Do you think IIT Guwahati certified course can help you in your career?
Introduction
In the realm of computer programming and software engineering interviews, one of the most common types of questions is centered on data structures. Understanding the fundamental data structures and having mastery over their implementation is absolutely essential if one is looking to efficiently solve real-world problems.
It is highly likely that data structure questions would pop up in highly technical job interviews. This is the most comprehensive data structure preparation guide for interviews that you will need, irrespective of whether you are a novice or an aspiring advanced specialist.
What is Data Structure?
A Data structure is a useful tool for both organising and manipulating data. Simply put, it enables data to be used more effectively. There are numerous data structures, each of which is appropriate for a specific set of applications.
It's a basic idea in any programming language, and it's crucial for algorithmic design.
Data Structure refers to the way data is arranged and modified. It aims to improve the efficiency of data access. When it comes to the data structure, we don't just look at one piece of data; we look at multiple sets of data and how they might be linked together in a logical way.
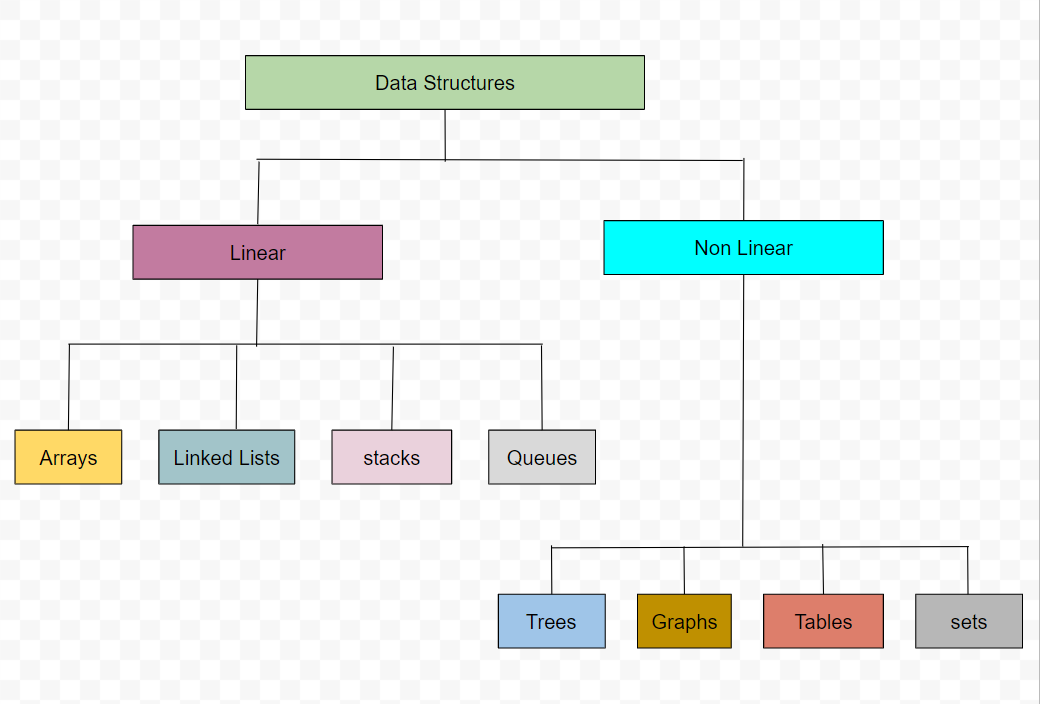
Linear data structure: A linear data structure is one in which the data structure's elements form a sequence or a linear list. Examples include arrays, linked lists, stacks, queues, and other data structures.
Non-linear data structure: A non-linear data structure is one in which the elements of the data structure cause nodes to be traversed in sequential order. Examples include trees, graphs, and other similar structures.
Data Structure Interview Questions with Answers
1. What is binary search?
Only sorted lists or arrays are compatible with a binary search. This search chooses the midway, dividing the full list into two sections. The centre is compared first. The target value is initially compared to the middle of the list in this search. If it cannot be found, it must make a decision.
2. What is bubble sort, and explain how bubble sort works?
Bubble sort is a comparison-based algorithm that compares each pair of nearby elements and swaps elements if they are out of order. It is not suitable for huge sets of data since the time complexity is O(n^2).
3. What is the 'insertion sort'?
Insertion sort separates the list into sorted and unsorted sub-lists. It inserts one element at a time into the proper spot in the sorted sub-list. After insertion, the output is a sorted sub-list. It operates iteratively on all the elements of the unsorted sub-list, inserting them in the correct order into the sorted sub-list.
