



























Introduction
DFS, or Depth First Search, is one of the algorithms used for graph traversal.
The process of moving from one node (the source) to all other graph nodes is known as graph traversal. Different algorithms exist for graph traversal that may produce different orders of nodes. Depth First Search, commonly called DFS Algorithm, is one such algorithm, often written as a recursive function.
In this article, we will understand the introduction to the Depth First Search concept, examples, its approach, algorithm, and implementation in C++ and Java languages in detail.

Depth First Search Algorithm
Depth First Search is a graph traversal algorithm that searches along each branch completely before backtracking and continuing its search along other branches. This means each path is traversed along its depth from root to leaf completely before we move on to the next path. This is where the algorithm gets its name - Depth First Search.
Algorithm:
-
Start at the source. Make the source the current node. Mark it as visited.
-
For each child of the current node:
-
If it is visited, do not do anything. Continue.
-
If it is not visited, make the child node the current node and repeat Step 2.
-
If it is visited, do not do anything. Continue.
-
After this step has been done for all children, backtrack to the node above the current node (the parent of the current node), and continue step 2 for unvisited children.
-
Do this until all nodes have been marked as visited.
- In case there are nodes left over that could not be reached from the source node (in case of disconnected graph), we will perform DFS again taking each one of the unvisited nodes as the source.
Pseudocode
The pseudocode for Depth First Search would look like this.
// n = number of nodes
// visited = array of size n with all values false
//adj = adjacency list
//ans = empty answer array
DFS-Helper(node):
visited[node] = true;
ans.add(node);
for (child in adj[node]):
if (!visited[child]) DFS-Helper(child)
DFS():
for (i=0 to n;i=i+1):
if (!visited[i]):
DFS-Helper(i)
for (int node in ans):
print (node+" ")
As you can see, the for-loop in DFS-Helper will not go into its next iteration until the DFS-Helper call for its child node has concluded. This means the entire path from source to leaf node will be covered completely before we go to another path.
If this all sounds confusing, don't worry. Our walkthrough example will make it clear.
Walkthrough Example
The following image shows the example graph we are taking. It is an unweighted directed graph. The notation is mentioned on the top-left corner.
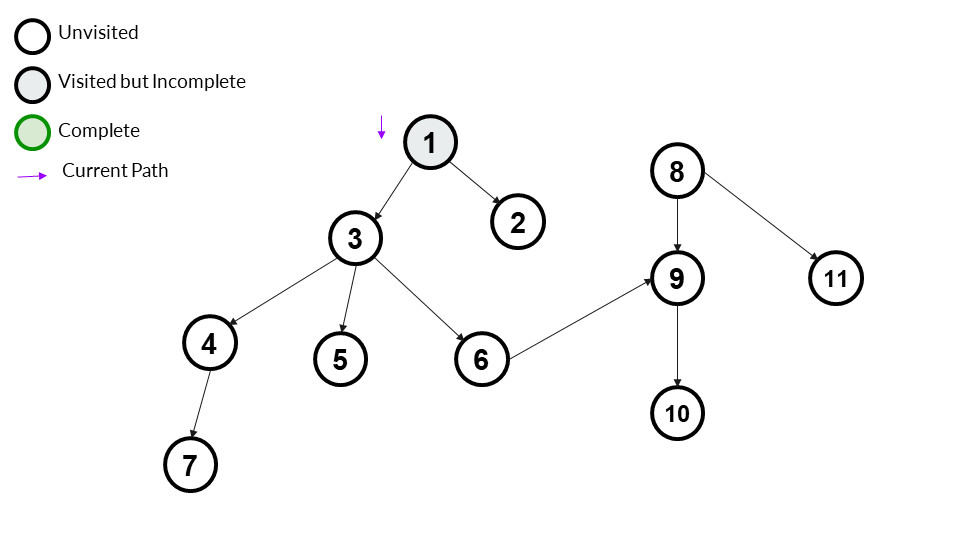
We will start our DFS by taking node 1 as the source. You may notice that vertice no 8 is not reachable from vertice 1 (source). This makes our graph disconnected. We start at source 1 and mark it visited (grey). Our answer array is currently [1].
Step 1
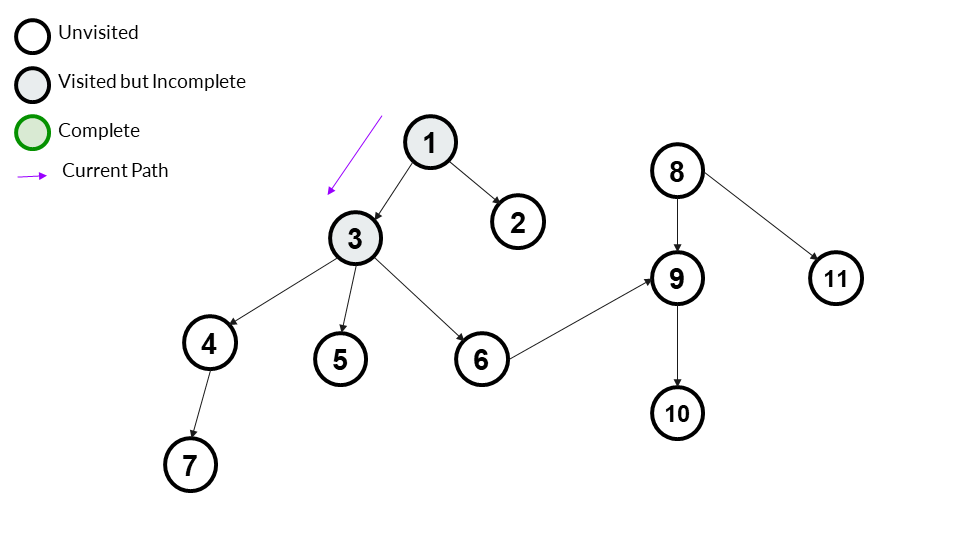
We go to a child of 1. We can choose any child (2 or 3). We choose 3 here, and go to it. We mark it as visited.
