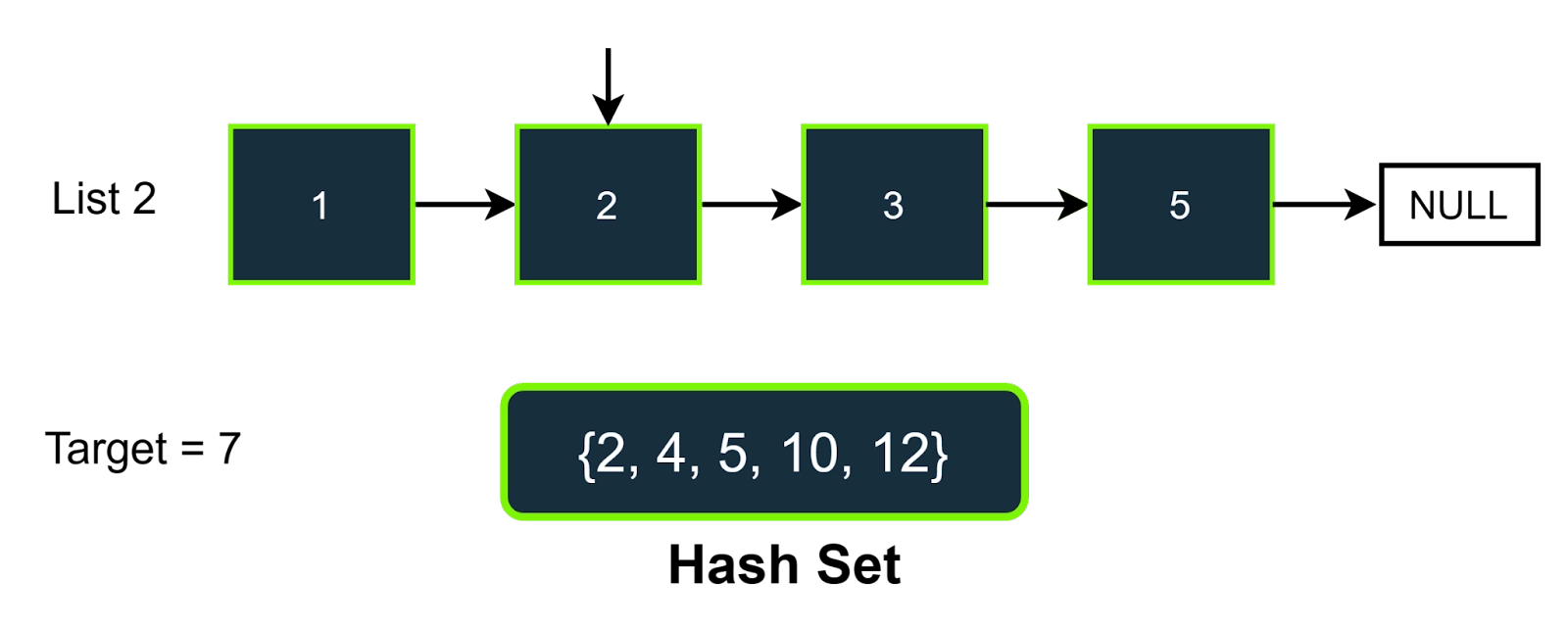
Here in this step, the first value of linked list 2 is 1; the value which we need to find in the hash set is (target-list2_value) (7-1=6), and it is not present in the hash set, so will not increment the count, we will increment the pointer of the list 2. The answer will be 0.
