


























Introduction
The UGC NET, also known as the NTA-UGC-NET, is an examination used to determine eligibility for assistant professorships and Junior Research Fellowships at Indian universities and colleges. The National Testing Agency administers the exam on behalf of the University Grants Commission.
Now we will look at some of the questions that came in UGC NET Dec 2018 Paper II.
Also check Dec 2018 Paper II - Part 1, Dec 2018 Paper II - Part 2, and Dec 2018 Paper II - Part 3 here.
Questions with Solutions
76. .............. system call creates new process in Unix.
(1) create
(2) create new
(3) fork
(4) fork new
Solution) fork
Explanation) By copying the parent process image a new process is created by fork() system call.
77. An attribute A of datatype varchar(20) has the value ‘xyz’, and the attribute B of datatype char(20) has the value “lmnop”, then the attribute A has ............... spaces and attribute B has ............... spaces.
(1) 3,5
(2) 20,20
(3) 3,20
(4) 20,5
Solution) 3,20
Explanation) char(20) means, a variable is allocated with a complete space of 20.
78. Data warehouse contains ............... data that is never found in operational environment.
(1) Summary
(2) Encoded
(3) Encrypted
(4) Scripted
Solution) Summary
Explanation) A relational database called data warehouse is built for query and analysis rather than transaction processing. It usually contains historical data obtained from transaction data, but data from other sources can also be included.
The purpose is to generate statistical data that will aid decision-making.
79. .................. command is used to remove a relation from SQL database.
(1) Drop table
(2) Delete table
(3) Remove table
(4) Update table
Solution) Drop table
Explanation) To delete a table and all of its rows, use the drop table command. Use the drop table command followed by the tablename to delete an entire table, including all of its entries. Dropping a table is not the same as deleting all of its records.
80. Which of the following statement/s is/are true?
(i) Facebook has the world’s largest Hadoop Cluster.
(ii) Hadoop 2.0 allows live stream processing of Real time data.
Choose the correct answer from the code given below:
Code:
(1) (i) only
(2) (ii) only
(3) Both (i) and (ii)
(4) Neither (i) nor (ii)
Solution) Both (i) and (ii)
Explanation)
(i) Facebook has the largest Hadoop cluster in the world.
This assertion is correct. Hadoop clusters aid in data organisation and analysis in a computing environment. It increases data analysis speed. These clusters aid in improving throughput performance.
(ii) Hadoop 2.0 enables real-time data streaming processing.
The given assertion is correct. Hadoop 2.0 has numerous advantages over its predecessor. These are they:
Hadoop 2.0 enables real-time data stream processing.
Its ability to use MPI to process Terabytes and Petabytes of data stored in HDFS.
81. Data scrubbing is
(1) A process to reject data from the data warehouse and to create the necessary indexes.
(2) A process to load the data in the data warehouse and to create the necessary indexes.
(3) A process to upgrade the quality of data after it is moved into a data warehouse.
(4) A process to upgrade the quality of data before it is moved into a data warehouse.
Solution) A process to upgrade the quality of data before it is moved into a data warehouse.
Explanation)The process of modifying or eliminating data in a database that is erroneous, incomplete, incorrectly formatted, or duplicated is known as data scrubbing.
The architecture of the system should be able to cleanse data, record quality events, and measure and control data quality in the data warehouse.
82. Consider the relation schema R = (A,B,C,D,E,F) on which the following functional dependencies hold:
A → B
B, C → D
E → C
D → A
What are the candidate keys of R?
(1) AE and BE
(2) AE, BE and DE
(3) AEF, BEF and BCF
(4) AEF, BEF and DEF
Solution) AEF, BEF and DEF
Explanation)
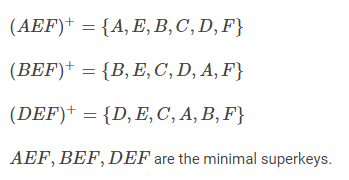
83. Consider the following sequence of two transactions on a bank account (A) with initial balance 20,000 that transfers 5,000 to another account (B) and then apply 10% interest.