Answer Array - [1,3]
Step 2
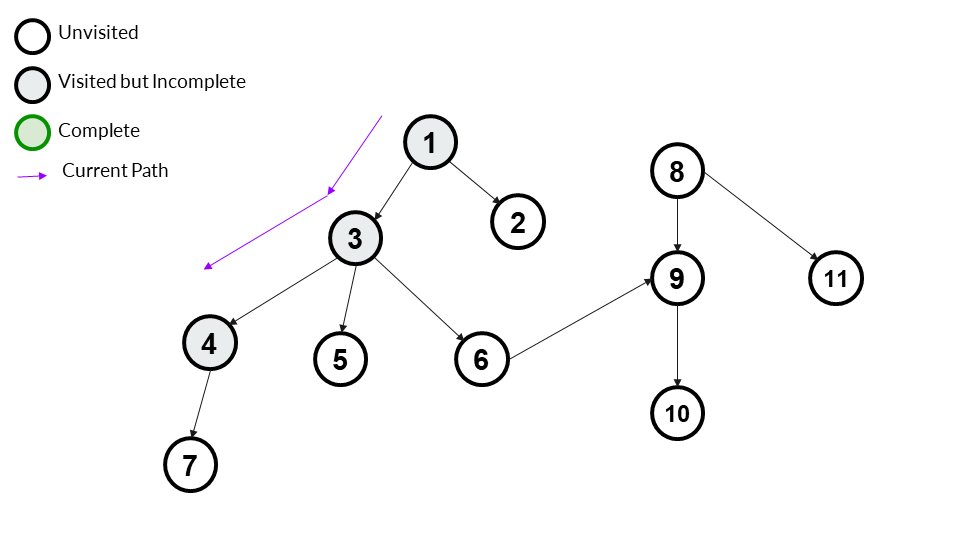
We choose a child of 3. Here we choose 4. We go to it and mark it as visited.
Answer Array - [1,3,4]
Step 3
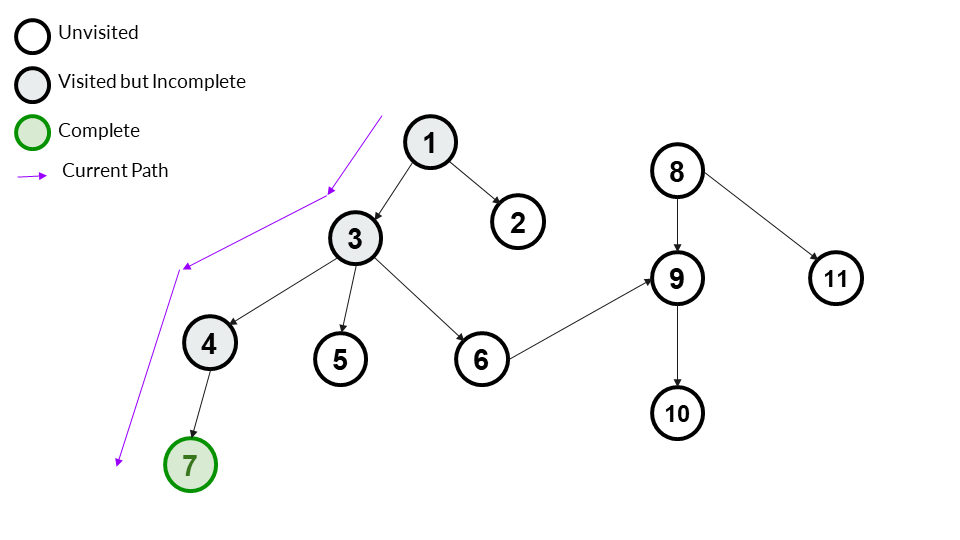
We choose a child of 4. 4 has only one child - 7. We go to it and mark it visited. As 7 has no children, we can also mark it as complete.
Answer Array - [1,3,4,7]
Step 4
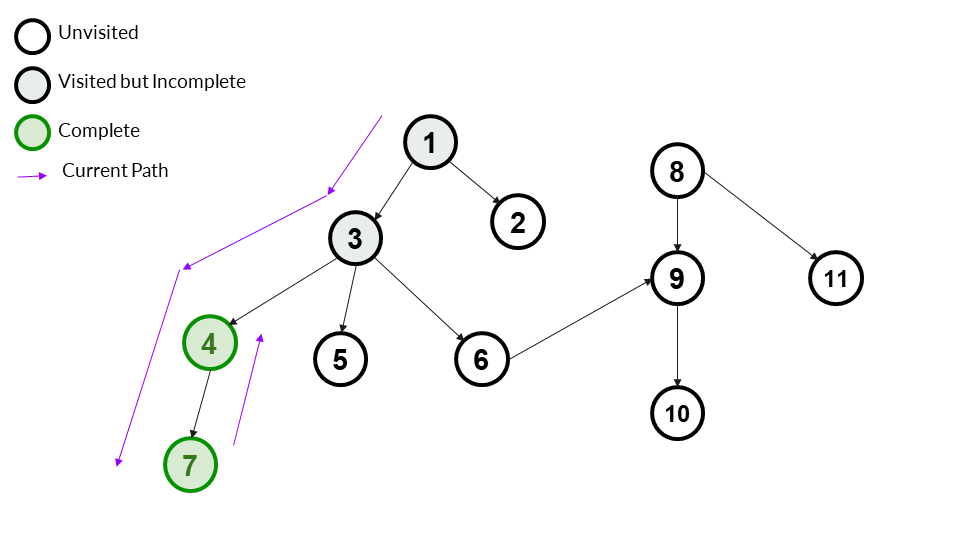
After completing 7, we now backtrack to its parent 4. 4 has no other children - so it is also complete. We mark it as complete.
Answer Array - [1,3,4,7]
We don't add 4 again to answer array. Nodes are added only once - when they are visited. Completion is only shown to make the concept clearer - it has no effect on the answer.
