


























Introduction
The enterprise data is categorized both as structured and unstructured. The data is specified into multiple rows and columns and stored in different formats like emails, logs, etc. Big Data is stored in log files and other apps in various forms.
Data Virtualization provides a technique for integrating data from several sources without copying or pasting it. It provides a single layer that combines multiple applications and physical locations.
Applications:
1. Helpful in data mining.
2. Pathway for data analytics.
3. Better pavement for artificial intelligence and machine learning.
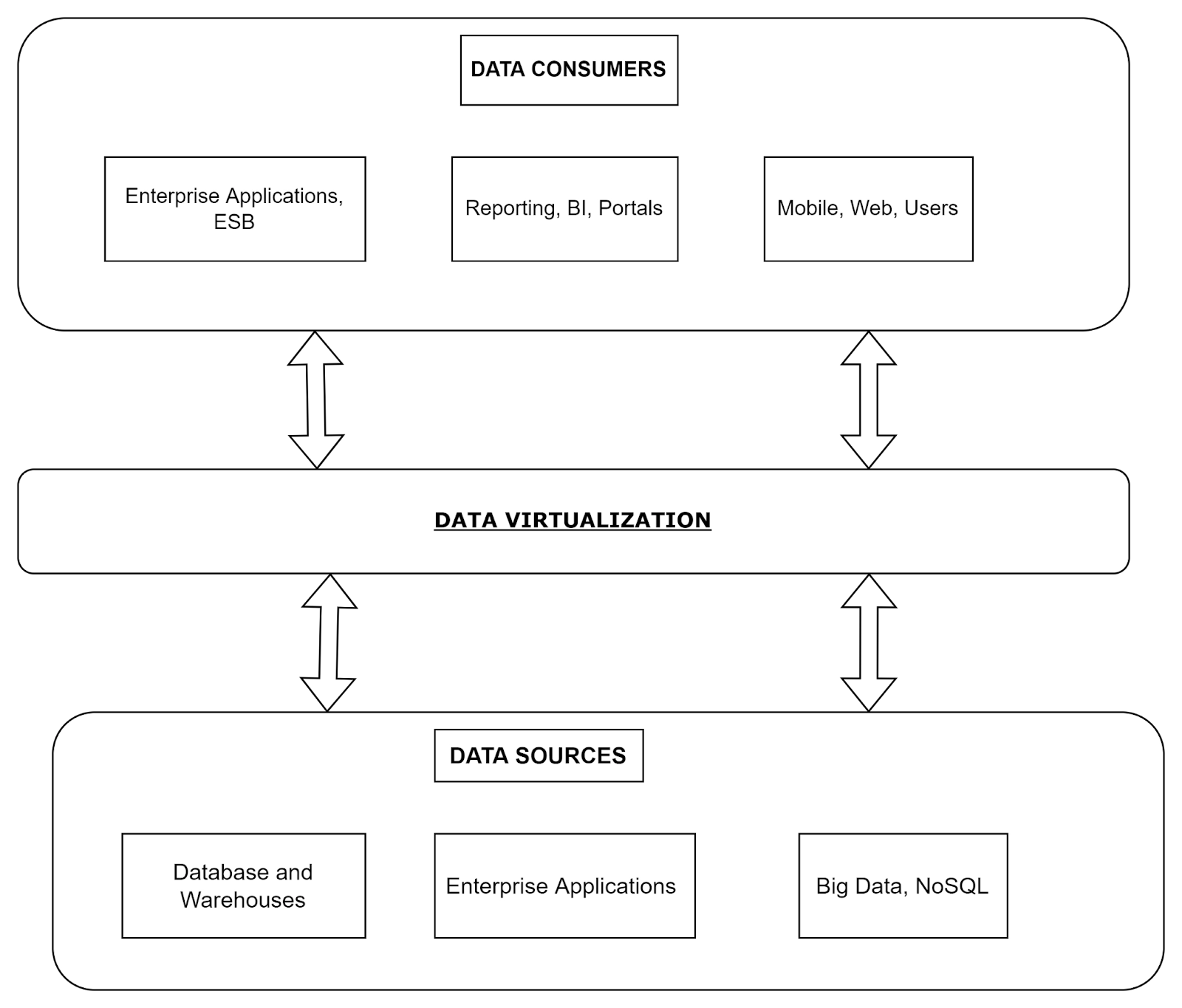
Architecture
The solutions of data virtualization must be designed to tackle the needs of the ever-changing environment. The technique involves continuous addition and removal of data. Data Virtualization increases the complexity, followed by the addition of code overlapping. The main points of the consideration during data virtualization are:
1. The applications must be built using the layered approach to mark the isolation of business logic and other components.
2. Strict rules must be framed for layer isolation.
3. Power Designer, Cisco Data Virtualization, and TIBCO Data Virtualization are different data modelling tools.
4. Data Virtualization demands the complete involvement of data security and data architecture teams.
5. Define the responsibilities of different performers of the Data Virtualization platform.


 9+ registered
9+ registered 

