Get a skill gap analysis, personalised roadmap, and AI-powered resume optimisation.
Introduction
In Database Management Systems (DBMS), data integrity constraints are a set of rules applied to table columns or relationships to ensure the overall validity, Integrity, and consistency (i.e., the quality) of the data in the database.
In this article, we will see an introduction to data integrity Constraints and learn about the types of Integrity Constraints and examples in depth.
Data integrity means having correct and accurate data in the Database. In simple words, if you are storing the data in the database, you want your data not to be repetitive and incorrect. So data integrity helps you to prevent any broken relationships between tables.
Data Integrity Types
In the below section we will explain how to apply rules to table columns to enforce various types of data integrity.
🔺Null Rule
A null rule is a rule that is specified on a single column that permits or disallows inserts or updates to rows that include a null (the absence of a value) in that column.
🔺Unique Column Values
A unique value rule defined on a column (or combination of columns) allows the insert or update of a row only if that column contains a unique value (or set of columns).
🔺Primary Key Values
A primary key value rule defined on a key (a column or combination of columns) indicates that the values in the key can uniquely identify each row in the table.
🔺Referential Integrity rules
A referential integrity rule is a rule that is applied to a key (a column or combination of columns) in one table, confirming that the values in that key match the values in a related table's key.
Referential integrity rules also govern what types of data modification are permitted on referenced values and how these activities affect dependent values. The rules governing referential integrity are as follows:
▶️Restricts: Restricts the update or deletion of referenced data.
▶️Set to Null: When referenced data is modified or destroyed, all dependant data associated with it is set to NULL.
▶️Set to Default: When referenced data is changed or removed, all dependent data is reset to the default value.
▶️Cascade: When referenced data is updated, all associated dependant data is updated as well. When a referred row is deleted, all dependant rows that are linked to it are also deleted.
▶️No Action: Prevents updating or deleting relevant data. This differs from RESTRICT because it is tested at the end of the statement.
🔺Complex Integrity Checking
Complex integrity checking is a user-defined rule for a column that allows or disallows inserts, changes, or deletions of a row based on the column value.
Data integrity constraints can be defined as updating the data security to keep and secure the quality of the data.
🔻Data Integrity Constraints ensure that data insertion, updating, and other activities in a way that does not compromise data integrity.
