


























Introduction
UGC NET Exam is a very popular exam in India for people interested in research. Previous Year Questions are an excellent option to learn about the exam pattern. By solving the PYQs, you will get a basic idea about your preparation.
Refer to Dec 2014 Paper III Part 1 here.
Refer to Dec 2014 Paper III Part 3 here.
You can evaluate your weak areas and work on them to perform better in the examination. In this article, we have given the questions of UGC NET Dec 2014 Paper III. We have also explained every problem adequately to help you learn better.
Dec 2014 Paper III Part 2
26. How many characters per second (7 bits + 1 parity) can be transmitted over a 3200 bps line if the transfer is asynchronous? (Assuming 1 start bit and 1 stop bit)
(A) 300 (B) 320
(C) 360 (D) 400
Answer: B
In asynchronous transmission, for each character, we need to send data, parity, and start and stop bits.
Size of one character = 7+1+1+1 = 10 bits
Line transmits 3200 bits in one second.
No of characters transmitted in one second = 3200/10 = 320
27. Which of the following is not a field in the TCP header?
(A) Sequence number (B) Fragment offset
(C) Checksum (D) Window size
Answer: B
The fragment offset is not a field in the (Transmission Control Protocol)TCP header.
28. What is the propagation time if the distance between the two points is 48,000? Assume the propagation speed to be 2.4 × 108 metre/second in cable.
(A) 0.5 ms (B) 20 ms
(C) 50 ms (D) 200 ms
Answer: Marks given to all
We know that, propagation time = distance between two point / propagation speed.
Distance between two point = 48000 km = 48 x 106.
Propagation speed = 2.4 × 108.
Propagation time = 48 x 106 / 2.4 × 108
= 0.2 sec = 200 ms.
29. .............. is a bit-oriented protocol for communication over point-to-point and multipoint links.
(A) Stop-and-wait (B) HDLC
(C) Sliding window (D) Go-back-N
Answer: B
HDLC(high-level data link control) is a classical bit-oriented code-transparent synchronous data link layer protocol developed by the International Organization for Standardization (ISO) protocol.
HDLC provides both connection-oriented and connectionless services.
HDLC can be used for point to multipoint connections but is now used almost exclusively to connect one device to another, using what is known as Asynchronous Balanced Mode (ABM).
Related Article HDLC Protocol
30. Which one of the following is true for asymmetric-key cryptography?
(A) Private key is kept by the receiver and the public key is announced to the public.
(B) Public key is kept by the receiver and the private key is announced to the public.
(C) Both the private keys and public keys are kept by the receiver.
(D) Both private keys and public keys are announced to the public.
Answer: A
Asymmetric-key cryptography uses two keys: a private key and a public key.
The private key is kept by the receiver and the public key is announced to the public.
31. Any decision tree that sorts n elements has a height
(A) W (n)
(B) W (lgn)
(C) W (n lgn)
(D) W (n2)
Answer: C
Any decision tree that sorts n elements has height Omega(n log n).
Proof:
A binary tree of height h has <= 2^h leaves.
At least n! leaves are required for sorting.
Thus n! <= 2^h.
h >= lg(n!) = sum_{i=2}^n lg(i) > sum_{i=n/2}^n lg(i) > sum_{i=n/2}^n lg(n/2)
> (n/2) lg(n/2) = Omega(n lg n).
32. Match the following :
List – I List – II
a. Bucket sort i. O(n3lgn)
b. Matrix chain multiplication ii. O(n3)
c. Huffman codes iii. O(nlgn)
d. All-pairs shortest paths iv. O(n)
Codes :
a b c d
(A) iv ii i iii
(B) ii iv i iii
(C) iv ii iii i
(D) iii ii iv i
Answer: C
Bucket sort = O(n) - The bucket sort traverses the array divided into buckets
Matrix chain multiplication = O(n3) - It is a dynamic programming algorithm to cover all scenarios in the matrix.
Huffman codes =O(n logn) - This algorithm involved logarithmic complexity executed n times.
All pairs shortest paths = O(n3logn) - This is the standard time complexity to shortest path pairs.
33. We can show that the clique problem is NP-hard by proving that
(A) CLIQUE ≤ P 3-CNF_SAT
(B) CLIQUE ≤ P VERTEX_COVER
(C) CLIQUE ≤ P SUBSET_SUM
(D) None of the above
Answer: D
Let us have a look at how Reducilibility works.
- If B ∈ P and A ≤P B then A ∈ P
- If B ∈ NP and A ≤P B then A ∈ NP
- If B ∈ NP-Complete and A ≤P B then A ∈ NP
- If B ∈ NP-Complete and B ≤P A then A ∈ NP-Hard
- If B ∈ NP-complete and A ∈ NP and B ≤P A then A ∈ NP-Complete
- If B∈ undecidable and B ≤P A means A is undecidable
- If B∈ undecidable and A ≤P B No inference
34. Dijkstra algorithm, which solves the single-source shortest--paths problem, is a ................, and the Floyd-Warshall algorithm, which finds shortest paths between all pairs of vertices, is a ...............