(i) T1 start
(ii) T1 A old = 20,000 new 15,000
(iii) T1 B old = 12,000 new = 17,000
(iv) T1 commit
(v) T2 start
(vi) T2 A old = 15,000 new = 16,500
(vii) T2 commit
Suppose the database system crashes just before log record (vii) is written. When the system is restarted, which one statement is true of the recovery process?
(1) We must redo log record (vi) to set A to 16,500.
(2) We must redo log record (vi) to set A to 16,500 and then redo log records (ii) and (iii).
(3) We need not redo log records (ii) and (iii) because transaction T1 is committed.
(4) We can apply redo and undo operations in arbitrary order because they are idempotent.
Solution) We must redo log record (vi) to set A to 16,500 and then redo log records (ii) and (iii).
Explanation) We will redo all the committed transactions and uncommitted transactions as there are no checkpoints.
So, we will redo log record (vi) and then redo log records (ii) and (iii). So, (B) should be the answer.
84. Consider the following tables (relations):
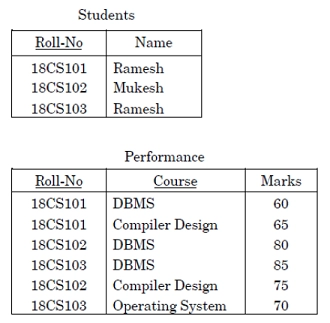
Primary keys in the tables are shown using underline. Now, consider the following query:
SELECT S.Name, Sum (P.Marks)
FROM Students S, Performance P
WHERE S.Roll-No = P.Roll-No
GROUP BY S.Name
The number of rows returned by the above query is
(1) 0
(2) 1
(3) 2
(4) 3
Solution) 2
Explanation) 2 rows will be returned by the below query.
SELECT S.Name, Sum (P.Marks)as Marks FROM Students, Performance P WHERE S.Roll-No=P.Roll-No GROUP BY S.Name
Since, here grouping is on S.Name, so, output will be as below:
Name Marks
Ramesh 280
Mukesh 155
We get 3 rows if the query will be as below.
SELECT S.Roll-No, S.Name, Sum (P.Marks) as Marks FROM Students, Performance P WHERE S.Roll-No=P.Roll-No GROUP BY S.Roll-No, S.Name
Output of the above query by using the given tables in the question output will be as below
Roll-No Name Marks
18CS101 Ramesh 125
18CS102 Mukesh 155
18CS103 Ramesh 155
85. A clustering index is defined on the fields which are of type:
(1) non-key and ordering
(2) non-key and non-ordering
(3) key and ordering
(4) key and non-ordering
Solution) non-key and ordering
Explanation) We define clustering index on feilds, as we are told. Because it is a non-key field, it will not have a distinct value for each record if the file's records are physically arranged on it. As a result, the clustering index is based on non-key and order fields.
86. A host is connected to a department network which is part of a university network. The university network, in turn, is part of the Internet. The largest network, in which the Ethernet address of the host is unique, is
(1) the Internet
(2) the university network
(3) the department network
(4) the subnet to which the host belongs
Solution) the Internet
Explanation) Ethernet address is MAC address(48 bits) is present on NIC and unique throughout the world so the correct answer is option a.