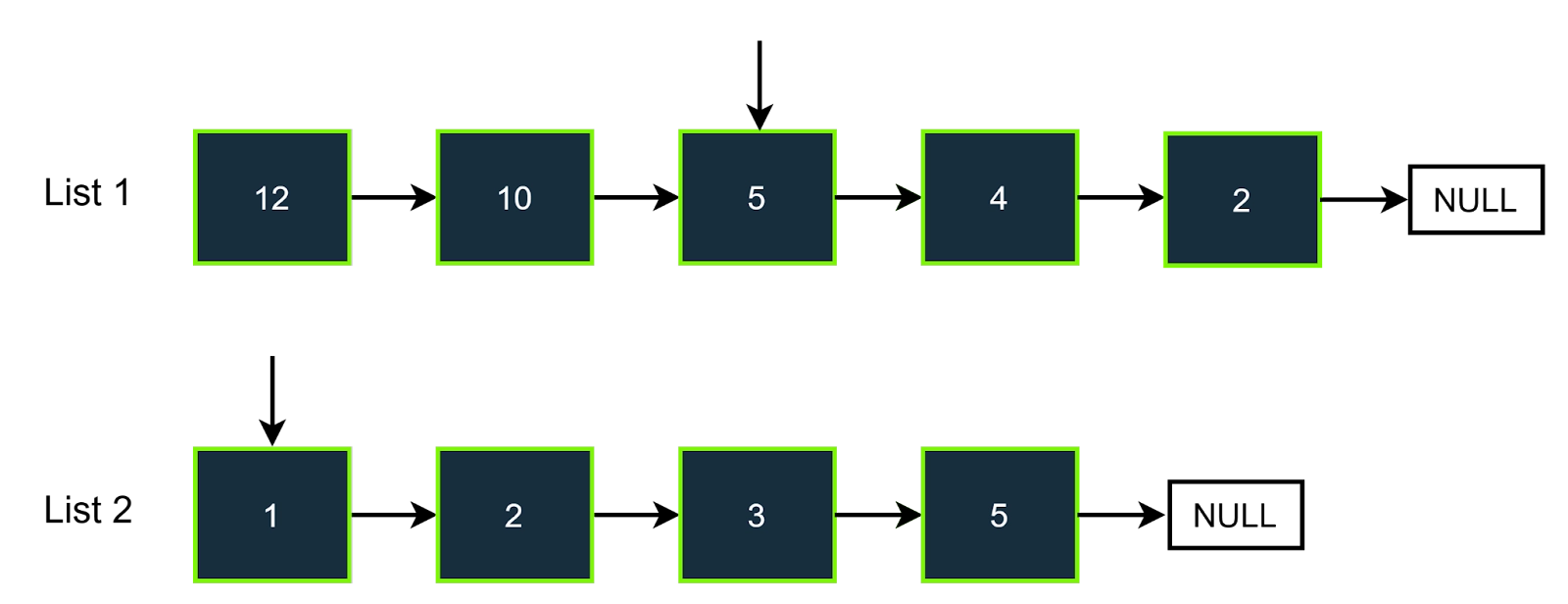
Step-3
In the third step, the value of the pointer of list2 is 2, so the value we need to find in the hash set is (7-2), i.e., 5. As we can see that 5 is present in the hast set, so we will increment the answer, and also, we will increment the pointer of the list 2. The answer will be 1.