4. What is selection sort?
In-place sorting is known as selection sort. It separates the data collection into sorted and unsorted sub-lists. The minimal element from the unsorted sub-list is then selected and placed in the sorted list. This loops until all of the elements in the unsorted sub-list have been consumed by the sorted sub-list.
5. Differentiate between insertion sort and selection sorts?
Both sorting strategies keep two sub-lists, sorted and unsorted, and place one element at a time into the sorted sub-list. Insertion sort takes the currently selected element and places it in the sorted array at the right point while keeping the insertion sort attributes. Selection sort, on the other hand, looks for the smallest element in an unsorted sub-list and replaces it with the current element.
6. What is merge sort, and how does it work?
Merge sort is a sorting algorithm that uses a divide and conquer approach to programming. It continues to divide the list into smaller sub-lists until each one contains only one entry. Then it sorts them and merges them until all sub-lists have been eaten. It has an O(n log n) run-time complexity and requires (n) auxiliary space.
7. What is shell sort?
Shell sort can be thought of as a subset of insertion sort. Shell sort breaks the list into smaller sublists based on a gap variable and then uses insertion sort to sort each sublist. It can perform up to O (n log n) in the best-case scenario.
8. How does quicksort work?
Quicksort employs a divide-and-conquer strategy. 'Pivot' divides the list into smaller 'partitions.' The values that are less than the pivot are in the left partition, while the values that are bigger are in the right partition. Quicksort is used to recursively sort each partition.
9. What are infix, prefix, and postfix in data structures?
Notation is a method of writing arithmetic expressions. In an arithmetic expression, there are three sorts of notations that are employed without changing the meaning or outcome of the expression.
These notations are:
Prefix (Polish) Notation - In prefix notation, the operator is ahead of operands i.e. prefixed to the operands, Infix Notation - In infix notation, operators are used in between the operands. Postfix (Reverse-Polish) Notation - In postfix operations, the operator is after the operands, i.e. postfixed to the operands.
Infix
Postfix
Prefix
x + y
xy+
+xy
(x + y)*z
xy+z**
+xyz
x * (y + z)
xyz+*
*x+y
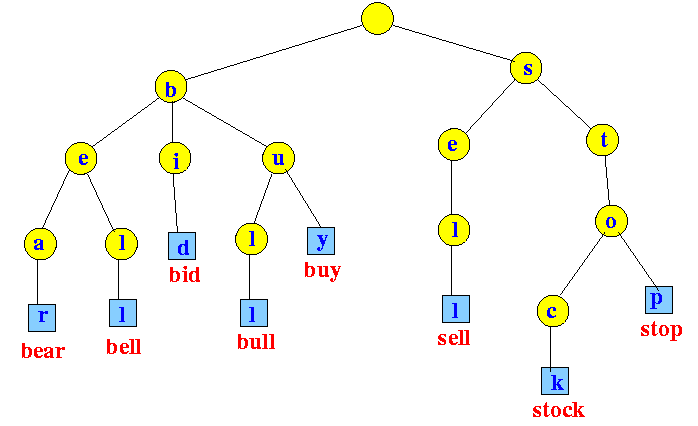
10. What is Trie's data structure?
Trie is a useful Data structure for retrieving information. Search complexities can be reduced to a minimum using Trie (key length). A well-balanced binary search tree will require time proportional to M ( log N), where M is the maximum string length, and N is the number of keys in the tree. We can search for the key in O(M) time using Trie. Trie's nodes are made up of many branches. Each branch represents a different essential character. Every key's last node must be marked as the end of the word node. To recognise the node as an end-of-word node, the Trie node field isEndOfWord is used.
Compare the lookup operation in Trie vs Hash Table?
Tries allow for ordered iteration, whereas iterating over a hash table produces a pseudorandom order determined by the hash function (the order of hash collisions is also implementation specified), which is usually useless.
Tries are faster at insertion than hash tables on average because hash tables must rebuild their index as it fills up, which is a costly operation. As a result, tries have considerably better limited worst-case time costs, which is crucial for latency-sensitive algorithms.
As a result of the aforementioned, tries to facilitate longest-prefix matching, but hashing does not. Depending on the implementation, a "closest fit" search can be as quick as an exact search.
11. How do you convert a Queue into a Stack?
To build a stack using queues, we'll need two queues (q1 and q2), as well as the following queue actions to imitate stack operations: For Pushing an element E: if q1 is empty, enqueue E to q1 if q1 is not empty, enqueue all elements from q1 to q2, then enqueue E to q1, and enqueue all elements from q2 back to q1
For popping an element: dequeue an element from q1 As we can see, q1 is the stack's main source, while q2 is merely a helper queue that we utilize to keep the stack's anticipated order.