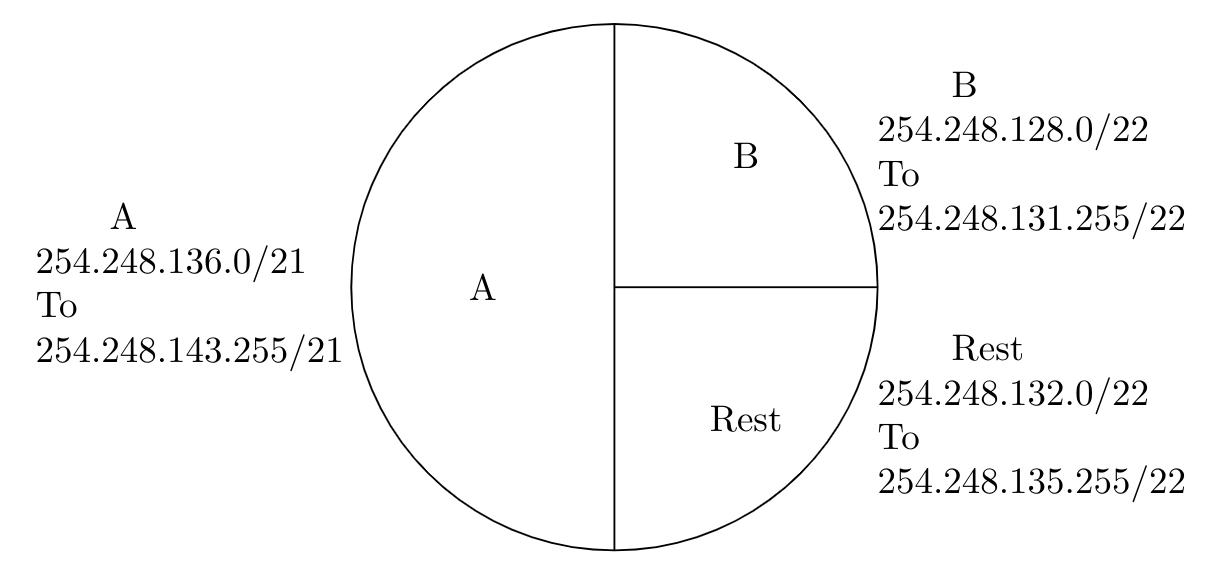
87. An Internet Service Provider (ISP) has following chunk of CIDR-based IP addresses available with it :245.248.128.9./20. The ISP wants to give half of this chunk of addresses to organization A and a quarter to organization B while retaining the remaining with itself. Which of the following is a valid allocation of addresses to A and B?
(1) 245.248.136.0/21 and 245.248.128.0/22
(2) 245.248.128.0/21 and 245.248.128.0/22
(3) 245.248.132.0/22 and 245.248.132.0/21
(4) 245.248.136.0/24 and 245.248.132.0/21
Solution) 245.248.136.0/21 and 245.248.128.0/22
Explanation)
88. Consider the following two statements:
S1: TCP handles both congestion and flow control
S2: UDP handles congestion but not flow control
Which of the following options is correct with respect to the above statements (S1) and (S2)?
Choose the correct answer from the code given below:
Code:
(1) Neither S1 nor S2 is correct
(2) S1 is not correct but S2 is correct
(3) S1 is correct but S2 is not correct
(4) Both, S1 and S2 are correct
Solution) S1 is correct but S2 is not correct
Explanation) 1: with the help of TCP window=>flow control and with the help of congestion window=> Congestion control
2: To control flow or congestion there are no field in UDP header .
3: TCP uses it to re-transmit out of order segments in order to solve the problem.
4: Nothing to do with flow regulation, just a slow start
You can read related articles such as Congestion Control in Computer Networks here.
89. Identify the correct sequence in which the following packets are transmitted on the network by a host when a browser requests a webpage from a remote server, assuming that the host has just been restarted.
(1) HTTP GET request, DNS query, TCP SYN
(2) DNS query, HTTP GET request, TCP SYN
(3) TCP SYN, DNS query, HTTP GET request
(4) DNS query, TCP SYN, HTTP GET request
Solution) DNS query, TCP SYN, HTTP GET request
Explanation) We need first DNS query to obtain the IP address. TCP performs three-way handshaking after obtaining the server's IP address. Finally, the HTTP GET request has been completed.
90. Suppose that everyone in a group of N people wants to communicate secretly with (N−1) other people using symmetric key cryptographic system. The communication between any two persons should not be decodable by the others in the group. The number of keys required in the system as a whole to satisfy the confidentiality requirement is
(1) N(N−1)
(2) N(N−1)/2
(3) 2N
(4) (N−1)2
Solution) N(N−1)/2
Explanation) The structure of an undirected complete graph with N vertices is the problem. The solution is n(n-1)/2, which is the number of edges.
