Approach
Here we assume that the front node is the head node, and we add new nodes towards the tail node.
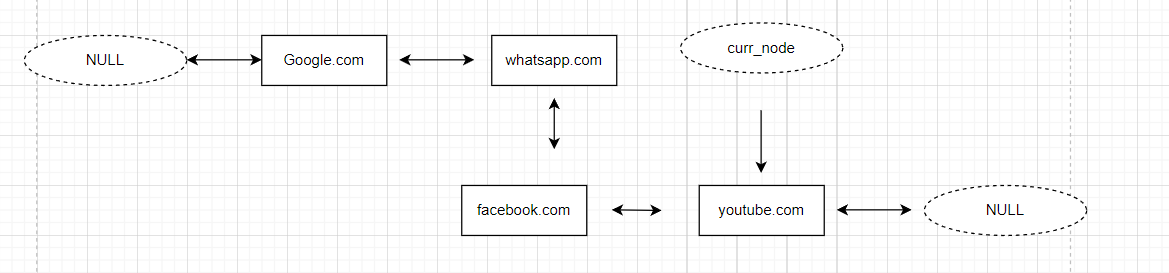
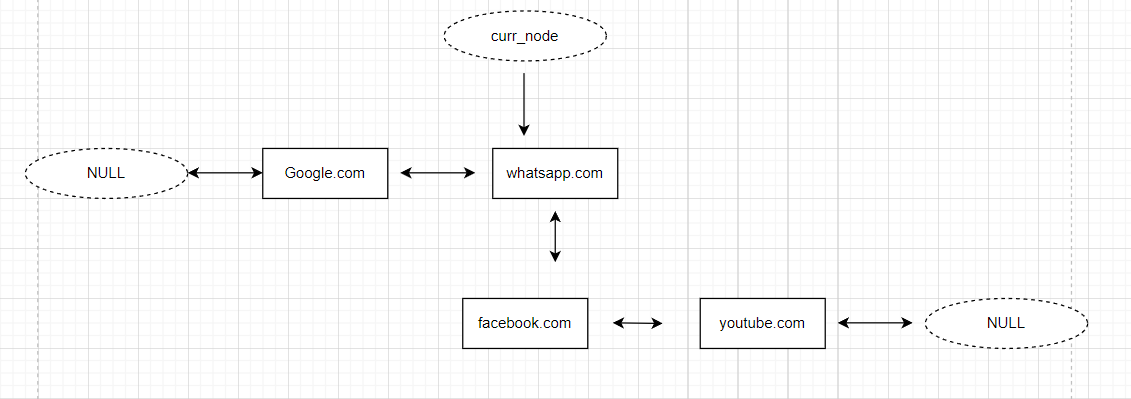
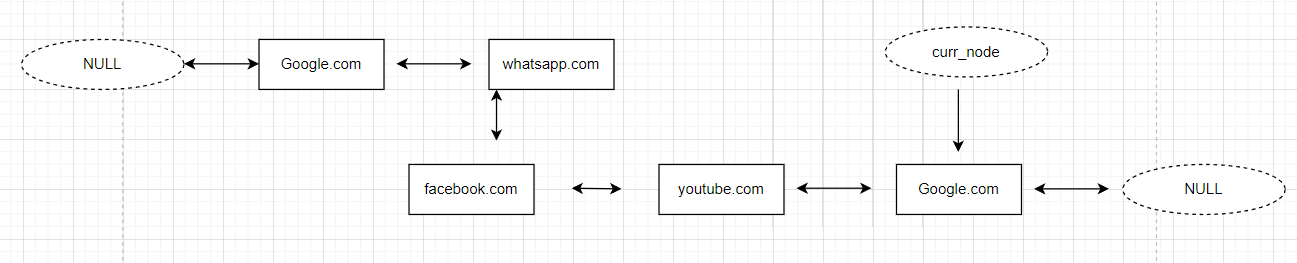
The approach is simple. The current pointer will give us the link to the current URL. When we want to go x nodes back, we will simply go to the previous pointer for x times. While traversing back, if we encounter a head node, we will stop there and return to the current node.
Similarly, when we want to go x steps forward in history, we will simply go forward in the Doubly linked list.
When we visit a new URL, we will simply clear all the forward URLs and add the given URL to the Doubly linked list.
