


























Introduction
UGC NET Exam is one of the popular exams for people interested in research in India. Previous Year Questions are an excellent option to learn about the exam pattern. By solving the PYQs, you will get a basic idea about your preparation. You can evaluate your weak areas and work on them to perform better in the examination. In this article, we have given the questions of UGC NET 2013 December Paper-II. We have also explained every problem adequately to help you learn better.
Note: This article contains Q.No. 26 to Q.No. 50 out of the 50 questions asked in NET December 2013 paper II. The solution to Q.No. 01 to Q.No. 25 can be found in the December 2013 Paper-II Part-1 article.
Questions from 26 to 50
(1) Given the following statements: S1: SLR uses follow information to guide reductions. In the case of LR and LALR parsers, the lookaheads are associated with the items, and they make use of the left context available to the parser. S2: LR grammar is a larger subclass of context-free grammar as compared to that SLR and LALR grammar. Which of the following is true?
(A) S1 is not correct, and S2 is not correct.
(B) S1 is not correct, and S2 is correct.
(C) S1 is correct, and S2 is not correct.
(D) S1 is correct, and S2 is correct.
Answer: D
The algorithm for constructing the SLR parsing table uses the following condition to take parsing action for state i:
If [A→α⋅] is in Ii, then set ACTION[i, a] to "reduce A→α" for all in FOLLOW (A); here, A may not be S'.
The "lookahead-LR" or "LALR" method is based on the LR(0) sets of items and has fewer states than other typical parsers that are based on the LR(1) items. If we carefully introduce lookaheads into the items that are LR(0), we can handle many grammars with the method of LALR than via the SLR method and after that, build the parsing tables which are no bigger than the SLR tables. LALR is the method of choice in most situations. So, S1 is correct.
In computer science, SLR grammars are the class of formal grammars that are accepted by the Simple LR parser. SLR grammars are a subset of all LALR(1) and a superset of all LR(0) grammars and LR(1) grammars. So, S2 is also correct.
(2) The context-free grammar for the language
L = {an bm | n ≤ m + 3, n ≥ 0, m ≥ 0} is
(A) S → aaa A; A → aAb | B, B → Bb | λ
(B) S → aaaA|λ, A → aAb | B, B → Bb | λ
(C) S → aaaA | aa A | λ, A → aAb | B, B → Bb| λ
(D) S → aaaA | aa A | aA | λ, A → aAb | B, B → Bb | λ
Answer: D
When m =0, n can be 0, 1,2,3 because n<=m+3
Such strings are λ, a, aa, aaa
A. Cannot produce a, aa
B. Cannot produce a, aa
C.Cannot produce a
D. Satisfies all conditions.
hence D is the answer
(3) Given the following statements: S1: If L is a regular language, then the language {uv | u ∈ L, v ∈ LR} is also regular. S2 : L = {wwR} is regular language. Which of the following is true?
(A) S1 is not correct, and S2 is not correct.
(B) S1 is not correct, and S2 is correct.
(C) S1 is correct, and S2 is not correct.
(D) S1 is correct, and S2 is correct.
Answer: C
If L is a regular, then reversal of L is also regular. Hence u and v are regular. Concatenation of regular languages is regular. So, uv is also regular.
S1 is right because, to find wwR, we need to understand what is w. Regular grammar is checked by finite Automata, which have no memory (stack). To find wwR, we need at least NPDA.
S2 is incorrect.
(4) The process of assigning load addresses to the various parts of the program and adjusting the code and data in the program to reflect the assigned addresses is called _______.
(A) Symbol resolution
(B) Parsing
(C) Assembly
(D) Relocation
Answer: D
Relocation is a process in which we replace symbolic references or names of libraries with actually usable addresses that are in the memory before running a program.
(5) Which of the following derivations does a top-down parser use while parsing an input string? The input is scanned from left to right.
