Get a skill gap analysis, personalised roadmap, and AI-powered resume optimisation.
Introduction
Hey Readers!!
Just imagine you are working on a database, and while entering the data in your database, you've added the same data in multiple rows. Now what will you do?
The duplicity in the database will lead to the complexity of the database and increases the size of the database. To resolve this issue, we need to delete duplicate records in SQL.
In this article, you will get to learn different ways in which you can delete duplicate records in SQL.
So let us dive into the topic to explore more about it.
What are Duplicate Records?
Duplicate records or rows are the rows that are identical in the database. In simple terms, we can say that these are one or more records that represent the same object in the database.
For example, in a company's database, there are two Ram. One is Ram Kapoor, and the other one is Ram Malhotra, and they have the same DOB and joining date. While entering their details into the database. The manager has added the same surname after their names, which resulted in duplicate records. To resolve this, we have to delete the duplicate records.
Let us look at how we can delete duplicate records in SQL.
How to Find Duplicate Records in SQL?
We can find duplicate records in Sql using the GROUP BY and HAVING clauses. First, let us create a table with the following commands:
MySQL
MySQL
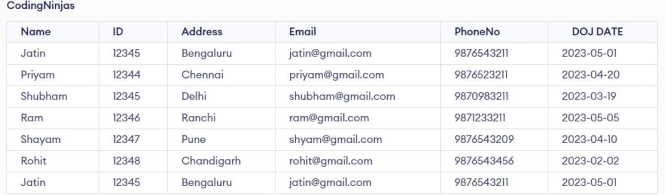
CREATE TABLE CodingNinjas ( Name varchar(90), ID int, Address varchar(255), Email varchar(90), PhoneNo int, DOJ DATE ); insert into CodingNinjas values('Jatin',12345,'Bengaluru','jatin@gmail.com',9876543211,'2023-05-01'); insert into CodingNinjas values('Priyam',12344,'Chennai','priyam@gmail.com',9876523211,'2023-04-20'); insert into CodingNinjas values('Shubham',12345,'Delhi','shubham@gmail.com',9870983211,'2023-03-19'); insert into CodingNinjas values('Ram',12346,'Ranchi','ram@gmail.com',9871233211,'2023-05-05'); insert into CodingNinjas values('Shayam',12347,'Pune','shyam@gmail.com',9876543209,'2023-04-10'); insert into CodingNinjas values('Rohit',12348,'Chandigarh','rohit@gmail.com',9876543456,'2023-02-02'); insert into CodingNinjas values('Jatin',12345,'Bengaluru','jatin@gmail.com',9876543211,'2023-05-01'); select * from CodingNinjas;
You can also try this code with Online MySQL Compiler
Here are some ways in which we can delete duplicate records in SQL.
Using the DISTINCT Keyword
Using the Group By and Having Clause
Using the INNER JOIN statement
Let us look at each one of them one by one.
1. Using the DISTINCT Keyword
As the name suggests, the DISTINCT keyword returns a number of distinct from one or more columns. To delete duplicate records in SQL, we can use DISTINCT in the following manner.
Step 1: Create the Table named CodingNinjas having details of the employees like their name, ID, address, email, phone number, and date of joining.
MySQL
MySQL
CREATE TABLE CodingNinjas ( Name varchar(90), ID int, Address varchar(255), Email varchar(90), PhoneNo int, DOJ DATE );
You can also try this code with Online MySQL Compiler
insert into CodingNinjas values('Jatin',12345,'Bengaluru','jatin@gmail.com',9876543211,'2023-05-01'); insert into CodingNinjas values('Priyam',12344,'Chennai','priyam@gmail.com',9876523211,'2023-04-20'); insert into CodingNinjas values('Shubham',12345,'Delhi','shubham@gmail.com',9870983211,'2023-03-19'); insert into CodingNinjas values('Ram',12346,'Ranchi','ram@gmail.com',9871233211,'2023-05-05'); insert into CodingNinjas values('Shayam',12347,'Pune','shyam@gmail.com',9876543209,'2023-04-10'); insert into CodingNinjas values('Rohit',12348,'Chandigarh','rohit@gmail.com',9876543456,'2023-02-02'); insert into CodingNinjas values('Jatin',12345,'Bengaluru','jatin@gmail.com',9876543211,'2023-05-01');
You can also try this code with Online MySQL Compiler
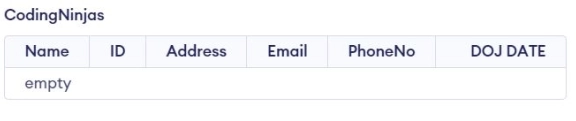
Step 4: Getting the unique values from the table by using the DISTINCT keyword.