12. Explain the main advantages of Tries over Binary Search Trees (BSTs).
It is more efficient to look up keys. A key of length m takes O(m) time to search for. A BST performs O(log(n)) key comparisons, where n is the number of items in the tree because lookups are reliant on the depth of the tree, which is logarithmic in the number of keys if the tree is balanced. As a result, in the worst-case scenario, a BST takes O(m log n) time. Furthermore, in the worst-case scenario, log(n) will approach m. On real processors, simple acts like array indexing with a character, which are used during lookup, are also speedy.
The length of the key is equal to the number of internal nodes from the root to the leaf. As a result, balancing the tree is not an issue.
Because nodes are shared between keys with common starting subsequences, tries with a large number of short keys are more space-efficient.
13. What are the differences between a String and a Character array?
The following is the difference between a string and a character array:
Parameter
Strings
Character Array
Definition
String refers to a sequence of characters represented as a single data type.
Character array is a sequential collection of data type char.
Mutability
Strings are immutable.
Character Arrays are mutable.
Memory Storage
Strings can be stored in any manner in the memory.
Elements in a character array are stored contiguously in increasing memory locations.
Password Storage (Java)
Not preferred for storing passwords in Java.
Preferred for storing passwords in Java.
Storage Location
All Strings are stored in the String Constant Pool.
All character arrays are stored in the Heap.
14. What is a dequeue?
A dequeue is a queue with two ends. This is a structure that can have elements added or deleted from both ends.
15. Name some characteristics of the Array Data Structure.
Some characteristics of arrays are:
The primary memory stores array elements in contiguous memory blocks.
The base address is represented by the array name.
The base address is the address of the array's first element.
The index of an array begins with 0 and ends with size- 1.
16. What's the difference between the data structures Tree and Graph?
A tree structure is connected and cannot include loops, whereas there are no such restrictions in a graph. The graph follows a network paradigm, whereas the tree gives hierarchical information about the interaction between nodes.
17. What is a priority queue?
A priority queue is similar to a regular queue of elements, except that each entry has a different priority. Only this order is followed by the entries in the priority queue. Let's say we have some values like 1, 2, 7, 8, 14, and 31 in a priority queue with an ordering based on least to greatest values. As a result, number 1 will have the highest priority, while number 31 will have the lowest.
18. State the difference between a stack and a queue.
Differences between a stack and a queue are as follows:
Parameter
Stack
Queue
Insertion and Deletion
Insertion and deletion in stacks take place only from one end of the list called the top.
Insertion and deletion in queues take place from opposite ends of the list. The insertion takes place at the rear end of the queue, and the deletion takes place from the front end.
Insert Operation Name
Insert operation is called push in a stack.
Insert operation is called enqueue operation.
Delete Operation Name
Delete operation is called pop in a stack.
Delete operation is called dequeue operation.
19. What is a binary heap?
A binary heap is a complete binary tree that satisfies the heap ordering property. A Binary Heap can either be a Min Heap or a Max Heap. It’s a complete tree. ,Thus, it is suitable for being stored in an array.
20. What Data Structures make use of pointers?
The following Data Structures make use of pointers:
Queue
Stack
Linked List
Binary Tree.
21. What is a Bipartite Graph? How to detect one?
Let’s consider a graph G(V, E). The graph G is a bipartite graph if:
The vertex set V of G can be divided into two separate and disjoint sets, V1 and V2.
Every edge in the edge collection E has one V1 endpoint vertex and another V2 endpoint vertex.
Some important points regarding the bipartite graph:
If a graph is bipartite, it will never include odd cycles.
A bipartite graph's subgraphs are also bipartite.
The degree of each vertex partition set in an undirected bipartite graph is always equal.
To check whether the graph is bipartite or not, we use graph coloring and BFS to determine it. Steps of the algorithm:
Give the initial vertex a red color
Find the starting vertex's neighbors and give them a different color (let's say blue)
Find your neighbor's neighbor and color them red
Continue this step until all of the graph's vertices are colored
If a neighbor vertex and a coming vertex are the same colour during this procedure, the graph is not a bipartite graph.
22. What is a spanning tree?
A spanning tree is a subset of Graph G that covers all of the vertices with the fewest amount of edges possible. There are no cycles in a spanning tree, and they cannot be severed.
23. How many spanning trees can a graph have?
It is dependent on the graph's degree of connectivity. The greatest number of spanning trees in a full undirected graph is n(n-1), where n is the number of nodes.
24. What is a minimum spanning tree (MST)?
A minimum spanning tree in a weighted graph is one that has the same weight as all other spanning trees in the graph.