🔻As a result, the integrity constraints protect the database against sudden damage.
Advantages of integrity constraints
▶️Declarative ease
You don't need to do any additional programming when you define or alter the table.
▶️Centralized rules
All programs must adhere to the same integrity restrictions while entering the data. If the rules at the table level change, then applications do not need to update. Additionally, apps can employ a data dictionary to quickly notify users about violations, even before the database checks the SQL statement.
▶️Flexibility when loading data
You can temporarily disable integrity restrictions to save performance overhead while transferring large amounts of data. When the data loading is about to finish, re-enable the integrity constraints.
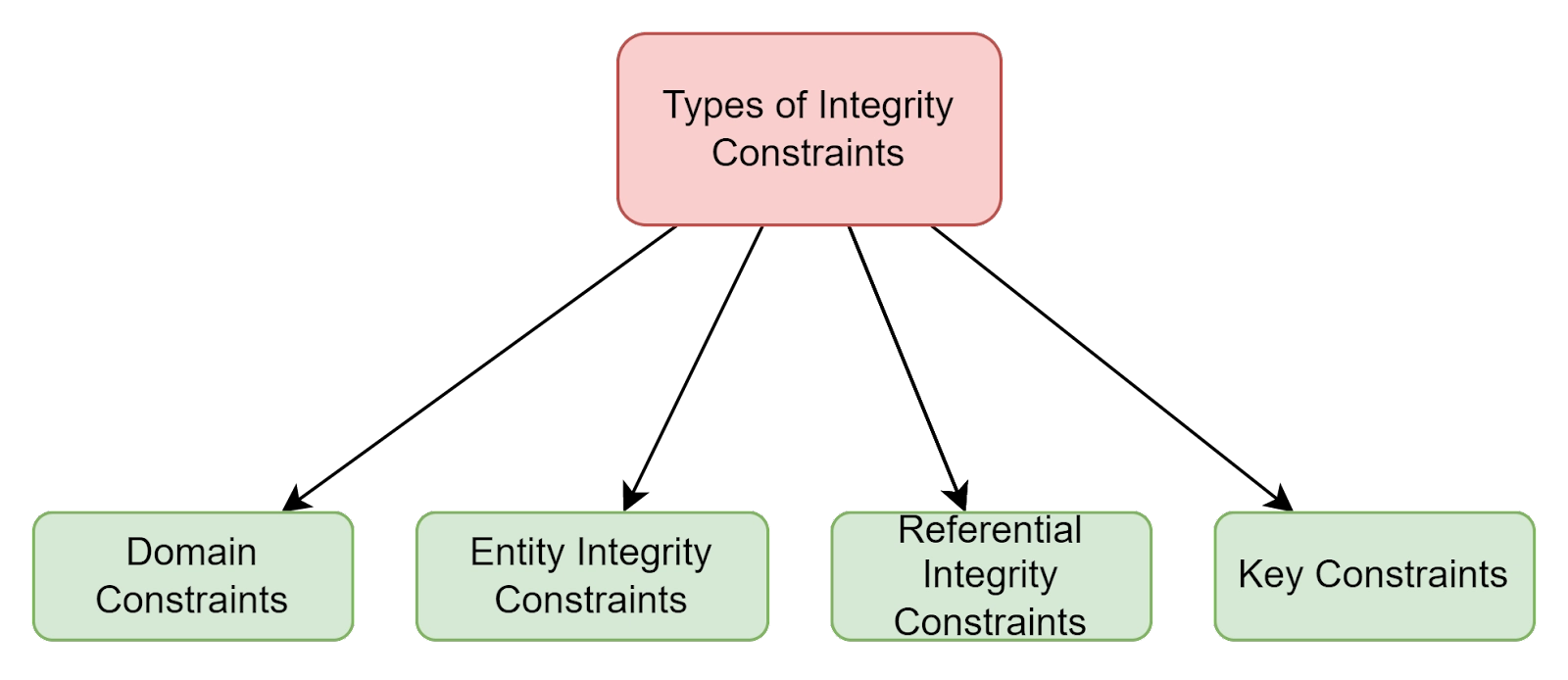
Types of Data Integrity Constraints
Here we have four types of data integrity constraints that are as follows:
Domain Constraints.
Entity Integrity Constraints.
Referential Integrity Constraints.
Key Constraints.
Domain Constraints
Domain constraints are the declaration of valid values for an attribute. Domain data types include string, character, integer, time, date, currency, and more.
According to the domain integrity constraint, domain constraints must disclose all attributes of a relation on a defined domain.
When adding a new attribute to a relation, domain constraints should restrict the type of data must specify the number of properties to restrict the type of data that is stored in the SQL query, such as:
▶️data type
▶️the size
▶️whether or not null values are accepted
▶️the range of acceptable values
▶️the standard value
For example, we want to create a "department" table with information such as dept_id, dept_name, location, etc. So, to ensure domain integrity, we can specify the dept_id has to be unique, dept_name, location has to be character only, etc. we can achieve it by different methods.
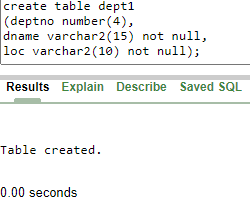
create table dept1
(deptno number(4),
dname varchar2(15) not null,
loc varchar2(10) not null);
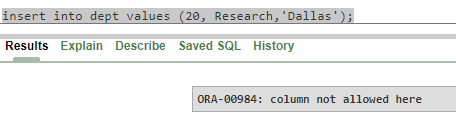
Now, let's try to implement it with data.
insert into dept values (20, 'Research','Dallas');
Here we can see that if we do not write the String Research in double quotes (" "), it will throw an error.
Entity Integrity Constraints
Entity Integrity Constraint ensures that each record or row in the data table is unique. Essentially, two types of integrity constraints ensure each entry's uniqueness, namely the UNIQUE constraint and the PRIMARY KEY constraint.
The unique key keeps in uniquely identifying a record in the data table. It is similar to the Primary key in that both ensure a record's uniqueness. However, unlike the primary key, a unique key can take NULL values and be used on more than one data table column.
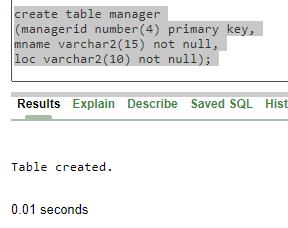
Now, let's try to implement it with data.