SELECT DISTINCT * FROM CodingNinjas;
Explanation: In the above table, we have two records of Jatin. After using the DISTINCT keyword, it prints only one record of Jatin.
2. Using the Group By and Having Clause
Using the Group By and Having Clause, we can print the record occurring more than once in the database by using the count keyword.
SELECT COUNT(ID), Name, Email, PhoneNo, Address
FROM CodingNinjas
GROUP BY Name, Email, PhoneNo, Address
HAVING COUNT(ID) > 1;
Explanation: The Group By and Having Clause prints the occurrence of Jatin's record because the count of Jatin's is more than 1, as the count condition checks ID>1.
3. Using the INNER JOIN Statement
Let us create a table with the following commands:
MySQL
MySQL
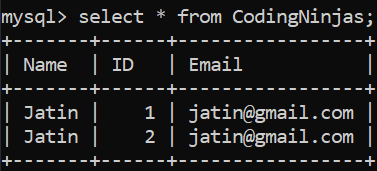
CREATE TABLE CodingNinjas ( Name varchar(90), ID int, Email varchar(90) ); insert into CodingNinjas values('Jatin', 1, 'jatin@gmail.com'); insert into CodingNinjas values('Jatin', 2, 'jatin@gmail.com');
You can also try this code with Online MySQL Compiler
Now, let us delete the duplicate entry for Jatin using the following commands:
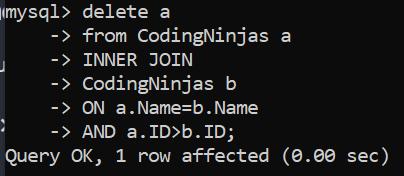
delete a
from CodingNinjas a
INNER JOIN
CodingNinjas b
ON a.Name=b.Name
AND a.ID>b.ID;
In the above command, we deleted the record using an INNER JOIN on the table itself(SELF JOIN) where the Name is the same, but the ID is different. The one with the bigger value of ID is deleted.
OUTPUT
Now, let us see our table with the following command:
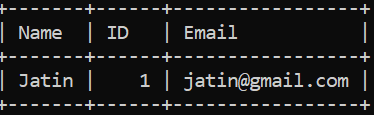
select * from CodingNinjas;
OUTPUT
We can see that there are no duplicate entries in the table now.
Frequently Asked Questions
How to delete duplicate records in SQL?
In SQL, we can delete duplicate records using various methods. We can use the DISTINCT keyword, the GROUP BY and the HAVING clause, or we can use the INNER JOIN statement for it.
How to delete duplicate records in SQL using subquery?
The outer query will delete the records from the table, which will not be a part of the result of the inner query. The inner query will give all the duplicate records of the table except for any one of them.
How to delete duplicate records in MySQL?
In MySQL, we can delete duplicate records using the SSELF JOINS, Common Table Expressions(CTE), Subqueries, temporary tables, and analytic functions. You can also view unique records by DISTINCT keyword, GROUP BY, and HAVING clauses.
What is the use of GROUP BY in SQL?
In SQL, the GROUP BY clause groups data based on one or more columns. It is commonly used with aggregate functions such as SUM, COUNT, AVG, MIN, and MAX to group rows with similar values together.
Conclusion
In this article, you have learned what duplicate records are in SQL and different ways to delete duplicate records in SQL. We hope this article helped you enhance your knowledge about different ways of deleting duplicate records in SQL. If you want to learn more, refer to these articles:


































 9+ registered
9+ registered 

