Get a skill gap analysis, personalised roadmap, and AI-powered resume optimisation.
Introduction
All major firms generate vast volumes of data, which is typically dispersed across several distinct platforms. This was not an intentional decision, but rather the result of a series of pragmatic decisions. With the use of Software as a Service (SaaS) apps and other cloud solutions, silos are generating friction between the business and IT. Integrating various data silos is notoriously difficult, and using a standard data warehouse method presents obvious issues. As a result, IT businesses have explored innovative techniques to complete tasks (at the urgent request of the business).
This comparison examines two contemporary techniques for data integration: data lakes and data virtualization. Both technologies simplify self-service data consumption across diverse sources without interfering with current applications.
Now, without any further ado, let’s understand each of these methods and analyze the difference between them.
What is a Data Lake?
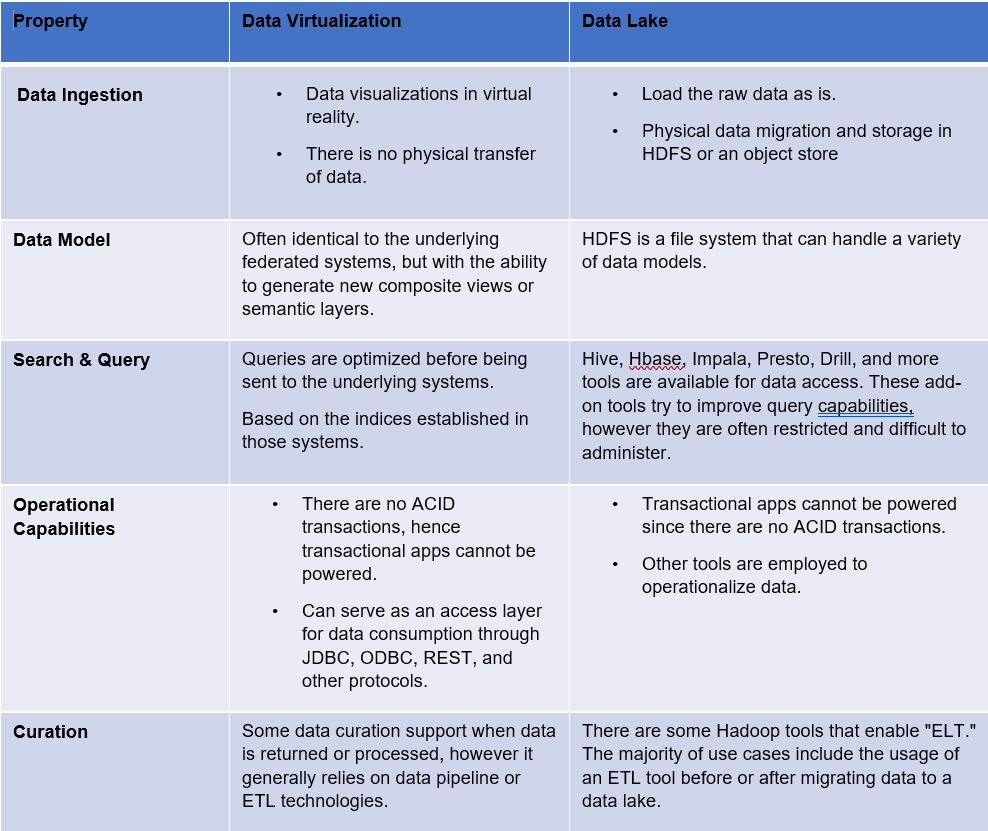
A data lake is a centralized repository that allows data storage at any scale or shape. They gained popularity with the emergence of Hadoop, a distributed file system that made it simple to transport raw data into a centralized repository for low-cost storage. The data in data lakes may not be curated (enriched, mastered, or harmonized) or searchable. They typically require other Hadoop ecosystem tools to analyze or operationalize the data in a multi-step process. However, data lakes have the advantage of needing little Data lakes may be used to serve as an analytics sandbox, train machine learning models, feed data prep processes, or simply provide low-cost data storage.
A few years ago, three significant participants were in the Hadoop landscape: Cloudera, Hortonworks, and MapR. Following its merger with Hortonworks and MapR's fire sale, only Cloudera survives.
Object stores like Amazon S3 have become de facto data lakes for many enterprises, facilitating the transition to the cloud from an on-premises Hadoop ecosystem.
Aside from the Hadoop core, the Apache ecosystem contains a plethora of other related technologies. Spark and Kafka, for example, are two prominent technologies for processing streaming data and doing analytics in an event-streaming architecture (they are marketing by Databricks and Confluent, respectively) effort on the front end when importing data.
What is Data Virtualization?
Establishing virtual representations of data housed in existing databases is known as data virtualization. The actual data does not change, but the new virtual data layer provides an integrated picture of the data. This is known as a data federation (or virtual database), and the federates are the underlying databases.