(A) Leftmost derivation
(B) Leftmost derivation traced out in reverse
(C) Rightmost derivation traced out in reverse
(D) Rightmost derivation
Answer: A
A top-down parser starts with the start symbol and generates the result. It parses a string using the leftmost derivation. We can state that the parsing starts from the start symbol.
(6) The dual of a Boolean expression is obtained by interchanging.
(A) Boolean sums and Boolean products
(B) Boolean sums and Boolean products or interchanging 0’s and 1’s
(C) Boolean sums and Boolean products and interchanging 0’s & 1’s
(D) Interchanging 0’s and 1’s
Answer: C
Boolean duals are generated by simply replacing AND's with OR, OR's with AND's, ‘1’s with ‘0’s, and ‘0’s with ‘1’s. Variables and their complements are left alone.
(7) Given that (292)10 = (1204)x in some number system x. The base x of that number system is
(A) 2 (B) 8
(C) 10 (D) None of the above
Answer: D
(292)10 = (1204)x
2*102 + 9*10 + 2 = x3 + 2*x2 + 0 + 4
200 + 90 + 2 = x3 + 2x2 + 4
x3 + 2x2 - 288 = 0
solution for x = 6
none of the option satisfy the equation.
(8) The sum of products expansion for the function
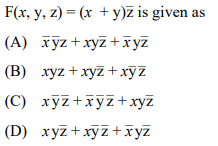
Answer: D
xyz' + xy'z' +x'yz'
z'(xy + x'y + xy')
z' (xy'+ y) [xy + x'y = y(x +x') = y]
xz'(z+y)
(9) Let P(m, n) be the statement “m divides n,” where the universe of discourse for both the variables is the set of positive integers. Determine the truth values of each of the following propositions :
I. ∀m ∀n P(m, n),
II. ∃m ∀n P(m, n)
(A) Both I and II are true (B) Both I and II are false
(C) I – false & II – true (D) I – true & II – false
Answer: C
Statement 1 says that all integer divide all integers, which is false.
Statement 2 say that there exists an integer that divides all integers.
Integer 1 divides all numbers.
Statement 2 is true.
(10) Big – O estimate for f(x) = (x + 1) log(x2 + 1) + 3x2 is given as
(A) O(x log x)
(B) O(x2)
(C) O(x3)
(D) O(x2 log x)
Answer: B
(x+1)log(x2+1) can be reduced to x log x2 as addition of a constant term can be truncated.
Therefore, x log x2 = 2x log x = O(x log x)
f(x) = max ( complexity of (x+1)log(x2+1) , complexity of x2) = max (O(x log x), O(x 2) = O(x 2)
(11) How many edges are there in a forest of t-trees containing a total of n vertices ?
(A) n + t (B) n – t
(C) n ∗ t (D) nt
Answer: B
In each tree, we have k-1 edges for k vertices. So, for t trees with total n vertices (all trees are disconnected in a forest), we would have n-t edges.
(12) Let f and g be the functions from the set of integers to the set integers defined by f(x) = 2x + 3 and g(x) = 3x + 2. Then, the composition of f and g and g and f is given as
(A) 6x + 7, 6x + 11
(B) 6x + 11, 6x + 7
(C) 5x + 5, 5x + 5
(D) None of the above
Answer: A
Given f(x) = 2x + 3
g(x) = 3x + 2
(fog)(x)= f( g(x) )
f(g(x)) = f(3x + 2)= 2(3x+2)+3 = 6x+7
(gof)(x)= g(f(x))
g(f(x)) = g(2x+3) = 3(2x+3)+2 = 6x+11
Hence,Option(A)6x + 7 ,6x+11.
(13) If n and r are non-negative integers and n ≥ r, then p(n + 1, r) equals to
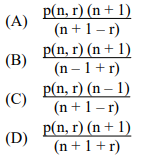
Answer: A
p(n, r) = n!/(n-r)!
p( n+1, r) = (n+1)!/(n+1-r)!