(A) Greedy algorithm, Divide-conquer algorithm
(B) Divide-conquer algorithm, Greedy algorithm
(C) Greedy algorithm, Dynamic programming algorithm
(D) Dynamic programming algorithm, Greedy algorithm
Answer: C
Dijkstra algorithm, which solves the single-source shortest-paths problem, is a Greedy algorithm, and the Floyd-Warshall algorithm, which finds the shortest paths between all pairs of vertices, is a Dynamic programming algorithm.
35. Consider the problem of a chain <A1, A2, A3> of three matrices. Suppose that the dimensions of the matrices are 10 × 100, 100 × 5 and 5 × 50 respectively. There are two different ways of parenthesization : (i) ((A1 A2)A3) and (ii) (A1(A2 A3)). Computing the product according to the first parenthesization is .................. times faster in comparison to the second parenthesization.
(A) 5 (B) 10
(C) 20 (D) 100
Answer: B
Using above statements find no of multiplications for two matrices.
Case I)
A1 =10x100,A2=100x5,A3=5x50.
((A1A2)A3) :first find A1A2(=P) no of muls=10*100*5=5000.//A1A2= P(assume)
then PA3 : P is 10x5 and A3 is 5x50
no of muls=10*5*50=2500.
Total no of multiplications=5000+2500=7500.
Case II)
(A1(A2A3)) :first A2A3(=Q) no of muls=100*5*50=25000.//A2A3=Q(assume)
(A1Q). Q is 100x50 and A1 is 10x100.
no of muls=10*100*50=50000.
Total no of multiplications=50000+25000=75000.
Comparing both, first one is 10 times faster than 2nd one.
36. Suppose that we have numbers between 1 and 1000 in a binary search tree and we want to search for the number 365. Which of the following sequences could not be the sequence of nodes examined?
(A) 4, 254, 403, 400, 332, 346, 399, 365
(B) 926, 222, 913, 246, 900, 260, 364, 365
(C) 927, 204,913, 242, 914, 247, 365
(D) 4, 401, 389, 221, 268, 384, 383, 280, 365
Answer: C
We have to find 364 in BST:
- In the first option, 925 is the root node, and our key is less than 925 so we go for left BST. The next node is 221 → 912 → 245 → 899 → 259 → 363 → 364 respectively.
- In second option 3 is the root node, we go for the right BST i.e. 400 → 388 → 220 → 267 → 383 → 382 → 279 → 364 respectively.
- In the third option, 926 is the root node, we go for left BST i.e. 203 → 912 → 241 next key is 913 we can't go for 913 after 241 because we are already in left BST of 912 our key will be surely in left BST of 912. This option is incorrect.
- In fourth option 3 is the root node, we go for the right BST i.e. 253 → 402 → 399 → 331 → 345 → 398 → 364.
37. Which methods are utilized to control the access to an object in multi-threaded programming?
(A) Asynchronized methods
(B) Synchronized methods
(C) Serialized methods
(D) None of the above
Answer: B
With respect to multithreading, synchronization is the capability to control the access of multiple threads to shared resources. Without synchronization, it is possible for one Java thread to modify a shared variable while another thread is in the process of using or updating the same shared variable. This usually leads to erroneous behaviour or program.
38. How do express that some person keeps animals as pets?
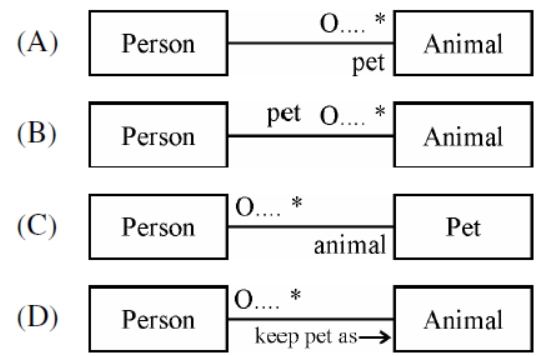
Answer: A
A person may have none or many animals as pets(one to many relationships) which is shown by A.
39. Converting a primitive type of data into its corresponding wrapper class object instance is called
(A) Boxing (B) Wrapping
(C) Instantiation (D) Autoboxing
Answer: D
Converting a primitive type of data into its corresponding wrapper class object instance is called Autoboxing.
Instantiation is the creation of a real instance or a particular realization of abstraction or template.
Wrapping encapsulates and hides the underlying complexity of another entity.
Boxing is the process of converting a value type to the type object or to any interface type implemented by this value type.
40. The behaviour of the document elements in XML can be defined by
(A) Using document object
(B) Registering appropriate event handlers
(C) Using element object
(D) All of the above
Answer: D
The JavaScript program can define the behaviour of document elements by registering appropriate event handlers. A JavaScript program can traverse and manipulate document content through the Document object and the Element objects it contains.
41. What is true about UML stereotypes?
(A) Stereotype is used for extending the UML language.