91. An agent can improve its performance by
(1) Perceiving
(2) Responding
(3) Learning
(4) Observing
Solution) Learning
Explanation) An agent can develop by preserving prior states in which it existed previously, allowing it to learn to respond better in similar situations in the future.
92. Which of the following is true for a semi-dynamic environment?
(1) The environment may change while the agent is deliberating.
(2) The environment itself does not change with the passage of time but the agent’s performance score does.
(3) Even if the environment changes with the passage of time while deliberating, the performance score does not change.
(4) Environment and performance score, both change simultaneously.
Solution) The environment itself does not change with the passage of time but the agent’s performance score does.
Explanation) "A semidynamic environment is one in which the agent's performance score does not change over time but the environment does."
93. Consider the following terminology and match List I with List II and choose the correct answer from the code given below.
b = branching factor
d = depth of the shallowest solution
m = maximum depth of the search tree
l = depth limit
List I List II
(Algorithms) (Space Complexity)
(a) BFS search (i) O(bd)
(b) DFS search (ii) O(bd)
(c) Depth-limited search (iii) O(bm)
(d) Iterative deepening search (iv) O(bl)
Code:
(1) (a) – (i), (b)-(ii), (c)-(iv), (d)-(iii)
(2) (a) – (ii), (b)-(iii), (c)-(iv), (d)-(i)
(3) (a) – (iii), (b)-(ii), (c)-(iv), (d)-(i)
(4) (a) – (i), (b)-(iii), (c)-(iv), (d)-(ii)
Solution) (a) – (ii), (b)-(iii), (c)-(iv), (d)-(i)
Explanation) Everything is related to DFS & BFS and questions are based on the space complexity of those.
Answer :-
BFS → O(bd) worst case space complexity
DFS → O(bm) worst case space complexity
Depth - Limited Search → O(bl)
Iterative deepening Search → O(bd)
94. Match List I with List II and choose the correct answer from the code given below.
List I List II
(a) Greedy Best-First Search (i) Selects a node for expansion if optimal path to that node has been found
(b) A* Search (ii) Avoids substantial overhead associated with keeping the sorted queue of nodes
(c ) Recursive Best-First Search (iii) Suffers from excessive node generation
(d) Iterative-deepening A* Search (iv) Time complexity depends on the quality of heuristic.
Code:
(1) (a) – (i), (b)-(ii), (c)-(iii), (d)-(iv)
(2) (a) – (iv), (b)-(i), (c)-(ii), (d)-(iii)
(3) (a) – (iv), (b)-(iii), (c)-(ii), (d)-(i)
(4) (a) – (i), (b)-(iv), (c)-(iii), (d)-(ii)
Solution) (a) – (i), (b)-(iv), (c)-(iii), (d)-(ii)
Explanation)
(a) Greedy Best-First Search
The path that appears best at that moment s selected by the Greedy best-first search algorithm. It is the combination of breadth-first search algorithms and depth-first search.
(b) A* Search
Due to its completeness, optimality, and efficiency, A* is a graph traversal and path search method that is widely utilised in many domains of computer science.
(c) Recursive Best-First Search
RBFS (recursive best-first search) is a broad heuristic search method that extends frontier nodes in best-first order, but saves memory by finding the next node to expand using stack-based backtracking rather than selecting from an Open list.
(d) Iterative-deepening A* Search
Deepening in stages A* (IDA*) is a graph traversal and route search technique that can discover the shortest path in a weighted network between a specified start node and any member of a set of goal nodes.
95. Consider the following statements:
S1: A heuristic is admissible if it never overestimates the cost to reach the goal.
S2: A heuristic is monotonous if it follows triangle inequality property.
Which of the following is true referencing the above statements?
Choose the correct answer from the code given below:
Code:
(1) Neither of the statements S1 and S2 are true
(2) Statement S1 is false but statement S2 is true
(3) Statement S1 is true but statement S2 is false
(4) Both the statements S1 and S2 are true
Solution) Both the statements S1 and S2 are true
Explanation)
A heuristic function is said to be acceptable if it never overestimates the cost of achieving the goal, that is, if the cost it estimates to achieve the goal is not greater than the lowest possible cost from the current point in the path.