= (n+1) n!/(n+1-r)(n-r)!
= P(n, r)(n+1)/(n+1-r)
(14) A graph is non-planar if and only if it contains a subgraph homomorphic to
(A) K3, 2 or K5 (B) K3, 3 and K6
(C) K3, 3 or K5 (D) K2, 3 and K5
Answer: C
According to Kuratowski's theorem, a finite graph is said to be planar if and only if it does not have a subgraph that is a subdivision of the K5 (the complete graph on the 5 vertices) or of K3,3 (complete bipartite graph on 6 vertices, 3 of which connect to each of the other 3, also known as the utility graph).
Hence,Option(C)K3,3 or K5.
(15) Which of the following statements are true?
I. A circuit that adds two bits, producing a sum bit and a carry bit is called half adder.
II. A circuit that adds two bits, producing a sum bit and a carry bit is called full adder.
III. A circuit that adds two bits and a carry bit producing a sum bit and a carry bit is called full adder.
IV. A device that accepts the value of a Boolean variable as input and produces its complement is called an inverter.
(A) I & II (B) II & III
(C) I, II, III (D) I, III & IV
Answer: D
Statements I, II, and IV are true, and II is false. So, the correct answer will be the D option.
(16) Active X controls are Pentium binary programs that can be embedded in ________.
(A) Word pages (B) URL pages
(C) Script pages (D) Web pages
Answer: D
Active X controls are the Pentium binary program that can be embedded in a web page. ActiveX control is a component program object that can be re-used by many other application programs inside a computer or among computers within a network. The technology that is used for creating ActiveX controls is a part of Microsoft's overall ActiveX technologies, an important part of which is the Component Object Model (COM).
(17) Match the following :
List – I List – II
a. Wireless Application Environment i. HTTP
b. Wireless Transaction Protocol ii. IP
c. Wireless Datagram Protocol iii. Scripts
d. Wireless iv. UDP
Codes :
a b c d
(A) ii iv i iii
(B) iv iii ii i
(C) iv iii i ii
(D) iii i iv ii
Answer: D
a. Wireless application: Full application can be made using scripts -->iii
b. Wireless transaction: HTTP is used for this -->i
c. Wireless datagram protocol --> UDP can be used for this
d. Wireless --> leftover is IP
(18) Which of the following is widely used inside the telephone system for long-haul data traffic ?
(A) ISDN (B) ATM
(C) Frame Relay (D) ISTN
Answer: B
ATM is the core protocol that is used over the SONET/SDH backbone of the public switched telephone network and ISDN.
(19) The document standards for EDI were first developed by large business house during the 1970s and are now under the control of the following standard organisation :
(A) ISO (B) ANSI
(C) ITU-T (D) IEEE
Answer: B
The document standards for the EDI were initially developed by the large business houses during the 1970s and are now under the control of the American National Standards Institute(ANSI).
(20) Electronic Data Interchange Software consists of the following four layers :
(A) Business application, Internal format conversion, Network translator, EDI envelope
(B) Business application, Internal format conversion, EDI translator, EDI envelope
(C) Application layer, Transport layer, EDI translator, EDI envelope
(D) Application layer, Transport layer, IP layer, EDI envelope
Answer: B
The four layers of EDI software that are mentioned here allow the exchange of documents between 2 organizations over a VAN (value-added network).
(21) Consider a preemptive priority based scheduling algorithm based on dynamically changing priority. Larger priority number implies higher priority. When the process is waiting for the CPU in the ready queue (but not yet started execution), its priority changes at a rate a = 2. When it starts running, its priority changes at a rate b = 1. All the processes are assigned priority value 0 when they enter the ready queue. Assume that the following processes want to execute:
Process ID Arrival Time Service Time
P1 0 4
P2 1 1
P3 2 2
P4 3 1
The time quantum q = 1. When two processes want to join the ready queue simultaneously, the process which has not executed recently is given priority. The finish time of processes P1, P2, P3 and P4 will respectively be
(A) 4, 5, 7 and 8 (B) 8, 2, 7 and 5
(C) 2, 5, 7 and 8 (D) 8, 2, 5 and 7
Answer: B
The processes that want to be executed are :
Process ID ArrivalTime Service time
P1 0 4
P2 1 1
P3 2. 2
P4 3. 1
Time Priority
0 p1=1,
1 p2=1,p1=2.