For example, suppose you have a couple of Oracle and SAP databases operating, and a department needs data from those systems. Instead of physically transporting the data via ETL and storing it in another database, architects may digitally access and integrate the data for that specific team or use case.
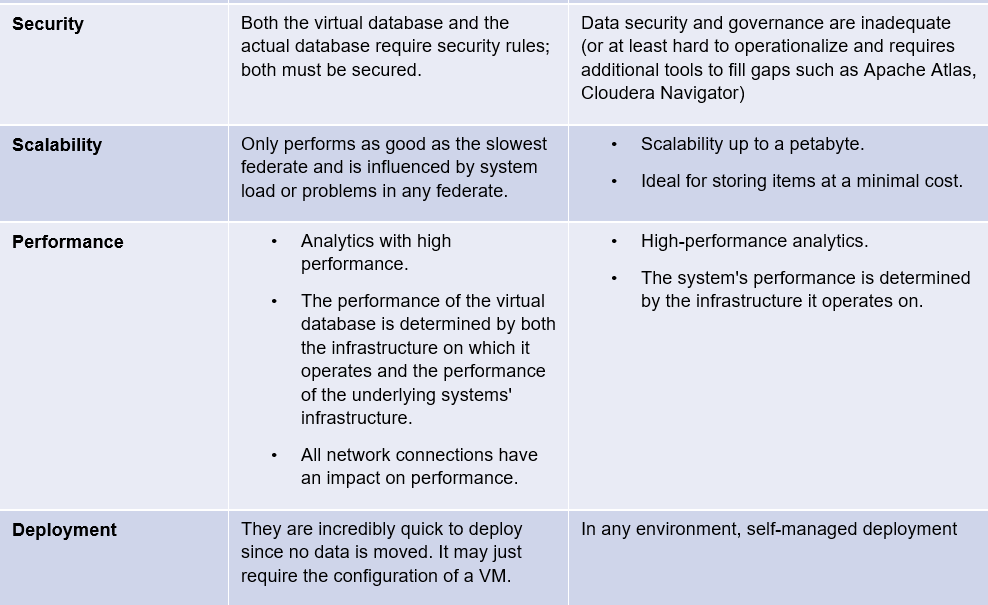
Queries are sent to the underlying database using data virtualization. Newer virtualization technologies are becoming more advanced when it comes to query execution planning and optimization. They may employ in-memory cached data or integrated massively parallel processing (MPP), with the results being merged and mapped to provide a composite picture of the findings. Many of the most recent data virtualization solutions can also write data (not just read). Newer solutions also demonstrate advancements in data governance, masking data for different roles and use cases and LDAP authentication.
One of the primary advantages of data virtualization is a shorter time to value. Because the data is not physically transported, they need less labor and expenditure before you can begin querying it, making them less disruptive to your existing infrastructure.
Another significant advantage is that data virtualization allows users to conduct ad hoc SQL queries on both unstructured and structured data sources, a fundamental use case for data virtualization.
Data Virtualization Vs Data Lake
When is a Data Lake a Better Fit?
Data Lakes are ideal for streaming data and as repositories when enterprises want a low-cost solution for storing vast volumes of organized or unstructured data. Most data lakes are supported by HDFS and can be simply integrated into the larger Hadoop ecosystem. As a result, it is an excellent alternative for big development teams who wish to use open-source tools and want a low-cost analytics sandbox. Many firms use their data lake as their "data science workbench" to power machine learning projects in which data scientists need to store training data and feed Jupyter, Spark, or other tools.
When is Data Virtualization the better Option?
For certain analytics use cases that do not necessitate the resilience of a data hub, data virtualization is the ideal solution. They can be implemented fast, and because physical data is never transferred, provisioning infrastructure at the start of a project is simple. Data virtualization is also commonly used by data teams to execute ad-hoc SQL queries on top of non-relational data sources.
Frequently Asked Questions
What is ETL logic?
ETL is a process that takes data from various source systems, transforms the data (such as applying computations, concatenations, and so on), and then loads the data into the Data Warehouse system. ETL stands for Extract, Transform, and Load.
Is MarkLogic a data lake?
The MarkLogic Data Hub Service is Data Lakes done right.
What is data virtualization?
Data virtualization is an umbrella word for a data management strategy that allows an application to obtain and alter data without requiring technical specifics about the data, such as how it is structured or where it is physically housed.
Conclusion
In this article, we have learned about the Data Lake and Data virtualization data management strategies. We have also talked about the difference between the two.
We hope that this blog has helped you enhance your knowledge of virtualization and big data, and if you would like to learn more about them, check out our articles on codingninjas.com/blog: Big data, Hadoop
Big Data Engineer Salary in Various Locations- Coding Ninjas Blog
Azure, Cloud, Google, AWS, MongoDB, Databases, Operational Databases, Data Mining, Data Warehouse, Non-relational databases.






























 8+ registered
8+ registered 

