Do you think IIT Guwahati certified course can help you in your career?
Introduction
Ever thought of how online dictionaries work? Data Structures is the reason how the words that you search gets displayed so instantly and even when you are not sure about the complete word the suggestions pop up. There are a lot of ways of creating such a data structure but the problem comes when we have to perform some operations like lookup or suggestions function which might take a huge amount of time considering a dictionary would contain tens of thousands of words. Even some data structures cannot be even used for suggestions at all. They do not provide any option rather than having a complete word search in the set of words in the dictionary which will, in turn, result in lagging time complexity.
The idea is to store the words as key-value pair to look up easily and more efficiently. Hashing is basically used in unordered maps to store the words as key-value pairs hence the retrieving cost if just cost time. In C++, we have maps for implementing hashing as normal and unordered maps. Let us see an example:
Code Implementation
#include <bits/stdc++.h>
using namespace std;
//use of map/hashing
int main() {
// your code goes here
map<int,string> mp; //storing words in the map
int n;
cin>>n;
for(int i = 0;i<n;i++){
string s;
cin>>s; //input of words from the map
mp[i] = s; //storing the words in the map
}
for(auto word : mp){
//printing the store value in the map
cout<<word.second<<endl;
}
return 0;
}
You can also try this code with Online C++ Compiler
For lookup, we would require O(n) of time complexity to search through all the elements of the hash map. In C++ STL we use the find function for lookup operation. Hashing is effective when we have to store a key-value pair type of data.
Trie Data Structure
Trie is an efficient data retrieval Data structure mostly used for string manipulations. It provides a way to store strings efficiently and also to search for them in a lot lesser time complexity. Each node of the Trie consists of 26 pointers (general implementation) of type node which is used to store the nodes of the adjacent or following character of the string, and a Boolean end of character which denotes the current node is the end of a word or not. We can insert and find a key(string) in O(n) time, where n is the length of the key.
Code Implementation
class trienode {
public:
trienode *children[26];
bool endofword;
trienode(){
for(int i = 0;i<26;i++ )
children[i] = NULL;
endofword = false;
}
};
class Trie {
trienode *root;
public:
/** Initialize your data structure here. */
Trie() {
root = new trienode;
}
/** Inserts a word into the trie. */
void insert(string word) {
trienode *curr = root;
for(char ch : word){
int index = ch - 'a';
if(!curr->children[index])
curr->children[index] = new trienode();
curr = curr->children[index];
}
curr->endofword = true;
}
/** Returns if the word is in the trie. */
bool search(string word) {
trienode *curr = root;
for(char ch : word){
int index = ch - 'a';
if(!curr->children[index])
return false;
curr = curr->children[index];
}
return (curr!=NULL && curr->endofword);
}
};
You can also try this code with Online C++ Compiler
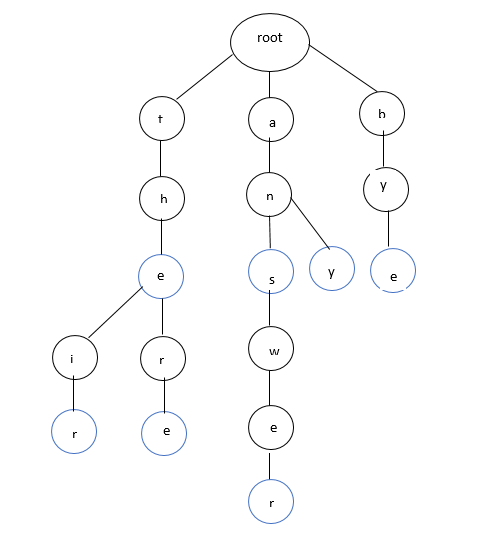
A general Trie will look like this in the dictionary.
Each of the root to leaf and in between prefixes can contain a word, it can denote multiple words which makes is quite simple for search for prefixes and suggestions for autocompletion. For example, typing “an” can suggest us two words – “answer” and “any” which can be easily seen from the above example that they belong to the same root node branch. For this lookup it just takeswhere k is the length of the word to be searched. Hence this trie data structure becomes hugely popular and helpful in dictionary and spell checker program as a valuable data structure.
Ternary Search Trie
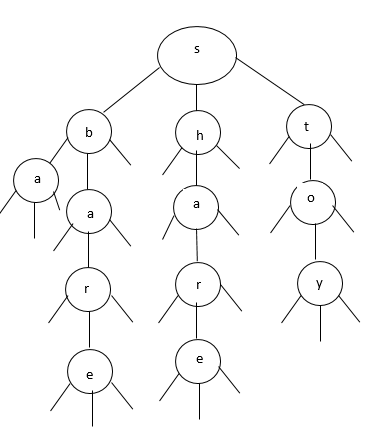
In this type of Trie now we store characters and values in the node rather than keys. It consists of three nodes left, middle, right. The idea is we consider the current node only when we move down i.e., to the middle node. If se select the next left or right node we do not consider the parent node data in our word.
Let us see an example:
Consider the below diagram, the trie basically starts with the same structure although if we start from “s” and we want to include it like in for the word “share” we move down to “h” from “s” i.e., to the middle pointer. If we do not want to include “s” we move to either of the side pointers for any other word like “bare” or “toy”.
Searching hits – L+InN, where N is the length of the word we are searching for.
Space complexity – 4N
Hence, we can see that ternary search tries are the most efficient data structure that we can build for dictionary and spell-checking purpose. Later more modifications have been implemented to make this more efficient. These can also be used in a small project for dictionary portfolio.
A graph is a non-linear data structure consisting of nodes (also known as vertices) and edges. The nodes represent entities, while the edges represent relationships between those entities.
What is the difference between a graph and a tree?
A tree is a type of graph that is always connected and has no cycles. In other words, a tree is a special case of a graph. Graphs, on the other hand, can have cycles and may not necessarily be connected.
What are some common algorithms for graph traversal?
There are two main algorithms for graph traversal: depth-first search (DFS) and breadth-first search (BFS). DFS is a recursive algorithm that explores as far as possible along each branch before backtracking, while BFS explores the graph layer by layer, visiting all the neighbors of a node before moving on to the next level.
What is the shortest path problem in graph theory?
The shortest path problem is the problem of finding the shortest path between two nodes in a graph. The most common algorithm for solving this problem is Dijkstra's algorithm, which uses a priority queue to explore the graph in a greedy manner.
Conclusion
This article discussed Data Structures for Dictionary & Spell Checker with all the crucial aspects necessary to implement them. We will also take a look at the time and space complexity of the program.































 9+ registered
9+ registered 