(B) Stereotyped class must be abstract
(C) The stereotype indicates that the UML element cannot be changed
(D) UML profiles can be stereotyped for backward compatibility
Answer: A
The stereotype is used for extending the UML language.
42. Which method is called first by an applet program?
(A) start( ) (B) run( )
(C) init( ) (D) begin( )
Answer: C
The init( ) method is the first method to be called. This is where you should initialize variables. This method is called only once during the run time of your applet.
43. Which one of the following is not a source code metric?
(A) Halstead metric (B) Function point metric
(C) Complexity metric (D) Length metric
Answer: B
Source code metrics - Source code metrics are essential components in the software measurement process. They are extracted from the source code of the software, and their values allow us to reach conclusions about the quality attributes measured by the metrics.
Function point metrics provide a standardized method for measuring the various functions of a software application. It measures the functionality from the user's point of view, that is, on the basis of what the user requests and receives in return.
The function point metric is not a source code metric.
44. To compute function points (FP), the following relationship is used
FP = Count - total × (0.65 + 0.01 × S (Fi)) where Fi (i = 1 to n) are value adjustment factors (VAF) based on n questions. The value of n is
(A) 12 (B) 14
(C) 16 (D) 18
Answer: B
Number of value adjustment factors(or degrees of influence ) are based on responses of 14 (Fi, i=1 to 14) questions.
FP = Count - total ×(0.65+0.01×∑(Fi)), Where count total = sum of all FP entries.
45. Assume that the software team defines a project risk with an 80% probability of occurrence of risk in the following manner :
Only 70 per cent of the software components scheduled for reuse will be integrated into the application and the remaining functionality will have to be custom developed. If 60 reusable components were planned with an average component size of 100 LOC and software engineering cost for each LOC of $ 14, then the risk exposure would be
(A) $ 25,200 (B) $ 20,160
(C) $ 17,640 (D) $ 15,120
Answer: B
In the application,
- Number of reusable components planned =60
- Part of reusable components actually included=70%
- Number of components developed freshly = 30% of 60=18
- Development cost = 18 x 100 x 14$
- Probability of occurrence of risk =80%
- Risk exposure = 0.8 x 18 x 100 x 14 = 20160$
46. Maximum possible value of reliability is
(A) 100 (B) 10
(C) 1 (D) 0
Answer: C
The maximum possible value of reliability is 1. This value does not exceed further than 1 as defined as a rule.
47. ‘FAN IN’ of a component A is defined as
(A) Count of the number of components that can call, or pass control, to a component A
(B) Number of components related to component A
(C) Number of components dependent on component A
(D) None of the above
Answer: A
FAN IN =Number of components that can call or pass control to component A
FAN OUT=Number of components that are called by component A
48. Temporal cohesion means
(A) Coincidental cohesion
(B) Cohesion between temporary variables
(C) Cohesion between local variables
(D) Cohesion with respect to time
Answer: D
Temporal cohesion is when parts of a module are grouped by when they are processed - the parts are processed at a particular time in program execution (e.g. a function which is called after catching an exception which closes open files, creates an error log, and notifies the user).
49. Various storage devices used by an operating system can be arranged as follows in increasing order of accessing speed :
(A) Magnetic tapes → magnetic disks → optical disks → electronic disks → main memory → cache → registers
(B) Magnetic tapes → magnetic disks → electronic disks → optical disks → main memory → cache → registers
(C) Magnetic tapes → electronic disks → magnetic disks → optical disks → main memory → cache → registers
(D) Magnetic tapes → optical disks → magnetic disks → electronic disks → main memory → cache → registers
Answer: D
The storage hierarchy is a ranking of storage devices based on several factors: access speed, capacity, cost per bit, and volatility.
- Registers - fastest access, highest cost/bit, low capacity, volatile.
- Cache - fast access, slower than register, low capacity.
- main memory - slower access than registers (faster than disks), lower cost/bit than registers (higher than disks), higher capacity than registers (lower than disks), volatile
- electronic disks - a.k.a. flash memory. slower access than main memory (faster than hard drives), lower cost/bit than main memory (higher than hard drives), higher capacity than main memory (lower than hard drives), nonvolatile
- magnetic disks - slower access than flash memory (faster than tapes), lower cost/bit than flash memory (higher than tapes), higher capacity than flash memory (lower than tapes), nonvolatile
- Optical disks - slower access than magnetic disk, low cost/bit.
-
Magnetic tapes - slowest access of all, highest capacity
50. How many disk blocks are required to keep a list of free disk blocks in a 16 GB hard disk with a 1 KB block size using a linked list of free disk blocks? Assume that the disk block number is stored in 32 bits.
(A) 1024 blocks (B) 16794 blocks
(C) 20000 blocks (D) 1048576 blocks
Answer: Marks are given to all
No. of disk blocks possible = 16GB/ 1KB = 16M disk blocks available
No. of disk block address possible to store in 1 disk block = 1kB/32bits = 256 address can be stored in 1 disk block
256 disk block address -> 1 disk block
16M disk block address -> x
x = 16M/256 = 65536...


 8+ registered
8+ registered 