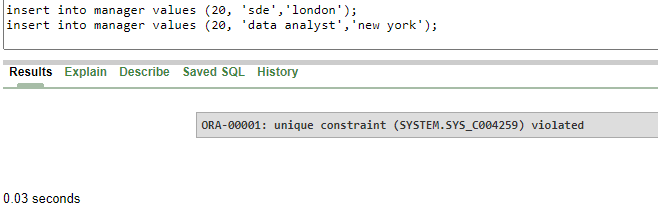
insert into manager values (20, 'sde','london');
Here we can see that the unique key constraints are violated if the primary keys have a common value.
Referential Integrity
The Referential Integrity Constraint assures a proper relationship between two tables. Referential Integrity ensures that if a foreign key exists in one table, it always refers to a value in the second table. Referred key will works as a primary key in the other table.
We are creating a database to generate relations between two tables. We've made a "Department" table and then a "Employees" table, with the "department" property, referring to the "Department number" attribute in the employee table.
create table emp
(empno number(5) primary key,
ename varchar2(10) not null,
job varchar2(20) not null,
mrg number(5),
hiredate date,
sal number(5,1) not null,
comm number(5,1),
dept number(4) references dept);
create table dept
(deptno number(4) primary key,
dname varchar2(15) not null,
loc varchar2(10) not null);
Now, let's try to implement it with data.
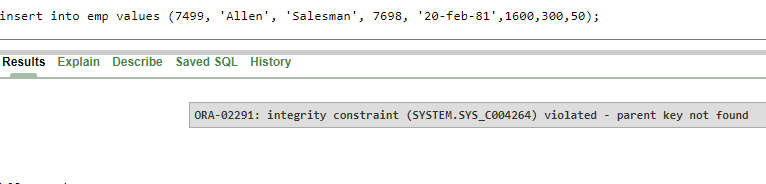
insert into emp values (7499, 'Allen', 'Salesman', 7698, '20-feb-81',1600,300,50);
In the example, we are trying to insert a department that does not exist in the "Department" database, resulting in an error.
Key Constraints
SQL has several key constraints that ensure an entity or record is uniquely or differently identifiable in the database. The table may include more than one key, but only one primary key.
SQL's key constraints include the following:
🔻Primary Key- A primary key is a column – or combination of columns – in a table that uniquely identifies the table's rows of data. For example, empNo, deptno, which displays the ID number allocated to distinct employees and departments, are the main key in the tables above.
🔻Unique Key- A constraint used to identify a tuple in a table uniquely is called a unique key. A table may include many unique keys. In the case of a unique key, NULL values are permitted. These can be used as foreign keys in another table as well.
🔻Foreign Key- A FOREIGN KEY is a field (or group of fields) in one table that relates to a PRIMARY KEY in another table. A table that contains the foreign key is referred as the child in another table, whereas the table containing the primary key is referred as the referenced or parent table.
Normalization is the process of structuring the data in a database. For an efficient database, it is necessary to specify and define tables, keys, columns, and relationships. Normalization protects the data in the database and makes it more flexible by removing redundancy and inconsistent dependencies.
What Is NULL VALUE in SQL?
A field with a NULL value has no value. It is possible to insert a new or edit an existing record without contributing a value to an optional field in a table. The field will then be saved with a NULL value.
Define SQL trigger.
A trigger is a stored procedure triggered when an event happens in the database server. DML triggers are triggered when a user attempts to edit data using a data manipulation language (DML) event. DML events are table or view INSERT, UPDATE, or DELETE statements.
Conclusion
In the above article, we have extensively discussed the introduction to data Integrity Constraints, Types of Integrity Constraints, and examples with explanations.
After reading about Data Integrity Constraints, are you not feeling excited to read/explore more articles on SQL and DBMS? Don't worry; Coding Ninjas has covered other articles also. If you want to check out articles related to SQL then you can refer to these links,
If you want to test your coding skills, you may check out the mock test series and participate in the contests hosted on Coding Ninjas Studio! But suppose you have just started your learning process and are looking for questions asked by tech giants like Amazon, Microsoft, Uber, etc. In that case, you must look at the problems, interview experiences, and interview bundle for placement preparations.
Nevertheless, you may consider our paid courses to give your career an edge over others!
Do upvote our blogs if you find them helpful and engaging!































 9+ registered
9+ registered 