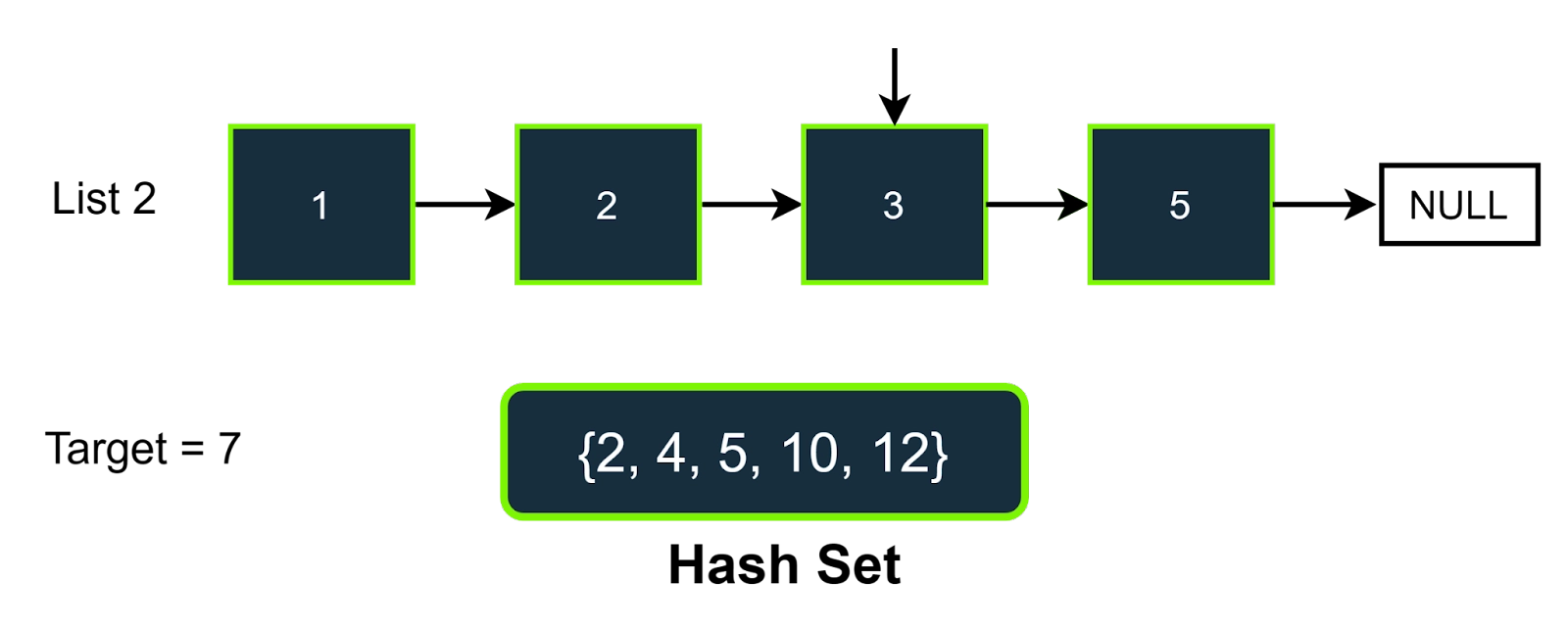
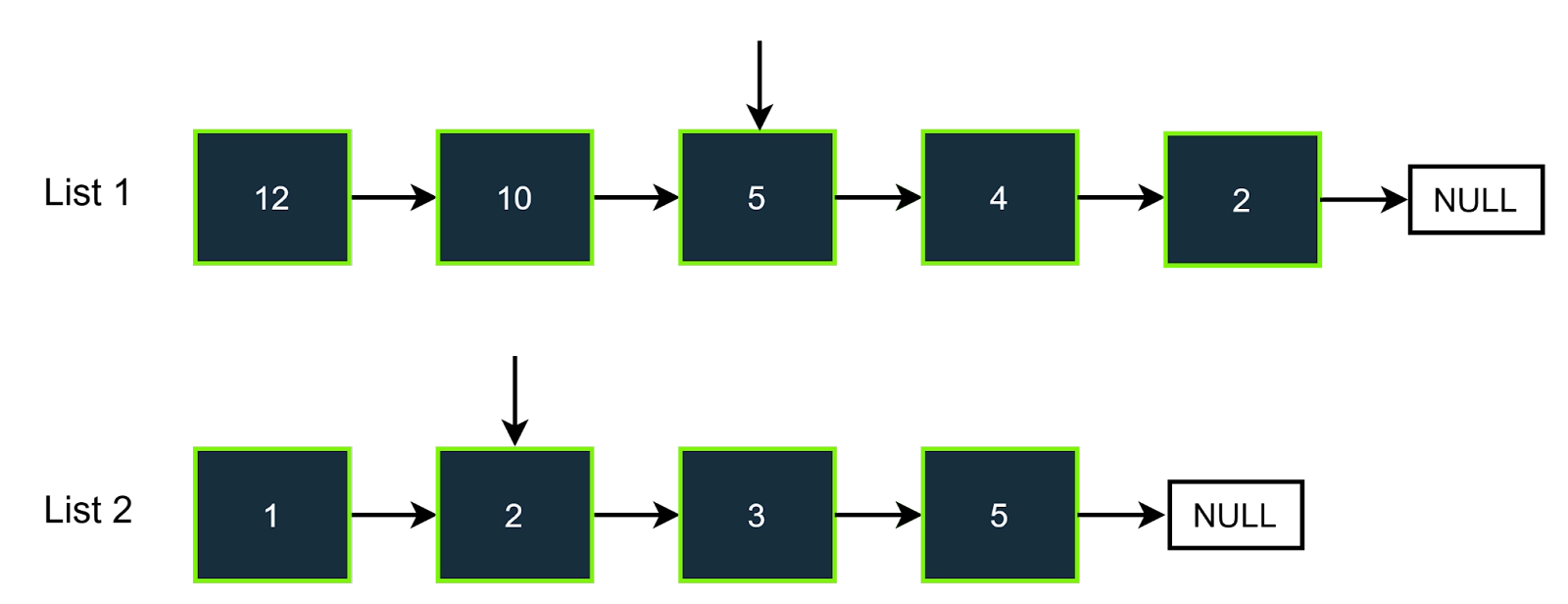
Step-4
In this step, the value of the pointer of list2 is 3, so the value we need to find in the hash set is (7-3), i.e., 4; as we can see that 4 is present in the hast set, so we will increment the answer and also we will increment the pointer of the list 2. The answer will be 2 now.
