CYK Algorithm
CYK, known as Cocke-Kasami-Youngerknown, is one of the oldest parsing algorithms. The standard version of CKY recognizes only languages defined by context-free grammars in CNF. It is also possible to excel the CKY algorithm to handle some grammars which are harder to understand. It builds solutions compositionally from sub-solutions based on a dynamic programming approach. It Uses the grammar directly.
CYK considers every possible consecutive subsequence of letters. If the generation of a sequence of letters starting from 'i' to j is possible from the nonterminal K, It sets K ∈ T[i,j]. after considering the length 1, it goes on to lines of length 2, and so on. For subsequences of length two and more, it thinks of every possible partition of the subsequence into two halves and checks if there is some production A BC such that B matches the first half and C matches the second half. If so, it records A as corresponding to the whole subsequence. After completing this process, the grammar recognizes the sentence if the start symbol matches the entire string.
We can split any portion of the input string spanning 'i' to 'j' at k. We can build the structure using sub-solutions travelling 'i' to k and sub-solutions spanning k to j. This means we can construct a solution to the problem [i, j] from solution to sub-problem [i, k] and solution to subproblem [k,j].
- Let N be the number of words in the input. Think about n+1 lines separating them, numbered 0 to n.
- X ij will denote the words between lines i and j.
- We build a table so that Xij contains all the possible not terminal spanning for words between line i and j.
- We build the table bottom-up.
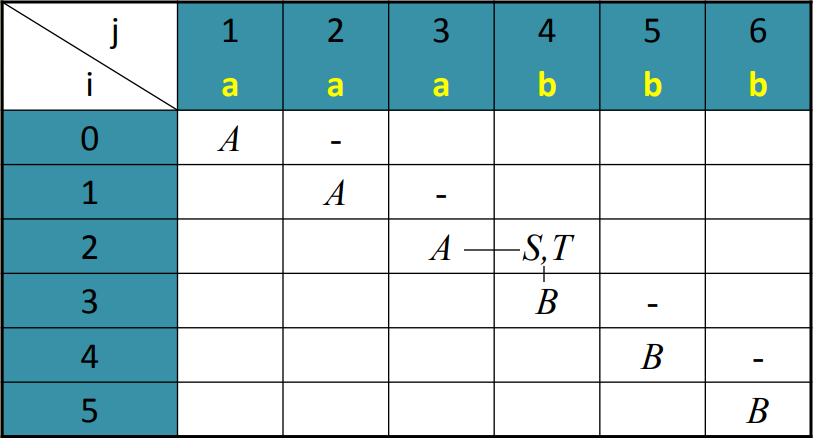
Example Using Dynamic Programming
Example- Write variables for all length two substrings.
S → e | AB | XB
T → AB | XB
X → AT
A → a
B → b
Function CKY (word w, grammar P) returns table
for i ← from 1 to LENGTH(w)
do table[i-1, i] ← {A | A wi ∈ P }
for j ← from 2 to LENGTH(w) do
for i ← from j-2 down to 0 do
for k ← i + 1 to j – 1 do
table[i,j] ← table[i,j] ∪ {A | A → BC ∈ P, B ∈ table[i,k], C ∈ table[k,j] } If the start symbol S ∈ table[0,n] then w ∈ L(G)
source
FAQs
1. What is Syntactic Parsing used for?
In Syntactic parsing, we use rules to parse the sentence in sub-phrases.
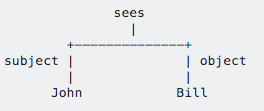
2. What is Dependency Parsing used for?
Dependency parsing aims at breaking a sentence depending on the relationship between the words rather than any predefined ruleset.
3. What is Semantic Parsing used for?
Semantic parsing aims at transforming a sentence into a logical, formal representation.
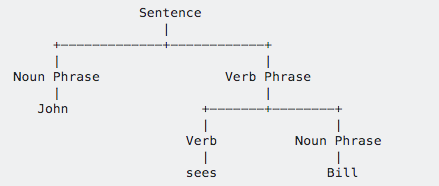
4. Define Parsing Tree?
A parse tree converts the sentence into a tree-like structure. The leaf of the parse tree holds POS tags that correspond to words in the sentence. The rest of the tree tells us how these words merge to form the entire sentence.
5. What is the CYK algorithm?
CYK, known as Cocke-Kasami-Youngerknown, is one of the oldest parsing algorithms. It builds solutions compositionally from sub-solutions based on a dynamic programming approach. It uses grammar directly.
Key Takeaways
We came to the end of the discussion. Like the CYK algorithm, many parsing algorithms are used in a context-free grammar. Parsing algorithms are the subset of Natural Language Processing and come under Machine Learning. Check here for more NLP algorithms.





























 9+ registered
9+ registered 