Step 5
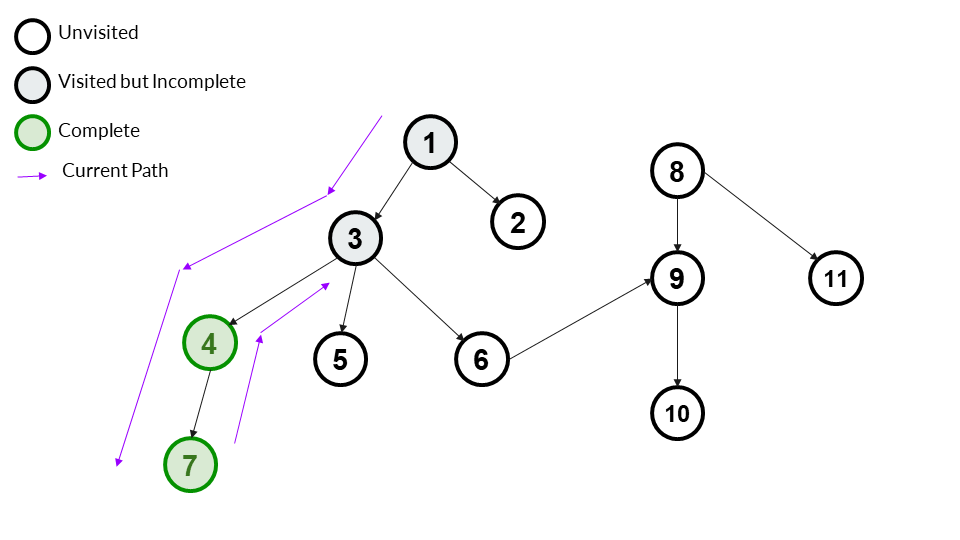
We backtrack to 3 after completing 4. 3 has more children that aren't complete, so we cannot mark it as complete yet.
Answer Array - [1,3,4,7]
Step 6
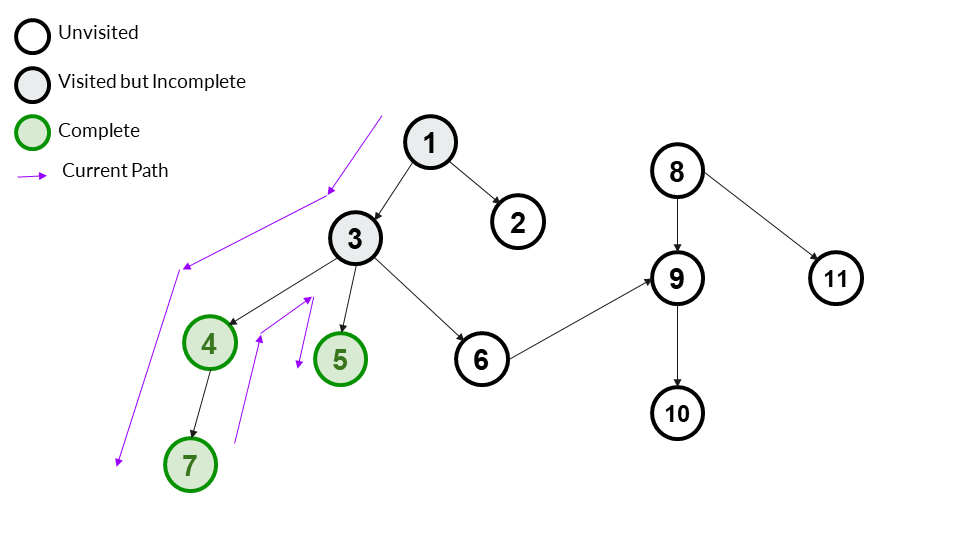
We choose a child of 3 - 5 in this case. We go to it and mark it as visited. As 5 has no more children, we can also mark it as complete.
Answer Array - [1,3,4,7,5]
We add 5 because it was visited and completed in this step. If it had been visited in a previous step, we would not add it here.
Step 7
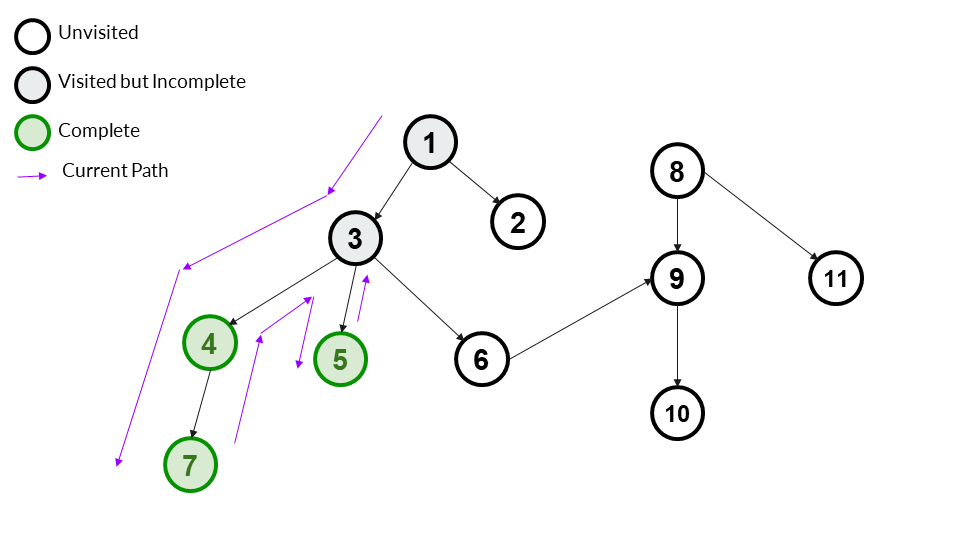
We backtrack to 3. It is still not complete, so we don't mark it as completed.