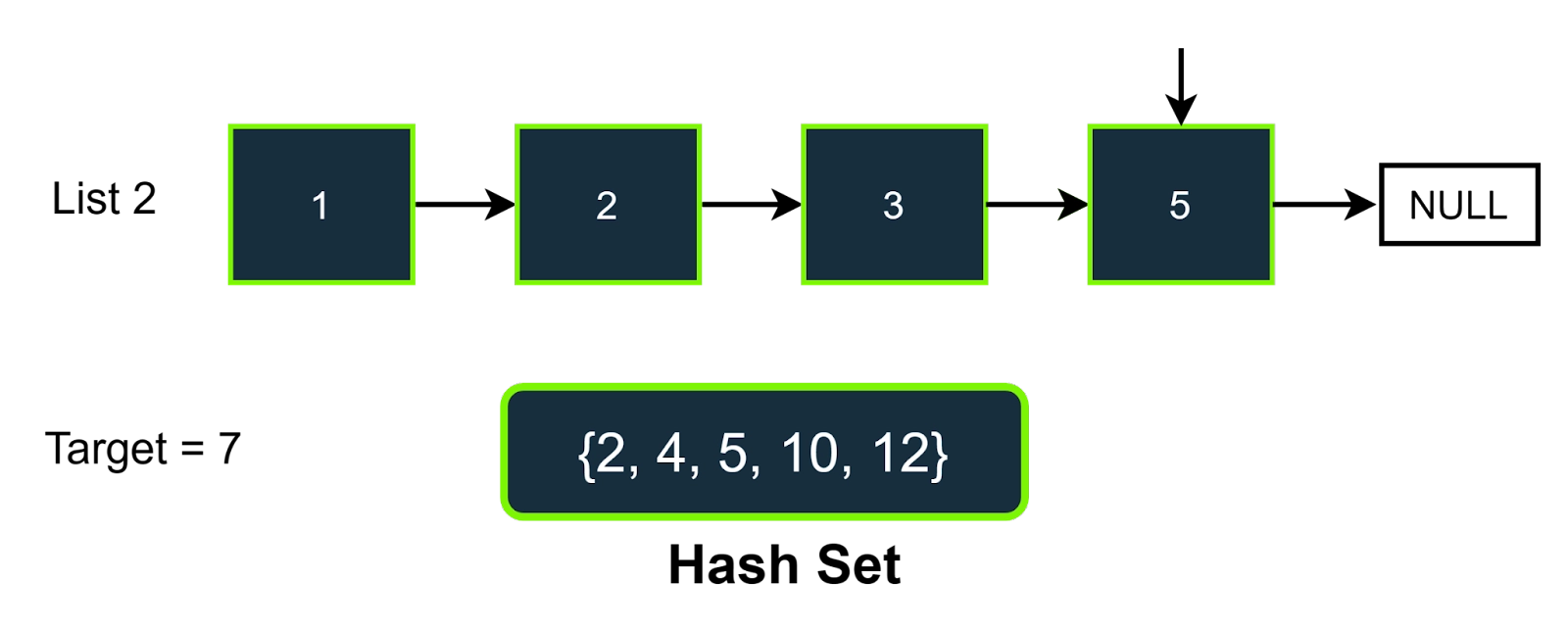
Step-5
In this step, the value of the pointer of list2 is 5, so the value we need to find in the hash set is (7-5), i.e., 2; as we can see that 2 is present in the hast set, we will increment the answer and also we will increment the pointer of the list 2.
We can see that the next node of list 2 is NULL, so we will terminate the process and print the answer, which is now 3.
