



























Introduction
Cloud Spanner is a fully managed relational database service that offers transactional consistency at a global scale. It provides automatic and synchronous replication for high availability and support for two SQL dialects: Google Standard SQL and PostgreSQL. It combines transactions, SQL queries, and relational structures with the scalability to associate with non-relational or NoSQL databases. Creating and Managing instances in Cloud Spanner is a crucial step as instances are responsible for allocating resources used by the databases. Each Cloud Spanner instance can have multiple databases. Cloud Spanner also provides options to backup and restore databases on demand.
Working with Instances
Spanner is a fully managed service that can oversee its underlying tasks and resources, including monitoring and restarting processes with zero downtime. Spanner does not allow manually stopping or restarting a given instance. Instance creation includes an instance configuration and the compute capacity. These determine the location and amount of storage resources for the instance.
An instance configuration defines the geographic placement/region and replication of the databases in that instance. It can be configured to either regional or multi-region.
Compute capacity determines the amount of server and storage resources available to the databases in an instance. The compute capacity is specified in terms of processing units or nodes, with 1000 processing units equal to 1 node.
Nodes and Processing units
Instances with less than 1000 processing units are built for smaller data sizes, queries, and workloads. They have limited resources and may result in non-linear scaling and performance for some workloads with increased latencies. For such instances, Cloud Spanner allocates 409.6 GB of data for every 100 processing units in the database. It also allocates server resources in a single server task per zone.
For instances of 1 node or more, Cloud Spanner assigns 4 TB of data for each node. It allocates server resources in multiple server tasks per zone, with one task for each 1000 processing units. It uses numerous server tasks per zone, unlike instances with less than 1000 processing units. This provides better performance and enables Cloud Spanner to create database splits.
Regional and Multi-regional Configurations
All the resources are contained within one Google Cloud region in regional configurations. In multi-regional configurations, the resources span more than one region. This setting determines where the data is stored, for an instance. Google Cloud services are available across North America, South America, Europe, Asia, and Australia.
For all regional configurations, Cloud Spanner maintains three read-write replicas within a different Google Cloud zone in that region. Each read-write replica contains a full copy of the operational database to serve read-write and read-only requests.
If an application needs to read data from multiple geographic locations or if writes originate from a different location than the reads, then a multi-regional configuration might be a better choice. This configuration allows users to replicate the database's data in multiple zones, even across numerous regions, as defined by the instance configuration. Multi-region configurations enable applications to achieve faster reads in more places at the cost of a slight increase in write latency.
Replication
Cloud Spanner uses replicas in different zones to keep up availability even when a single-zone failure occurs. Cloud Spanner automatically performs replication at the byte level from the underlying distributed filesystem. It writes the database mutations to files in this filesystem, which takes care of replicating and recovering the files during a machine or disk failure.
Cloud Spanner creates replicas of each database split, and all of its data is physically stored together in the replica.
The benefits of Replications are high data availability across different regions and continents. It delivers a single database experience and has a firm consistency. This makes application development and maintenance faster and easier.
Types
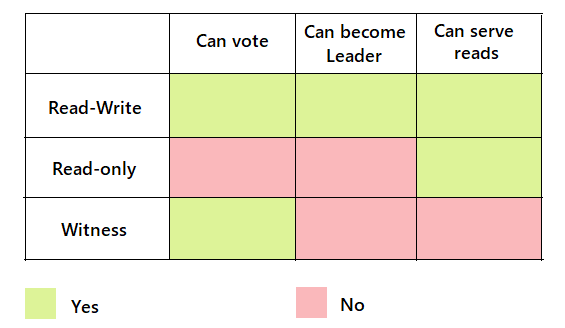
Cloud Spanner has three replicas: read-write, read-only, and witness replicas. Single-region instances use only read-write replicas, while multi-region use a combination of all three types.
-
Read-write replicas support reads and writes. They maintain a full copy of the data and are used in single-region instances.
-
Read-only replicas support only reads and are used in multi-region instances. They maintain a full copy of the data replicated from read-write replicas.
- Witness replicas do not maintain a full copy of the data and are used only in multi-region instances. They do not support reads.
Create and Manage Instances
Users can create instances using the Google Console or the Cloud CLI.
Step 1: Go to Create an Instance on the Console.
Step 2: Enter the instance name, instance ID, configuration and compute capacity for the instance you want to create.
Step 3: Click on Create.
Options to Edit, List, and Delete are available on the Spanner Instances Page in the Console.



 9+ registered
9+ registered 