2 P2=2,p1=2,p3=0
3 P1=1,p3=2,p4=0
4 P3=1,p1=2,p4=2
5 P1=1,p3=2,p4=2
Gantt chart
0----p1---1-----p2----2-----p1-----3------p3---4--—p4—5----p1-----6------p3------7 -----p1----8.
P1 finishes at 8.
P2 at 2
P3 at 7
P4 at 5.
(22) The virtual address generated by a CPU is 32 bits. The Translation Look-aside Buffer (TLB) can hold a total of 64 page table entries and a 4-way set associative (i.e. with 4- cache lines in the set). The page size is 4 KB. The minimum size of TLB tag is
(A) 12 bits (B) 15 bits
(C) 16 bits (D) 20 bits
Answer: C
Page size is 4KB ,so offset bits are 12 bits.
Remaining bits of virtual address 32 - 12 = 20 bits will be used for indexing.
number of sets = 64/4 = 16 (4-way set) => 4 bits.
So tag bits = 20 - 4 = 16 bits.
(23) Consider a disk queue with request for input/output to block on cylinders 98, 183, 37, 122, 14, 124, 65, 67 in that order. Assume that disk head is initially positioned at cylinder 53 and moving towards cylinder number 0. The total number of head movements using Shortest Seek Time First (SSTF) and SCAN algorithms are respectively
(A) 236 and 252 cylinders
(B) 640 and 236 cylinders
(C) 235 and 640 cylinders
(D) 235 and 252 cylinders
Answer: All answers are incorrect
All options are incorrect; mark all because the correct answer will be 236 & 236. According to SCAN 37 from 53, then to 14 and then to 0 (23+16+14=53), now the direction will be reversed so 0 to 65 then again to 67 then again to 98,122,124,183 (2+65+31+24+2+59=183) and total head movements will be =183+53=236
According to SSTF, 65 from 53 then again to 67 then again 37 , 14, 98, 122, 124, 183 (finally so head movement= 12+2+30+23+84+24+2+59=236)
(24) How much space will be required to store the bitmap of a 1.3 GB disk with 512 bytes block size ?
(A) 332.8 KB (B) 83.6 KB
(C) 266.2 KB (D) 256.6 KB
Answer: A
We need a bit for each block. Number of blocks = disk size/ block size
= 1.3 GB / 512 B
This will give the size of the bit-map in bits. And to get the byte size, we need to divide it by 8, and so we get 332.8 KB. For the disk size, GigaByte is taken as 1024*1024*1024 bytes, and for KB, it is 1024 bytes.
(25) Linux operating system uses
(A) Affinity Scheduling
(B) Fair Preemptive Scheduling
(C) Hand Shaking
(D) Highest Penalty Ratio Next
Answer: B
Linux Operating System uses Fair Preemptive Scheduling.
FAQs
What is the UGC NET exam?
UGC NET is a national-level exam organized by UGC to determine the eligibility of the candidates for lectureship and JRF.
What is the maximum number of attempts for the UGC NET examination?
There is no bar on the number of attempts of this examination. Candidates can appear for the examination as long as they are eligible.
How can solving PYQs help in my exam preparation?
Solving PYQs will give you a good idea about the exam pattern and help you identify your weak topics to prepare them better for the examination.
How many papers are there in the UGC NET exam?
There are two papers, and the candidates get 3 hours for both papers. There are 150 questions in UGC NET combining both papers.


 18+ registered
18+ registered 