CODE IN C++
#include <bits/stdc++.h>
using namespace std;
// Linked list node
class Node
{
public:
int value; // stores data of linked list
Node *next; // pointer for next node
Node(int data)
{ // constructor to construct new node
value = data; // with given data
next = NULL;
}
};
int count_pairs(Node *head1, Node *head2, int target)
{
// declaring hashset for storing elements of first linked list
unordered_set<int> hash_set;
int ans = 0;
// iterate over first list
while (head1 != NULL)
{
// store the element in list in hash
hash_set.insert(head1->value);
head1 = head1->next;
}
while (head2 != NULL)
{
int data = head2->value;
// check if target-data is present in hash set or not
if (hash_set.find(target - data) != hash_set.end())
ans++;
head2 = head2->next;
}
return ans;
}
int main()
{
// create first linked list with head pointer head1
Node *head1 = new Node(1);
head1->next = new Node(2);
head1->next->next = new Node(3);
head1->next->next->next = new Node(5);
// create second linked list with head pointer head2
Node *head2 = new Node(2);
head2->next = new Node(4);
head2->next->next = new Node(5);
head2->next->next->next = new Node(10);
head2->next->next->next->next = new Node(12);
// store target
int target = 7;
int ans = count_pairs(head1, head2, target);
cout << "The no of pairs is: " << ans << endl;
}
You can also try this code with Online C++ Compiler
Time Complexity: O(n + m) where n=size of first linked list and m=size of second linked list.
Since we traverse both lists once and access the hash table in O(1) time, the overall complexity is O(n + m).
Space complexity: O(n) as a form of storing the first list in a hash table.
Optimal Approach-2
There is another efficient approach with two-pointers without any extra space. But It works on sorted linked lists. So first, we efficiently sort the list by using merge-sort in the list.
We first sort the second linked list in increasing order and the first in descending order.
Take two pointers saying pointer1 and pointer2. Initially, pointer1 points to the starting node of the first linked list, and pointer2 points to the starting node of the second linked list.
Now iterate on both lists in the following ways:
If the pointer1-value + pointer2-value is greater than the target, we have to decrease the sum and move pointer1 by one node.
If pointer1-value + pointer2-value is less than the target, we have to increase the sum, so we have to move pointer2 by one node.
If pointer1-value + pointer2-value is equal to the target. Increase our count and move both pointer1 and pointer2 by one node.
Return our count if any pointer reaches its NULL.
Dry Run
Let us consider the following example,
Here target value is 7.
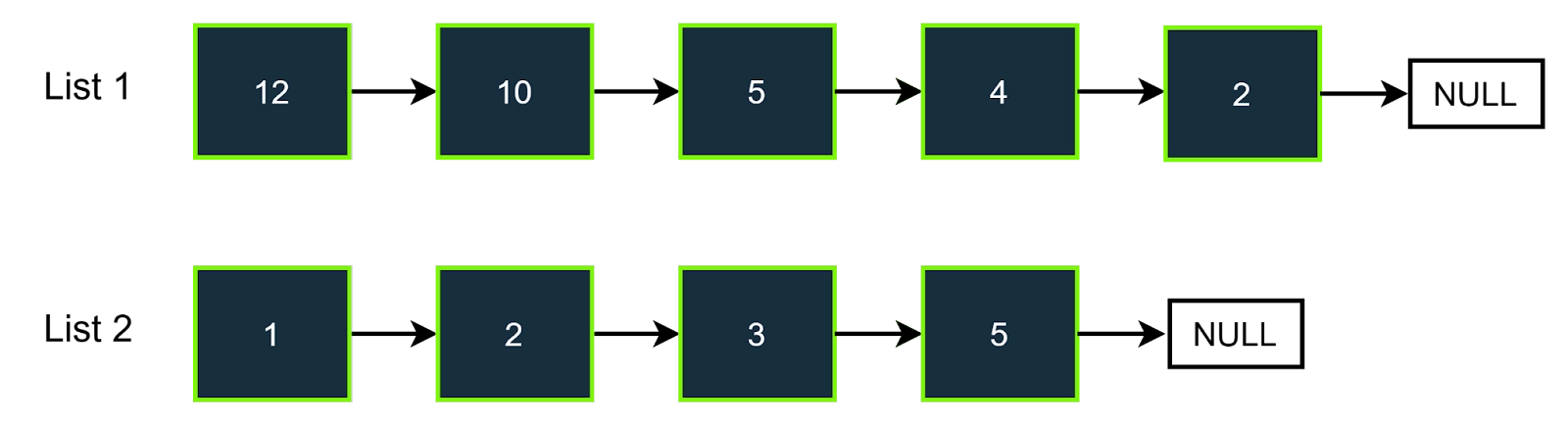
Step-1
Sort the first linked list in descending order and the other in ascending order.