Step 8
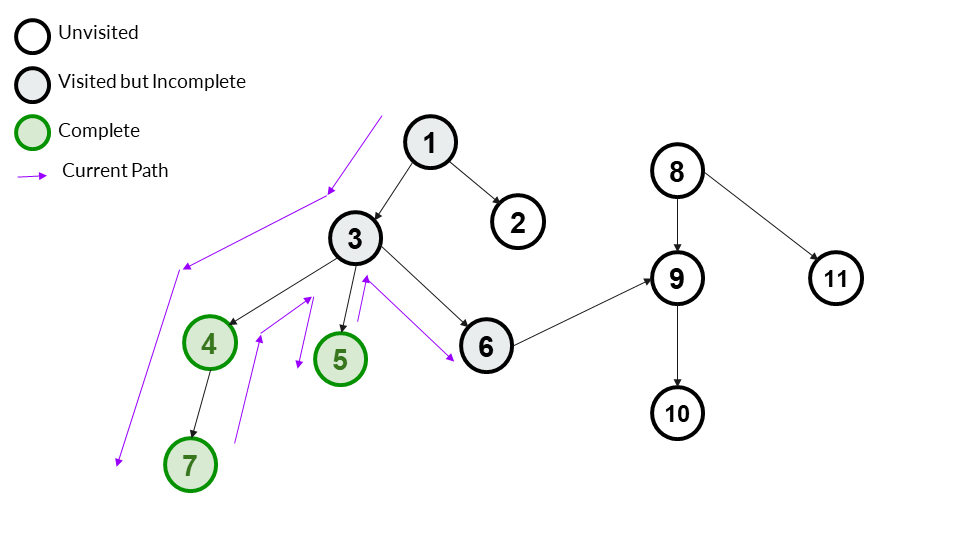
We go to a child of 3 - 6 is the only child left so we go to 6. We mark 6 as visited and add it to our answer array. It is not complete so we don't mark it as completed.
Answer Array - [1,3,4,7,5,6]
Step 9
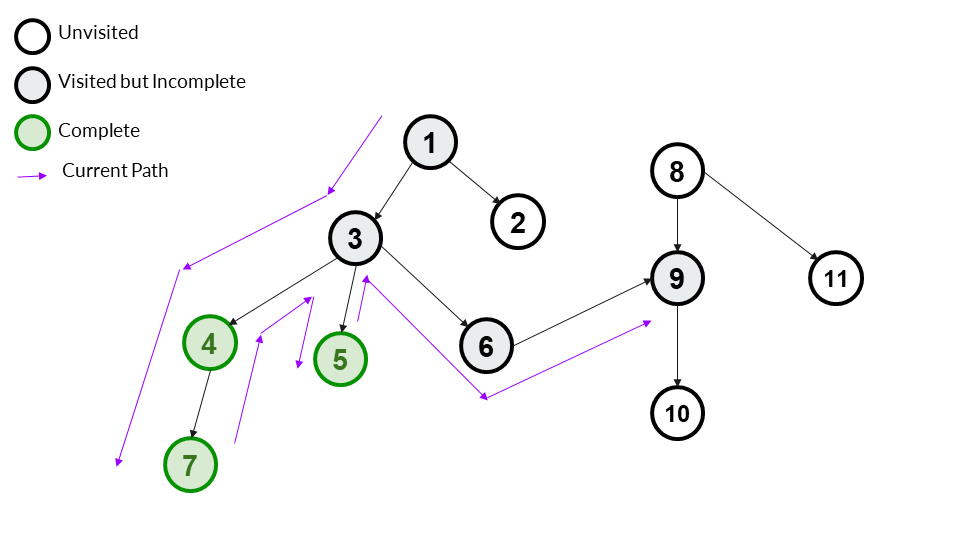
6 has only one child -9. We go to it and mark it as visited, also adding it to our answer array. It has one child, so we don't mark it as complete.
Answer Array - [1,3,4,7,5,6,9]
Step 10
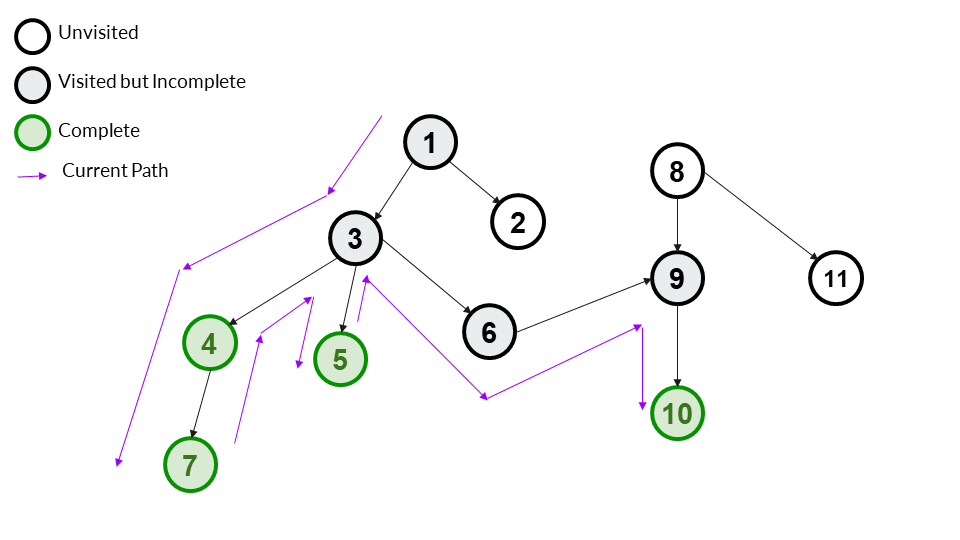
9 has only one child - 10. We go to it and mark it as visited. It was visited in this step so we also add it to answer array. Since 10 has no children, we can mark it as complete.
