How Distributed Computing works?
The following are the most important functions of distributed computing:
- Sharing of resources - whether it is hardware, software, or data.
- Openness refers to how open the software is intended to be developed and shared with others.
- Concurrency is the ability of multiple machines to perform the same function at the same time.
- Scalability refers to how computing and processing capabilities add and subtract when distributed across multiple machines.
- Fault tolerance entails how easily and quickly failures in system components can be detected and recovered.
- Transparency refers to how much access a node has to locate and interact with other devices in the cluster.
Modern distributed methods have emerged to include autonomous processes that may run on the same physical machine but interact with each other by exchanging messages.
Types of Distributed System Architectures
Distributed applications and processes are typically built using one of the four architecture types listed below:
-
Client-server architecture:
Originally, distributed systems architecture included a server as a shared resource, such as a printer, database, or web server. It had multiple clients (for example, computer users) who decided when to use a common resource, how to use and display them, change data, and send it back to the webserver. Code repositories, such as git, are an example of where the knowledge is placed on the development companies committing changes to the code.
With the advent of web applications, distributed systems architecture has developed into:
- Three-tier architecture: In this architecture, clients are no longer required to be smart and can instead rely on a middle layer to handle processing and decision-making. This category includes the majority of the first web applications. The middle tier could be referred to as an agent because it receives requests from clients, which could be stateless, processes data, and then forwards it to the servers.
- Multi-tier architecture: Corporate web services pioneered the development of n-tier or multi-tier system architectures. These popularised application servers, contain business rules and interact with both data and presentation tiers.
- Peer-to-peer architecture: There is no centralized or special machine in this architecture doing the legwork and smart work. All decision-making and obligations are distributed among the machines involved, with each capable of acting as a client or server. Blockchain is an excellent example of this.
What is Big Data?
In a nutshell, Big Data is data that is extremely large and cannot be processed using standard tools. And in order to process such data, we need a distributed architecture. This information may be supervised or unsupervised.
In general, we divide data-handling issues into three categories:
Volume: We refer to a problem as Volume when it is connected to how we would market such massive amounts of data. Facebook, for example, handles more than 500 TB of data per day. Facebook has storage capabilities of 300 PB.
Velocity: When we try to handle a large number of requests per second, we refer to this as Velocity. As the number of requests received by Facebook or Google per second increases, so do the problems.
Variety: If the problem at hand or the data we are handling is complex, we refer to it as a variety problem.

Image source: Big Data
Distributed computing and Big Data
Because large amounts of data cannot be stored on a single system, numerous systems with specific memories are used in big data.
Big Data is defined as a massive dataset or set of massive datasets that cannot be filtered by traditional systems. Big Data has evolved into its own subject, encompassing the study of various tools, techniques, and frameworks rather than just data. MapReduce is a framework for developing applications that aid in the processing of large amounts of data on a large cluster of hardware.
Distributed computing with MapReduce
The MapReduce framework, along with the Hadoop file system HDFS, has been a key component of the Hadoop ecosystem since its beginnings.
Google used MapReduce to evaluate stored HTML content on websites by counting all HTML tags, words, and word combinations (for instance headlines). The outcome was being used to generate the Google Search page ranking. That's when everyone started boosting his website for Google searches. It was the birth of serious search engine optimization. That's the year 2004 at the time.
MapReduce, on the other side, processes data in two phases. There are two phases: the map phase and the reduce phase.
The framework is reading data from HDFS during the map phase. Each dataset is referred to as an input record. Then comes the reducing phase. The actual computation is completed and the results are saved during the reduce phase. The memory target can be a database, HDFS, or something else. The magic of MapReduce is in how the map-reduce phases are implemented and how they interact with one another.