Step-2
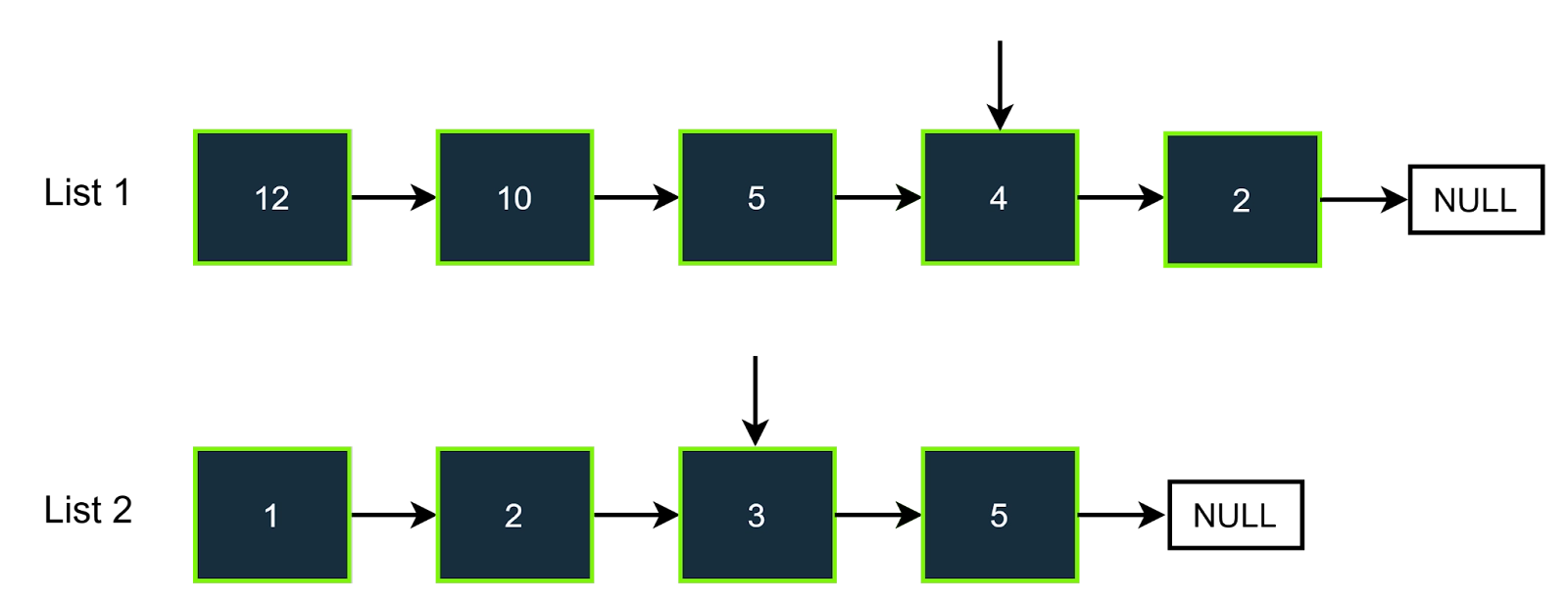
In the second step, we will initialize two different pointers. Both are at the start of the lists. Here the first pointer is pointing to 12, the second pointer is pointing to 1, and (12+1) is greater than 7(target), so we will increment the first pointer.
Step-3
Here, the first pointer points to 10, and the second pointer points to 1, so the value is again greater than 7. So again, increment the first pointer.
Step-4
Here, the value is (5+1 = 6), (5 is the value to which the first pointer is pointing, and 1 is the value to which the second pointer is pointing); here, the value 6 is less than 7, so we will increment the second pointer.