S1 is TRUE.
To be consistent or monotone, a heuristic must explicitly and implicitly fulfill the triangle inequality both explicitly and implicitly. The triangle inequality states that the sum of any two sides of a triangle must be >= length of the triangle's remaining side. Suppose a heuristic function's estimate is always less than or equal to the predicted distance from any neighboring vertex to the target, plus the cost of reaching that neighbor. In that case, it is said to be consistent or monotone.
S2 is TRUE.
96. Consider the following statements related to AND-OR Search algorithm.
S1: A solution is a subtree that has a goal node at every leaf.
S2: OR nodes are analogous to the branching in a deterministic environment.
S3: AND nodes are analogous to the branching in a non-deterministic environment.
Which of the following is true referencing the above statements?
Choose the correct answer from the code given below:
Code:
(1) S1 – False, S2 – True, S3 – True
(2) S1 – True, S2 – True, S3 – False
(3) S1 – True, S2 – True, S3 – True
(4) S1 – False, S2 – True, S3 – False
Solution) S1 – True, S2 – True, S3 – True
Explanation) AND OR search algorithm is completely different from other algorithms in that in order to reach the final goal state, it finds a goal node at each state. Its work environment is non deterministic.
And OR search algorithm works in the following way:
1) It finds a solution tree of subtrees.
2) The root of the subtrees is contained in the solution tree.
3) If a non-terminal AND node is in solution and subtree tree then all non terminal’s children are in solution tree.
4) If a non-terminal OR node is in solution and subtree tree then exactly one of non terminal’s children are in solution tree.