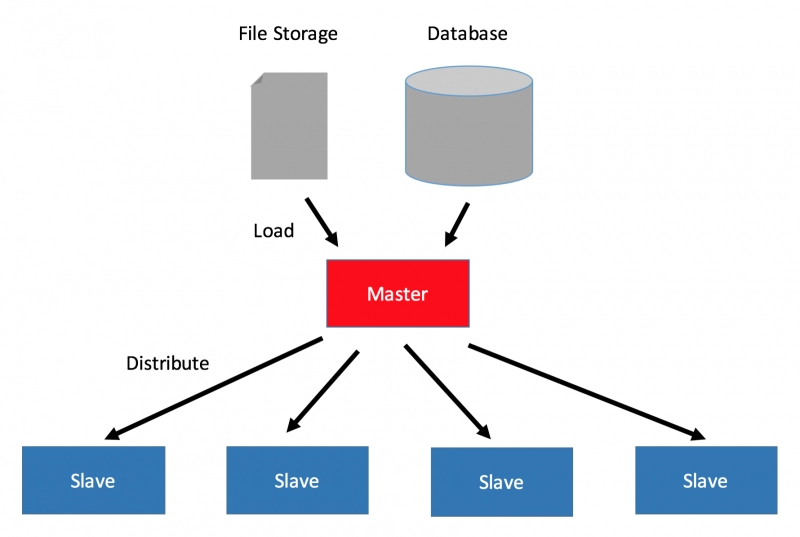
The map as well as reduced phases are run concurrently. That is, users have numerous map phases (mappers) and reduce phases (reducers) on your cluster machines that can run simultaneously. A picture describing the above point is shown below:
Why MapReduce?
Traditional data storage and retrieval systems rely on a centralized server. Standard database servers cannot handle such massive amounts of data. Furthermore, a centralized system provides too much of a bottleneck when processing multiple files at the same time.
Such bottlenecks are addressed by MapReduce. MapReduce will divide the task into small chunks and process each one separately by assigning them to different systems. After all of the parts have been processed and analyzed, the result of each workstation is collected in a single location, and an output dataset for the specific issue is prepared.
Big data demand meets solutions
In the late 1990s, search engine and Internet companies such as Google, Yahoo!, and Amazon.com were ready to broaden their business models by leveraging low-cost computing and storage hardware. These businesses required a new generation of software technologies to facilitate them monetizing the massive amounts of data they were collecting from customers. They needed to be able to process and analyze this data in real-time. And hence the demand is meeting the solution every time.
Frequently Asked Questions
How are Hadoop and Big Data related?
When we communicate about Big Data, we also talk about Hadoop. Hadoop is an open-source schema for storing, processing, and managing clusters of unstructured data to gain insights and knowledge. This is how Hadoop and Big Data are linked to one another.
Mention the core methods of Reducer.
A Reducer's primary methods are as follows:
1. setup(): setup is a method used to configure multiple metrics for the reducer.
2. reduce(): The primary operation of the reducer is reduce. This method's specific function includes defining the task that must be worked on for a distinguishable set of values that share a key.
3. cleanup(): This function is used to clean up or delete any momentary files or data left over from the reduce() task.
Explain the core components of Hadoop.
Hadoop's Core Components:
1. HDFS (Hadoop Distributed File System) – HDFS is Hadoop's primary storage system. HDFS is used to store a large amount of data. It is primarily intended for storing large datasets on commodity hardware.
2. Hadoop MapReduce – MapReduce is the Hadoop layer in charge of data processing. It submits a request to process structured and unstructured data already stored in HDFS. It is capable of parallel processing a large volume of data by dividing it into separate tasks. Processing is divided into two stages: Map and Reduce. The map is a stage in which data blocks are perused and made accessible to executors (computers/nodes/containers) for processing. Reduce is the stage in which all processed data is gathered and compiled.
3. YARN – YARN is the framework that is used to handle data in Hadoop. YARN manages resources and provides multiple data processing engines such as real-time broadcasting, data science, and batch processing.
Conclusion
To sum up this blog, we talked about distributed computing, its importance, how it works, and the various types. We also talked about Big Data and how it relates to distributed computing. We also learned how MapReduce is used in distributed computing and why MapReduce is the only option. Finally, we discussed the matter of demand meeting solutions.
Refer to our guided paths on Coding Ninjas Studio to upskill yourself in Data Structures and Algorithms, Competitive Programming, JavaScript, System Design, and many more! If you want to test your competency in coding, you may check out the mock test series and participate in the contests hosted on Coding Ninjas Studio! But if you have just started your learning process and looking for questions asked by tech giants like Amazon, Microsoft, Uber, etc; you must have a look at the problems, interview experiences, and interview bundle for placement preparations.
Nevertheless, you may consider our paid courses to give your career an edge over others!
Do upvote our blogs if you find them helpful and engaging!
Happy Learning!





























 23+ registered
23+ registered 