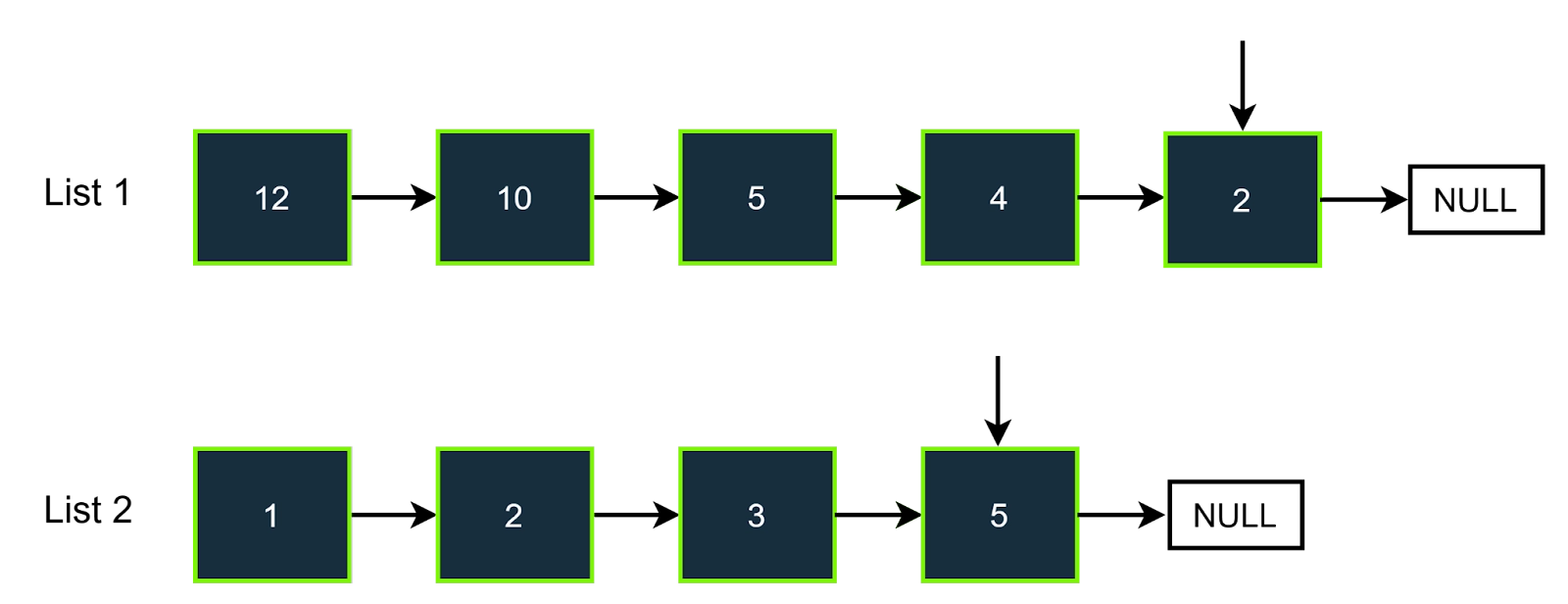
Step-5
In this step, the first pointer points to 5, and the second to 2. The value would be equal to 7 (5+2 = 7), so will increment both the pointers, and also we will increment the answer. The answer will be 1.
Step-6
Now here, both pointers will point to 4,3, respectively, so the total sum would be 7, which is equal to the target value, so we will increment both the pointers and also we will increment our answer. The answer will be 2.
Step-7
Now here, both pointers will point to 2,5, respectively, so the total sum would be 7, which is equal to the target value, so we will increment both the pointers and also we will increment our answer. The answer will be 3.
Now when we increment the pointers again, both will point to NULL. So we will terminate the process, and our answer would be 3.