Answer Array - [1,3,4,7,5,6,9,10]
Step 11
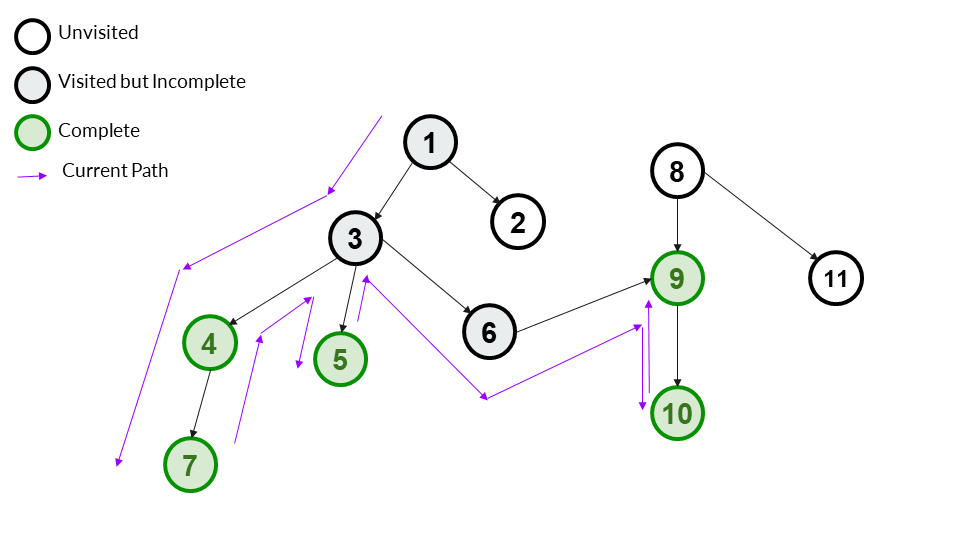
We backtrack to 9. 9 has no more children left, so it is complete. We mark it as complete.
Answer Array - [1,3,4,7,5,6,9,10]
Step 12
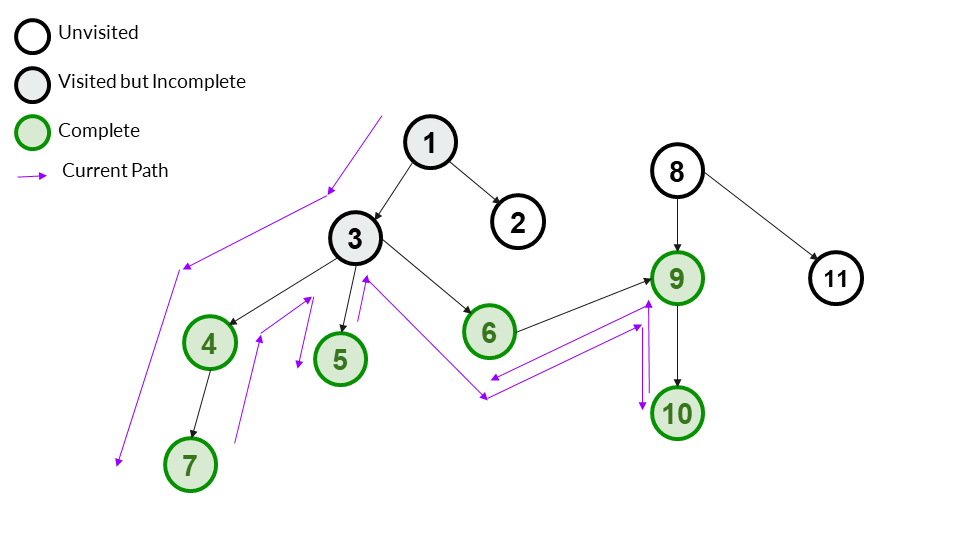
We backtrack to 6. 6 has no more children left, so we can now mark it as complete.
Answer Array - [1,3,4,7,5,6,9,10]
Step 13
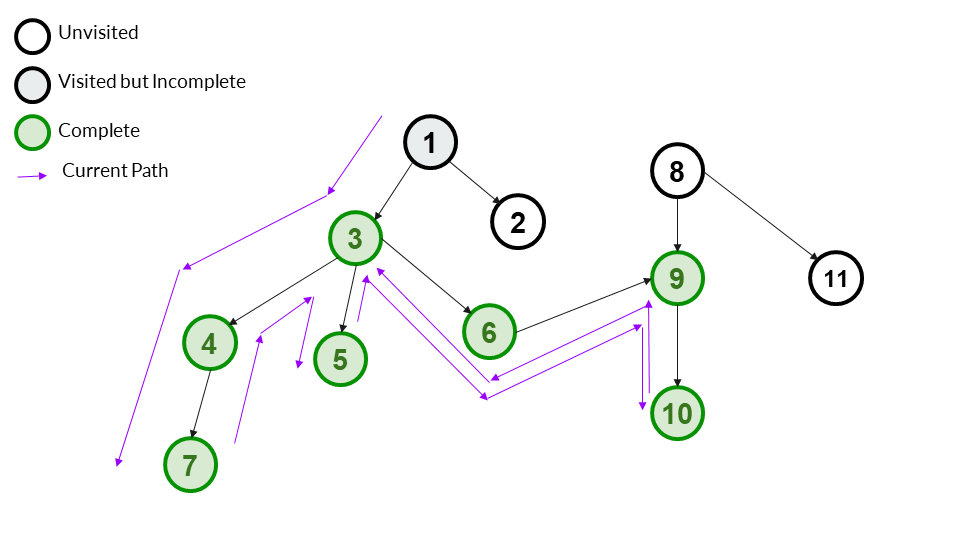
We backtrack to 3. All children of 3 are now complete, so now 3 is also complete. We mark it as complete.