AND OR search tree can contain nodes that root identical subtrees (sub problems with identical optimal solutions which can be unified. Search tree becomes a graph and its size becomes smaller, when unifiable nodes are merged.
97. Consider the following minimax game tree search
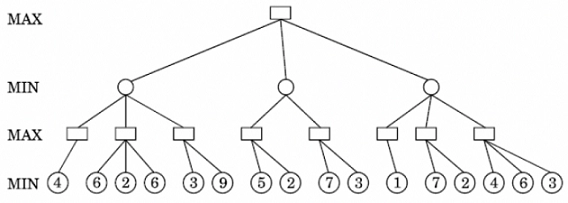
What will be the value propagated at the root?
(1) 3
(2) 4
(3) 5
(4) 6
Solution) 5
Explanation)
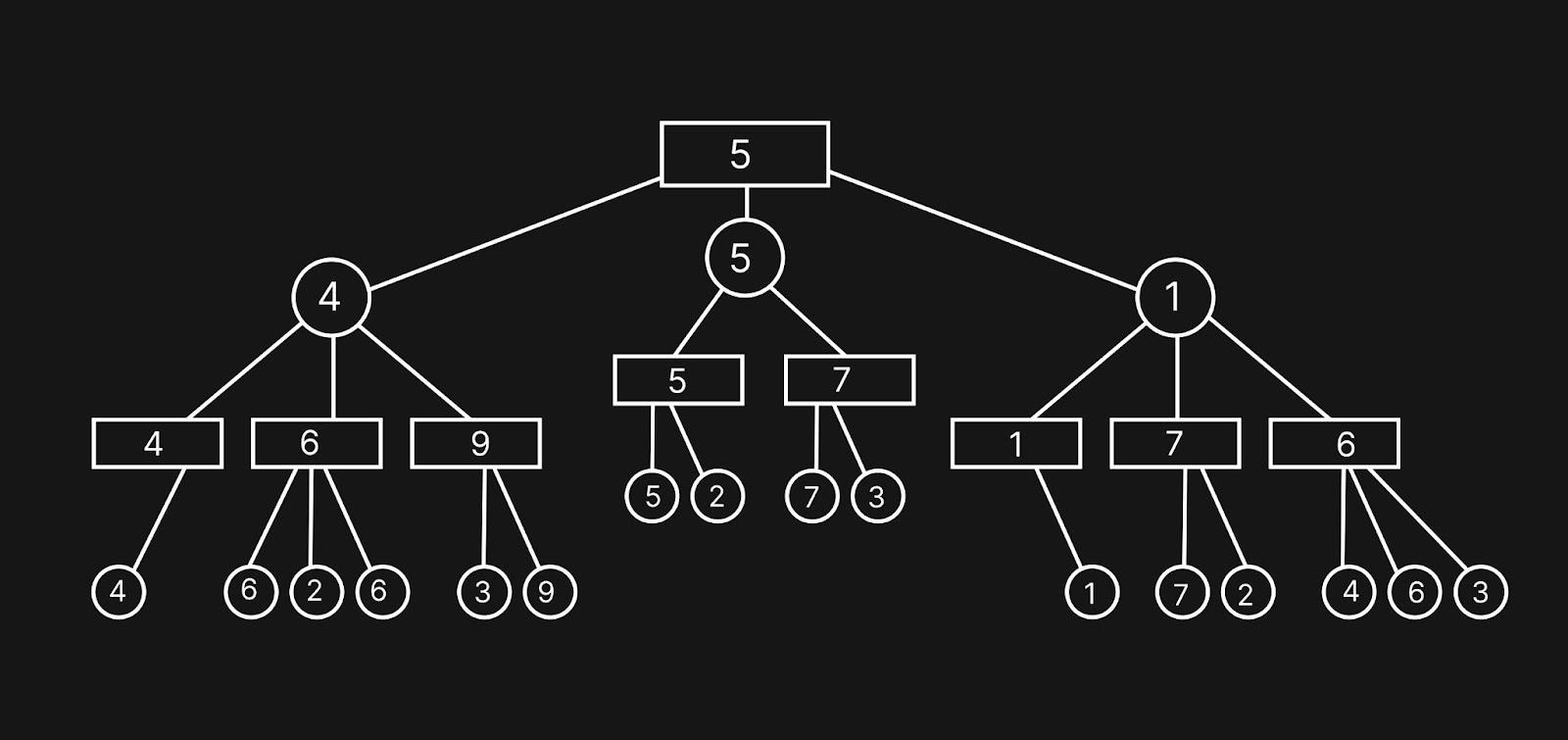
98. Consider a vocabulary with only four propositions A, B, C and D. How many models are there for the following sentence?
¬A ∨ ¬B ∨ ¬C ∨ ¬D
(1) 7
(2) 8
(3) 15
(4) 16
Solution) 15
Explanation) We have four variables A, B, C, D in the question. Therefore 2^4 = 16.
From 0 to 15 models exist, but one is 0, so 15 is the correct answer.
99. Consider the sentence below:
“There is a country that borders both India and Nepal”
Which of the following represents the above sentence correctly?
(1) ∃c Country(c) ∧ Border(c,India) ∧ Border(c,Nepal)
(2) ∃c Country(c) ⇒ [Border(c,India) ∧ Border(c,Nepal)]
(3) [∃c Country(c)] ⇒ [Border(c,India) ∧ Border(c,Nepal)]
(4) ∃c Border(Country(c),India) ∧ Nepal)
Solution) ∃c Country(c) ∧ Border(c,India) ∧ Border(c,Nepal)
Explanation) It is a boolean logic:
Either there will be such a country (1) or no such country (0).
We have two variables; Nepal and India.
The AND operation will give TRUE only if Border(c,India) is (1) and Border(c,Nepal) is (1).
And if we have one of the final two variables, the only scenario where TRUE(1) is returned is when we have AND with Country (1).
100. A full joint distribution for the Toothache, Cavity and Catch is given in the table below.
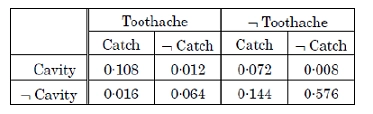
What is the probability of Cavity, given evidence of Toothache?
(1) <0.2,0.8>
(2) <0.4,0.8>
(3) <0.6,0.8>
(4) <0.6,0.4>
Solution) <0.6,0.4>
Explanation)




 9+ registered
9+ registered 