CODE IN C++
#include <bits/stdc++.h>
using namespace std;
// Linked list node
class Node
{
public:
int value; // stores value of linked list
Node *next; // pointer for next node
Node(int data)
{ // constructor to construct new node
value = data; // with given value
next = NULL;
}
};
// function to merge the sorted lists
Node *merge(Node *first, Node *second)
{
Node *mergeList = NULL, *cur = NULL;
while (first != NULL && second != NULL)
{
// if value of node in first list is less than the value of node in second list
if (first->value < second->value)
{
// add the node of first linked list
if (mergeList == NULL)
{
mergeList = first;
cur = first;
}
else
{
cur->next = first;
cur = cur->next;
}
// move pointer of first linked list ahead
first = first->next;
}
// if value of node in first list is greater than the value of node in second list
else
{
// add the node of second linked list
if (mergeList == NULL)
{
mergeList = second;
cur = second;
}
else
{
cur->next = second;
cur = cur->next;
}
// move pointer of first linked list ahead
second = second->next;
}
}
// if any list is left then add it in the merged list
if (first != NULL)
{
cur->next = first;
}
if (second != NULL)
{
cur->next = second;
}
return mergeList;
}
// function to sort linked list
Node *sortLL(Node *head)
{
if (head == NULL || head->next == NULL)
{
return head;
}
// dividing list into two sublists
Node *mid = head, *tail = head, *prev;
while (tail != NULL && tail->next != NULL)
{
prev = mid;
mid = mid->next;
tail = tail->next->next;
}
prev->next = NULL;
Node *first = head;
Node *second = mid;
// calling the recursive function on sublists
first = sortLL(first);
second = sortLL(second);
head = merge(first, second);
return head;
}
// function to reverse linked list
Node *reverse(Node *head)
{
Node *temp = head;
Node *prev = NULL;
while (temp)
{
head = head->next;
temp->next = prev;
prev = temp;
temp = head;
}
return prev;
}
int count_pairs(Node *head1, Node *head2, int target)
{
// intialise both pointer with thier starting node.
Node *pointer1 = head1;
Node *pointer2 = head2;
int ans = 0;
while (pointer1 != NULL && pointer2 != NULL)
{
int value1 = pointer1->value;
int value2 = pointer2->value;
if (value1 + value2 > target)
pointer2 = pointer2->next;
else if (value1 + value2 < target)
pointer1 = pointer1->next;
else
{
ans++;
pointer2 = pointer2->next;
pointer1 = pointer1->next;
}
}
return ans;
}
int main()
{
// create first linked list with head pointer head1
Node *head1 = new Node(2);
head1->next = new Node(3);
head1->next->next = new Node(1);
head1->next->next->next = new Node(5);
// sort linked list using merge sort
head1 = sortLL(head1);
// create second linked list with head pointer head2
Node *head2 = new Node(10);
head2->next = new Node(5);
head2->next->next = new Node(12);
head2->next->next->next = new Node(4);
head2->next->next->next->next = new Node(2);
// sort linked list using merge sort
head2 = sortLL(head2);
// reverse the second linked list so that it is sorted in descending order
head2 = reverse(head2);
// store target
int target = 7;
int ans = count_pairs(head1, head2, target);
cout << "The no of pairs is: " << ans << endl;
}
You can also try this code with Online C++ Compiler
Linked lists offer several advantages such as dynamic size, efficient insertion and deletion, and efficient memory utilization. They can easily grow or shrink in size, insert or delete elements in constant time, and use memory efficiently by only allocating memory for the actual elements.
How does merge sort for linked list work?
The merge sort algorithm utilizes a divide-and-conquer strategy by dividing the list into smaller sub-lists with one already sorted element each. By taking advantage of this characteristic, the algorithm can merge two already sorted sub-lists into a bigger, sorted list.
Is it possible to implement the two-pointer approach without having to sort the lists beforehand?
It is not feasible to do so because in an unsorted list, it's not possible to determine whether the next element is greater or less than the current element. As a result, we can't move our pointer to increment or decrement the sum.
What is the time complexity of searching for an element in a linked list?
The time complexity of searching for an element in a linked list is O(n), where n is the number of nodes.
What is the time complexity of deleting an element from a linked list?
The time complexity of deleting an element from a linked list is O(1), assuming you have a reference to the node before the node is deleted.
Conclusion
This article taught us how to solve the data structure problem, i.e., count pairs from two linked lists whose sum equals a given value. We also saw how to approach the problem using a naive approach followed by two efficient solutions. We discussed an iterative implementation and some basic traversal in linked lists using examples, pseudocode, and code in detail.
Now, we recommend you solve some problems based on the concepts of this problem—another similar problem is the Number of pairs with a given sum.
I hope this blog has helped you enhance your knowledge regarding the above Data Structures and Algorithms problem, and if you want to learn more, check out our articles on Coding Ninjas Studio. Enroll in our courses, refer to the test seriesand problemsavailable, and look at theinterview bundlefor placement preparations.
Nevertheless, you may consider our paidcoursesto give your career an edge over others!
Do upvote our blogs if you find them helpful and engaging!































 9+ registered
9+ registered 