Answer Array - [1,3,4,7,5,6,9,10]
Step 14
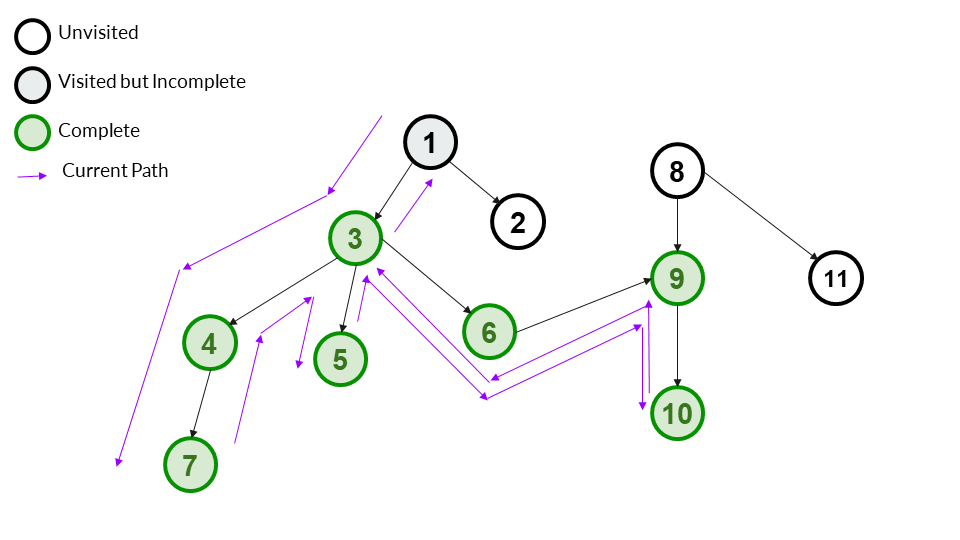
We backtrack to 1 from 3. 1 still has a child left, so we can't mark it as complete.
Step 15
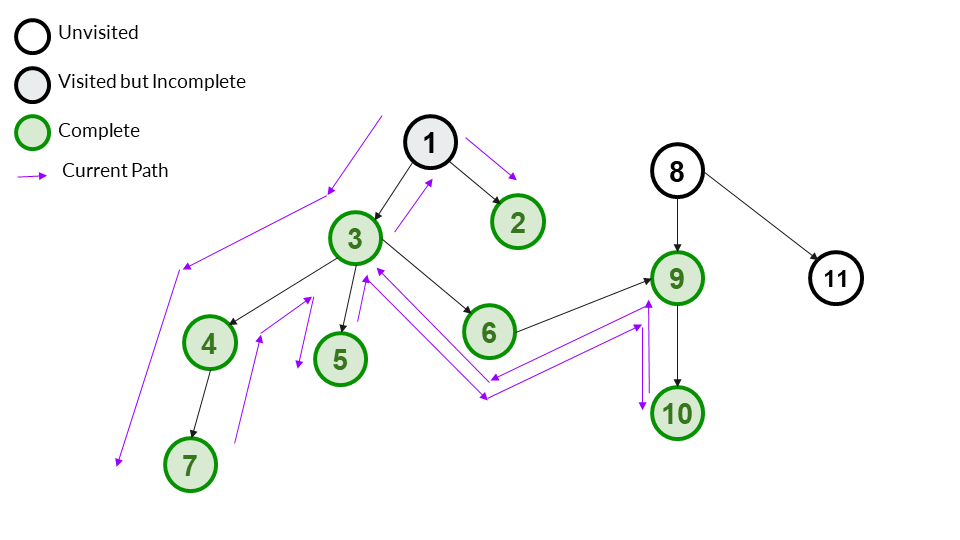
We go to the only remaining child of 1 - 2. We mark it as visited and add it to our answer array. Since 2 has no children, we can also mark it as complete.
Answer Array - [1,3,4,7,5,6,9,10,2]
Step 16
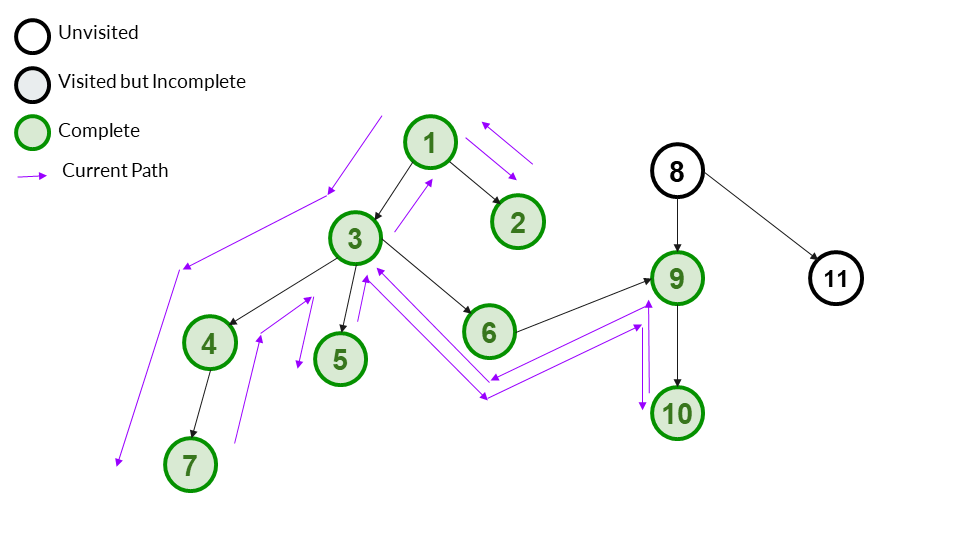
We backtrack to 1. All children of 1 have now been completed. We can mark it as complete.
Answer Array - [1,3,4,7,5,6,9,10,2]
We notice that 8 and 11 are left as unvisited. This is because the graph is disconnected. In such a case, we should do DFS from both 8 and 11. Let us start with 8 first.
