Get a skill gap analysis, personalised roadmap, and AI-powered resume optimisation.
Introduction
The primary goal of data abstraction is to simplify the user's interaction with data by hiding unnecessary details. It allows developers to present only relevant information to users, enhancing ease of access and system efficiency.
So let's start the journey to learn more about Data Abstraction in DBMS.
What is Data Abstraction DBMS?
Data abstractions in DBMS refer to the hiding of unnecessary data from the end-user. Database systems have complex Data Structures and relationships. These difficulties are masked so that users may readily access the data, and just the relevant section of the database is made accessible to them through data abstraction. Let's understand this more with an example.
Example of Data Abstraction
Our dependency on email communication in the modern day is apparent. However, data location and storage specifics are frequently hidden from us. Regardless of their physical storage or data type, reading and managing our emails is our top priority while using Gmail.
If we want to retrieve any email from Gmail, we don't know where that data is physically kept, such as in India or the United States, or what data model was utilized to store it. These things are not essential to us. Only our email is of interest to us.
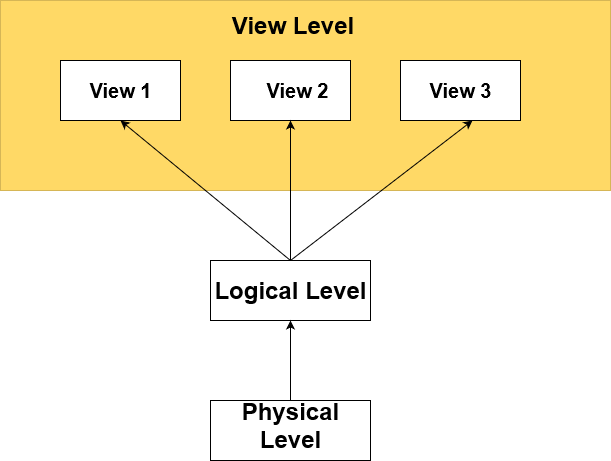
Database Management Systems (DBMS) are essential to effectively managing and organizing data in data management. Three interrelated levels of abstraction, each performing a different function, make up the hierarchical framework through which these systems operate.
There are three levels of abstraction for DBMS are:
External Level / View Level
Conceptual Level/ Logical Level
View or External Level
Now let's look at the levels of data abstractions in DBMS and discuss them in detail.
1. Physical or Internal Level
It is the lowest level of abstraction for DBMSs, defining how data is stored, data structures for storing data, and database access mechanisms.
Developers or database application programmers decide how to store data in the database. It is complex to understand.
Example
The physical level, being the lowest level of abstraction, can be understood with an example, like how information about a customer is stored in tables while the data is stored in the form of blocks.
Another example of physical-level abstraction would be sequential file organization due to the continuous storage of records. While in indexed file organizations, we can access the records with the help of indexes.
2. Logical or Conceptual Level
The logical level is the next higher level or intermediate level. It explains what data is stored in the database and how those data are related. It seeks to explain the complete or entire data by describing what tables should be constructed and what the linkages between those tables should be. It is less complex than the physical level.
Example
The logical level in DBMS is used for representing entities and relationships among the data stored. For example, defining tables and their attributes and specifying relationships between them. A table named ‘class’ may have different attributes like student_name, Roll_no, student ID, and Marks.
A table named ‘IDs’ contains details about the address of the teacher's ID (foreign key), and student ID (foreign key).
3. View or External Level
This is the top level. There are various views at the view level, with each view defining only a portion of the total data. It also facilitates user engagement by providing a variety of views or numerous views of a single database. All users have access to the view level. This is the easiest and most simple level.
Example
The external level in DBMS defines a part of the entire data and simplifies interaction with the user by providing multiple views of a similar database. For example, interacting with a system using a graphical user interface (GUI) to access an application's features. Here GUI is the view level, and the user does not know how and what data is exactly stored, i.e hiding the details from the user.
The primary goal of data abstractions in DBMS is to obtain data independence in order to save time and money when modifying or altering a database.
Data independence is known as the ability to change the scheme without impacting the programmes and applications to be rewritten. Data is isolated from programmes so that changes to the data do not influence the program's or application's execution.
Types of Data Independence
Data Independence is mainly of two types :
1. Physical level independence
It refers to the ability to change the physical schema without changing the conceptual or logical schema, which is done for optimization purposes.
2. Logical level independence
This feature is referred to as the ability to change the logical schema without changing the external schema or application program.
Any modifications to the conceptual representation of the data would not affect the user's perception of the data.
What Are the Benefits of Data Abstraction?
Simplified User Interaction – Users can interact with the database without worrying about the complexities of data storage and management.
Improved Security – Sensitive data is hidden from users, ensuring that only relevant information is accessible based on their privileges.
Reduced Complexity – Data abstraction allows users to focus on high-level operations while the underlying details are managed by the DBMS.
Increased Flexibility – Changes to the data storage structure do not affect how users interact with the data, making the system more adaptable.
Enhanced Data Integrity – By abstracting the details of data storage, the DBMS ensures that data is stored consistently and correctly without direct manipulation by users.
Advantages of Data Abstraction in DBMS
It reduces the complexity for the users.
While retrieval of data abstractions in DBMS makes the system efficient.
Increases the usability of the users.
Increases the security aspect of the application as implementation details are hidden from the users.
Increases the code duplicity and reusability.
Disadvantages of Data Abstraction in DBMS
Some of the disadvantages of data abstraction are mentioned below.
Data abstraction might b confusing for developers as there are complexities at multiple levels of the database.
Whenever the extra layer is added to the code, navigation becomes challenging.
At lower levels changing the behavior of DBMS might prove to be a challenging task or might even be impossible because of abstraction.
Frequently Asked Questions
What are the 3 levels of data abstraction?
There are three levels of abstraction :
Internal Level / Physical Level: It defines how the data is actually stored employing various data structures.
Conceptual Level/ Logical Level: It describes the relationship which exists among the stored data.
Internal Level / Physical Level: It provides a high-level view of a section of data.
What is data abstraction in DBMS example?
Data abstractions in DBMS refer to hiding unnecessary data from the end-user. Example: If we want to retrieve any email from Gmail, we don't know where that data is physically kept, such as in India or the United States, or what data model was utilized to store it. These things are not essential to us. Only our email is of interest to us.
Why is data abstraction important?
Data abstraction is crucial in DBMS because it shields users and applications from the complexities of the underlying database structure. It provides a simplified, high-level view of data, enhancing data security, privacy, and reducing the risk of errors.
What is the main use of abstraction?
The main use of abstraction is to create a clear separation between what something does and how it does it. It allows developers to work with high-level concepts and models, making software design and development more efficient and comprehensible.
What are the five stages of abstraction?
Functional Purpose (FP), Abstract Function (AFn), Gen- eralized Function (GFn), Physical Function (PFn), and Physical Form (PFm), shifting from a high-level purpose statement down to a detailed physical description of a system's components.
What are the different views of data in DBMS?
In a DBMS, the different views of data are the internal view, dealing with physical storage; the conceptual view, describing the logical structure and relationships; and the external view, providing customized data access for individual users or groups.
Conclusion
This blog has extensively discussed Data Abstractions in DBMS, levels of abstraction, and data independence. We hope that this blog has helped you learn more about Data abstractions in DBMS in depth.






























 9+ registered
9+ registered 