Code in Python
Here is the code for the problem in python3.
class url_node:
def __init__(self, url):
# we are intitializing node with the url given
self.url=url
self.next=self.prev=None
class browser_history:
def __init__(self, curr_page):
# initializing history with the current page
self.curr_url = url_node(curr_page)
def delete_next_url(self,curr_url):
# here the next node is deleted
next_node=curr_url.next
curr_url.next=next_node.next
if curr_url.next:
curr_url.next.prev=curr_url
next_node.next=None
next_node.prev=None
next_node.url=None
def visit(self, url):
while self.curr_url.next:
# while the next node is present we delete the next node
self.delete_next_url(self.curr_url)
# we create a new node with the url given
self.next_page = url_node(url)
# we make the current as the previous of the next node
self.next_page.prev = self.curr_url
# we set the next node of the current node to the new node
self.curr_url.next=self.next_page
self.curr_url=self.next_page
def back(self, steps):
# we go for "steps" step backwards
for i in range(steps):
# if the previous pointer is NULL i.e. it is head node then we break
# because there is no node before head node
if self.curr_url.prev==None:
break
self.curr_url=self.curr_url.prev
# we return the required url
return self.curr_url.url
def forward(self,steps):
# we go for "steps" step forward
for i in range(steps):
# if the next node is NULL i.e. it is tail node then we break
# because there is no node after tail node
if self.curr_url.next==None:
break
self.curr_url=self.curr_url.next
# we return the required url
return self.curr_url.url
obj=browser_history("https://www.google.com/")
function=["visit","visit","visit","back","forward","visit","back","forward","back"]
links=["https://web.whatsapp.com/","https://www.facebook.com/","https://www.youtube.com/",2,3,"https://www.google.com/",1,100,2]
for i,j in zip(function,links):
if i=="visit":
obj.visit(j)
elif i=="back":
url=obj.back(j)
print(url)
else:
url=obj.forward(j)
print(url)

You can also try this code with Online Python Compiler
Output
https://web.whatsapp.com/
https://www.youtube.com/
https://www.youtube.com/
https://www.google.com/
https://www.facebook.com/
Complexities
Time Complexity
Initializing Browser History
The time complexity for initializing Browser History is O(1).
This is because we are making a new node and storing a URL in it.
Visiting a new URL
The time complexity for visiting a new URL is O(size(Doubly linked list)).
We have to clear all of the forward nodes and add the new URL.
The maximum length of the forward nodes can be equal to the size of the Doubly linked list.
If we do not clear the next node, there will be dangling pointers, which may lead to memory leaks.
We can also do this function in O(1) by simply making the next node the new node(URL).
Going back to “steps” in browser history
The time complexity for going back in history is O(steps).
This is because we will have to go back to the whole Doubly LinkedList in the worst case i.e. from the last node to the first node.
However, going back a few steps, we might get the head in some cases.
Then we can’t go back further and thus return the head node.
Going forward “steps” in browser history
The time complexity for going forward in history is O(steps).
In the worst case, we will have to go forward with “steps” steps.
It may happen that going forward a few steps, we get a tail node, and thus we can’t go forward and break and return the current_node.url.
Space Complexity
The space complexity of the program is O(length(Doubly linked list)).
Each node of the Doubly linked list takes constant space or O(1) space as we are storing three things in Node, namely URL, a pointer to next and previous nodes. There are length(Doubly linked list) nodes in the DLL. So the space complexity of the program is O(length(Doubly linked list)) * O(1) = O(length(Doubly linked list))
Frequently Asked Questions
Why did we use a Doubly linked list and not a single-linked list?
Sometimes we have to go forward, and sometimes we have to go backward. In a Doubly LinkedList, we can get the just forward as well as the just backward node in O(1) time. Had we used LinkedList, going backward would have been then O(n) time as we would have to search from the head node again? Thus using Doubly LinkedList makes our code efficient.
Can we make browser history using vector(i.e. array) or stack?
Yes, we can make browser history using vector. When we visit a new URL, we will clear the forward vector and append the new URL in the vector. Using vectors is beneficial because the forward and backward functions take O(1) time complexity. We can directly jump to x step forward or backward in O(1) because the vector has O(1) access. The visit in the vector is also O(1), as we can mark it as the last node. Thus using vectors would be highly efficient.
We can also implement browser history using two stacks. When we add a new URL, we will append it to the first stack. When we go backward, we will pop the current_node from the first stack and append it to the second stack.
The space complexity in all of the above methods will be O(size).
Conclusion
The article helps us understand the implementation of browser history in the Doubly linked list in python3. You can also copy the code and run it on your system on multiple inputs to understand the approach better.
We have used the Doubly LinkedList data structure in our implementation. Also, we have used classes to create as many objects as we need.
You can visit the platform Coding Ninjas Studio to practice more problems, read interview experiences and attempt mock tests.
Recommended Reading:
Do check out The Interview guide for Product Based Companies as well as some of the Popular Interview Problems from Top companies like Amazon, Adobe, Google, Uber, Microsoft, etc. on Coding Ninjas Studio.
Also check out some of the Guided Paths on topics such as Data Structure and Algorithms, Competitive Programming, Operating Systems, Computer Networks, DBMS, System Design, etc. as well as some Contests, Test Series, Interview Bundles, and some Interview Experiences curated by top Industry Experts only on Coding Ninjas Studio.
Happy Learning!!!































 8+ registered
8+ registered 