Step 17
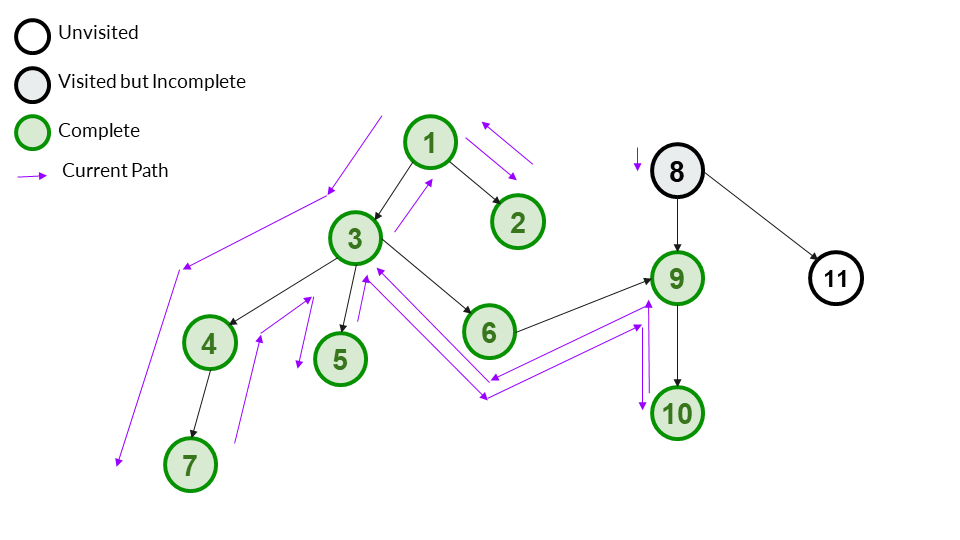
We start a new DFS from 8. We mark it as visited and add it to our answer array.
Answer Array - [1,3,4,7,5,6,9,10,2,8]
Step 18
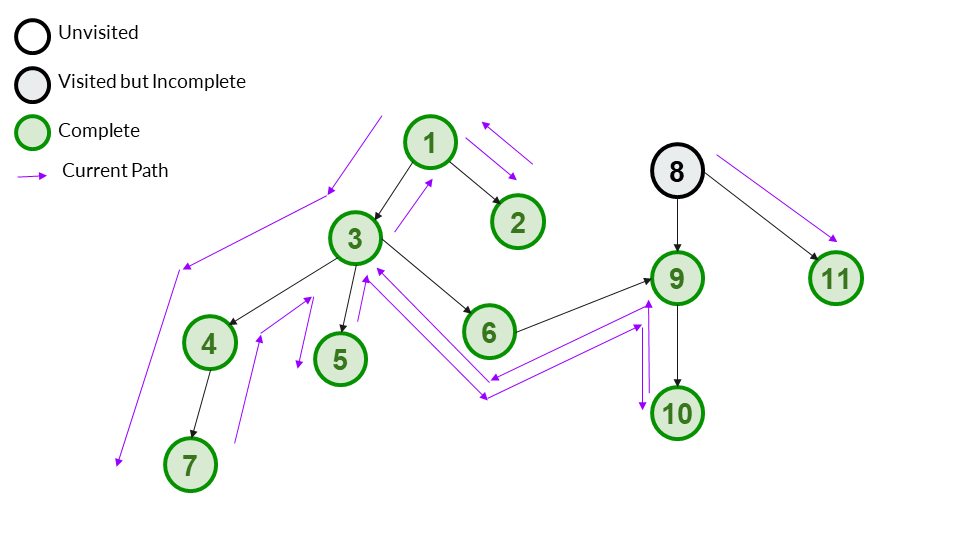
8 has 2 children - 9 and 11. We will not go to 9 as it has been visited before. Only 11 is left. We go to it. We mark it as visited and add it to our answer array. 11 has no children so we can also mark it as complete.
Answer Array - [1,3,4,7,5,6,9,10,2,8,11]
Step 19
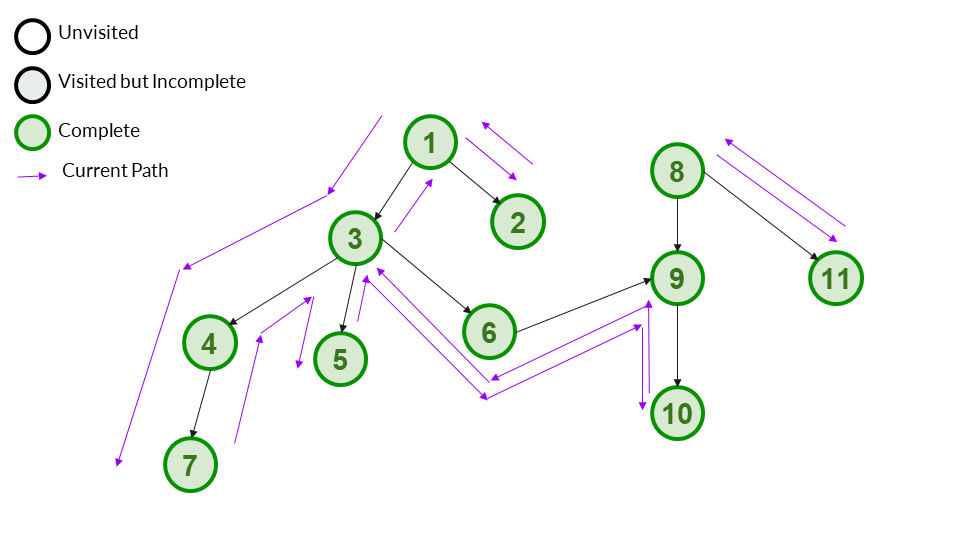
We backtrack to 8. 8 has no incomplete children left, so we can mark it as complete.