25. Explain the use of the Heap data structure.
Heaps are structures that offer quick access to the minimum and maximum values. It allows you to rapidly determine the next smallest or largest by pulling the smallest or largest. It's called a Priority Queue for a reason.
Because the largest (or smallest) item is always the first member in the array or at the root of the tree, utilise it whenever you require quick access to it. The rest of the array, on the other hand, is retained largely unsorted. As a result, immediate access is limited to the largest (smallest) item. Because insertions are quick, it's a fantastic approach to deal with incoming events or data and always have the most recent/largest. Also read - Data Structure MCQ
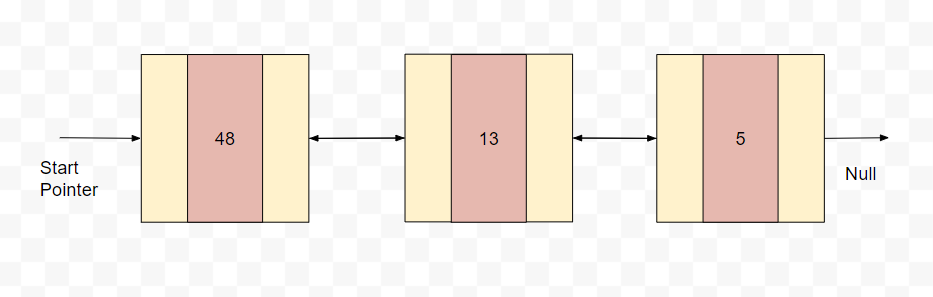
26. Explain the advantage of a doubly-linked list over a singly linked list.
Because both the front and rear ends of a doubly-linked list are immediately accessible.
Doubly linked lists are the best underlying data structure for a queue because they delete data from the front in O(1) time and can insert data at the end in O(1) time.
Because we need to remove the least recently items frequently, a doubly-linked list is employed in LRU cache design. The deletion process is quicker.
In a single-linked list, all operations require the maintenance of an extra pointer. In insertion, for example, we must adjust previous and next pointers simultaneously.
27. Explain the scenarios where you can use linked lists and arrays?
The following are the scenarios where we use a linked list over an array: → There are fewer random access operations. → A linked list is better for inserting items anywhere in the middle of a list, such as when building a priority queue. → When we don't know how many elements there will be ahead of time. → The following are examples of when we utilise arrays instead of linked lists: → When we need to iterate over the sequence's elements quickly. → When we need to index or access elements at random more often. → Because of the differences between arrays and linked lists, it's safe to assume that filled arrays consume less memory than linked lists. → In a word, while picking which data structure to utilise over what, space, time, and ease of implementation are all taken into account.
28. What is a doubly-linked list (DLL)? What are its applications?
It's a special sort of linked list (double-ended LL) in which each node has two links, one to the next node in the sequence and the other to the previous node. This permits traversal in both directions across the data pieces.
Applications: → BACK-FORWARD viewed pages in the browser cache → On systems like Word and Paint, you can reverse the node to return to the previous page using the undo and redo capabilities.
29. What are the differences between a B-tree and a B+ tree?
The following are the differences between B and B+ trees:
Parameter
B Tree
B+ Tree
Search Keys
Search keys cannot repeatedly be stored.
Redundant search keys can be present.
Data Storage
Data can be stored in leaf nodes as well as internal nodes.
Data can only be stored on the leaf nodes.
Search Efficiency
Searching for some data is a slower process since data can be found on internal nodes as well as on the leaf nodes.
Searching is comparatively faster as data can only be found on the leaf nodes.
Deletion Process
Deletion of internal nodes is so complicated and time-consuming.
Deletion will never be a complex process since elements will always be deleted from the leaf nodes.
Leaf Node Linking
Leaf nodes cannot be linked together.
Leaf nodes are linked together to make the search operations more efficient.
Frequently Asked Questions
How to reference all the elements in a one-dimensional array?
An indexed loop is used to do this, with the counter running from 0 to the array size minus one. We can reference all the elements in order by using the loop counter as the array subscript in this way.
What is an array?
Arrays are collections of data elements of comparable types stored in contiguous memory regions. It is the most basic data structure in which each data element can be accessed at random by its index number.
What is the minimum number of queues that can be used to implement a priority queue?
There are two queues required. The data items are stored in one queue, while the priority is stored in another.
Conclusion
In this article, we have extensively discussed Data Structure Interview Questions with the types of questions, data structures, and their applications in the world around us. Knowing this will help you in almost all of the software engineering interviews, as well as help you in good programming basics. Make sure to solve as many data structure problems as possible to help improve your confidence level as well as your skill level in technical interviews.






























 40+ registered
40+ registered 

