


























Introduction
Problem statement
We are given an array having n elements. Our task is to count the number of inversions in the given array.
Count of inversions in an array means how far or close the given array is from being sorted. In other words, a[i] and a[j] are the two elements from the given array, they form an inversion if a[i] > a[j] and i < j
If the array is already sorted, its inversion count is 0, but if the array is reversed sorted, its count is maximum.
Sample Examples
Example 1:
Input: a[]={6, 3, 2}
Output: 3
Explanation
Inversions are: (6, 3), (6, 2), (3, 2)
Example 2:
Input: a[]={7, 5, 9, 3, 4}
Output: 7
Explanation
Inversions are: (7, 5), (7, 3), (7, 4), (5, 3), (5, 4) (9, 3) (9, 4) Approach
In the merge sort algorithm, we divide the given array into two halves (left half, right half) and sort both the halves using recursion. After that, we merge both the sorted halves to get our final sorted array.
In this approach, we will use the idea of merge sort to count the number of inversions in the given array efficiently.
Divide the array into two halves, and let’s suppose the count of inversions in the left and right halves are inv_1 and inv_2, respectively.
The total count of inversions in the given array will be the sum of inv_1, inv_2 and inversions in the merge step.
Count of inversions in the merge step:
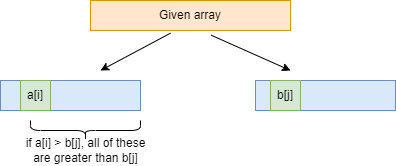
Let's suppose i is used to index the left half and j is used to index the right half of the given array in the merge process. So, if a[i] is greater than b[j] at any point in merge(), there are (half – i) inversions. Because the left and right subarrays are sorted, the remaining elements in the left half (a[i+1], a[i+2],... a[half]) will all be greater than b[j].
Let’s understand the above with a diagram:
Also see, Euclid GCD Algorithm
Steps of Algorithm
- Divide the given array into two equal or almost equal halves in each step until the base case is reached.
- Create a merge_inv function that counts the number of inversions when the left and right halves are merged. if a[i] is greater than b[j] at any point in merge(), there are (half – i) inversions. Because the left and right subarrays are sorted, the remaining elements in the left half (a[i+1], a[i+2],... a[half]) will all be greater than b[j].
- Create a recursive function to split the array in half and find the answer by adding the number of inversions in the first half, the number of inversions in the second half, and the number of inversions by merging the two halves.
- The base case is when there is only one element in the given subarray.
- Print the result.
Implementation in C++
#include <bits/stdc++.h>
using namespace std;
int mergesort_inv(int a[], int tmp[], int l, int r);
int merge_inv(int a[], int tmp[], int l, int half, int r);
// sorts nd returns the inversions
int mergeSort(int a[], int n)
{
int tmp[n];
return mergesort_inv(a, tmp, 0, n - 1);
}
int mergesort_inv(int a[], int tmp[], int l, int r) // merges and returns the inversions
{
int half, inv_cnt = 0;
if (r > l)
{
half = (r + l) / 2;
/*divide and call mergesort_inv function for both the parts*/
inv_cnt = inv_cnt + mergesort_inv(a, tmp, l, half);
inv_cnt = inv_cnt + mergesort_inv(a, tmp, half + 1, r);
// merge the two parts
inv_cnt += merge_inv(a, tmp, l, half + 1, r);
}
return inv_cnt;
}
// merge and return the inversions
int merge_inv(int a[], int tmp[], int l, int half, int r)
{
int i, j, k;
int inv_cnt = 0;
i = l; // index for left subarray
j = half; // index for right subarray
k = l; // index for resultant merged subarray
while ((i <= half - 1) && (j <= r))
{
if (a[i] <= a[j])
{
tmp[k] = a[i];
i++;
k++;
}
else
{
tmp[k] = a[j];
k++;
j++;
inv_cnt = inv_cnt + (half - i); // merge inversion count
}
}
/*Copy the remaining elements of the left
subarray (if there are any) to temp*/
while (i <= half - 1)
{
tmp[k] = a[i];
k++;
i++;
}
/*Copy the remaining elements of the right
subarray (if there are any) to temp*/
while (j <= r)
{
tmp[k] = a[j];
k++;
j++;
}
/*Copy back the merged elements to the
original array*/
for (i = l; i <= r; i++)
a[i] = tmp[i];
return inv_cnt;
}
int main()
{
int a[] = { 7, 5, 9, 3, 4 };
int n = sizeof(a) / sizeof(a[0]);
int res = mergeSort(a, n);
cout << "Inversions: " << res;
return 0;
}
Output:
Inversions: 7
Complexity Analysis
Time complexity: O(N*logN)
We are using a divide and conquer algorithm; at each level, one complete traversal of the given array is needed, and there are logn levels, so the time complexity is O(N*logN)
Space complexity: O(N), as we are using a temporary array (tmp).
Check out this problem - Count Inversions


 9+ registered
9+ registered 