Answer Array - [1,3,4,7,5,6,9,10,2,8,11]
Step 20
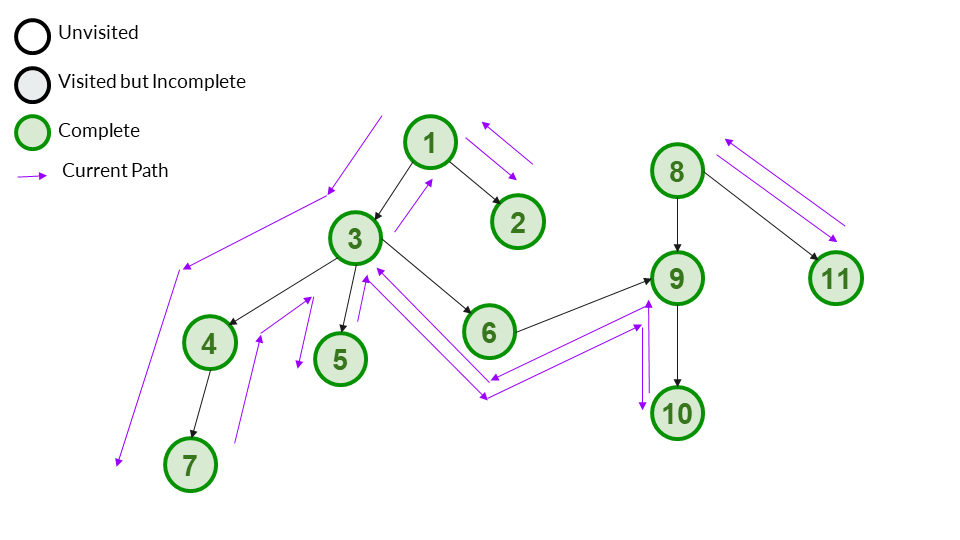
All vertices have now been completed. We don't have to do another DFS from 11 as we earlier thought in Step 16, because 11 has now been visited.
Our DFS is now complete with the final output being [1,3,4,7,5,6,9,10,2,8,11]
Implementation
C++ Code
// C++ code for Depth First Search Traversal
#include <bits/stdc++.h>
using namespace std;
class Graph {
// No. of vertices in the graph
int n;
// A helper function used by DFS.
// This is the main recursive DFS function
void dfsHelper(int v);
// This is the answer array in which the output of the DFS function will be
// stored.
vector<int> dfsAnswer;
public:
// Constructor
Graph(int n) : n(n) {
visited = vector<bool>(n + 1);
for (int i = 1; i <= n; i++)
visited[i] = false;
adj = vector<list<int>>(n + 1);
} // n+1 is used because the vertices are numbered from 1 to n
vector<bool> visited;
vector<list<int>> adj;
// function to add an edge to graph - adds an edge from vertice v to w
void addEdge(int v, int w);
// This is the outer DFS function that makes sure that all the vertices are
// visited This is necessary to handle disconnected graphs.
void dfs();
};
void Graph::addEdge(int v, int w) { adj[v].push_back(w); }
void Graph::dfsHelper(int v) {
// Marking the current node as visited and printing it
visited[v] = true;
dfsAnswer.push_back(v);
// Perform recursion for all the vertices adj to this vertex
for (auto x : adj[v])
if (!visited[x])
dfsHelper(x);
}
// The function to do DFS traversal. It uses the recursive dfsHelper function.
void Graph::dfs() {
for (int i = 1; i <= n; i++)
if (!visited[i])
dfsHelper(i);
for (auto x : dfsAnswer)
cout << x << " ";
}
int main() {
// Creating graph with 11 vertices as in walkthrough example
Graph graph(11);
graph.addEdge(1, 3);
graph.addEdge(1, 2);
graph.addEdge(3, 4);
graph.addEdge(3, 5);
graph.addEdge(3, 6);
graph.addEdge(4, 7);
graph.addEdge(6, 9);
graph.addEdge(9, 10);
graph.addEdge(8, 9);
graph.addEdge(8, 11);
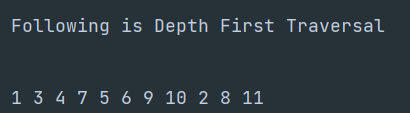
cout << "Following is Depth First Traversal \n";
graph.dfs();
return 0;
}
Output

We can see the output matches our walkthrough result.
Java Code
//Java Code for Depth First Search Traversal
package DemoPackage;
import java.util.ArrayList;
import java.util.LinkedList;
public class Graph {
// No. of vertices in the graph
int n;
// A helper function used by DFS.
// This is the main recursive DFS function
void dfsHelper(int v){
// Marking the current node as visited and printing it
visited[v] = true;
dfsAnswer.add(v);
// Perform recursion for all the vertices adj to this vertex
for (int x : adj[v])
if (!visited[x])
dfsHelper(x);
}
// This is the answer array in which the output of the DFS function will be
// stored.
ArrayList<Integer> dfsAnswer = new ArrayList<>();
// Constructor
Graph(int n) {
this.n = n;
visited = new boolean[n+1];
for (int i = 1; i <= n; i++)
visited[i] = false;
adj = new LinkedList[n+1];
for (int i =0;i<=n;i++){
adj[i] = new LinkedList<>();
}
} // n+1 is used because the vertices are numbered from 1 to n
boolean[] visited;
LinkedList<Integer>[] adj;
// function to add an edge to graph - adds an edge from vertex v to w
void addEdge(int v, int w){
adj[v].add(w);
}
// This is the outer DFS function that makes sure that all the vertices are
// visited This is necessary to handle disconnected graphs.
void dfs(){
for (int i = 1; i <= n; i++)
if (!visited[i])
dfsHelper(i);
for (int x : dfsAnswer)
System.out.print(x+" ");
}
public static void main(String[] args) {
Graph graph= new Graph(11);
graph.addEdge(1, 3);
graph.addEdge(1, 2);
graph.addEdge(3, 4);
graph.addEdge(3, 5);
graph.addEdge(3, 6);
graph.addEdge(4, 7);
graph.addEdge(6, 9);
graph.addEdge(9, 10);
graph.addEdge(8, 9);
graph.addEdge(8, 11);
System.out.println("Following is Depth First Traversal \n");
graph.dfs();
}
}Output
Algorithm Complexity
Let us now see the space and time complexity for Depth First Search.
Time Complexity
O(V + E)
The graph's time complexity is O(V + E), where V represents the number of vertices and E represents the number of edges. We can see this easily in our code - we only visit each vertex once and only visit each edge once.
Space Complexity
O(V)
Because an additional visited array of size V is needed, the space complexity is O(V).


 9+ registered
9+ registered 

