Get a skill gap analysis, personalised roadmap, and AI-powered resume optimisation.
Introduction
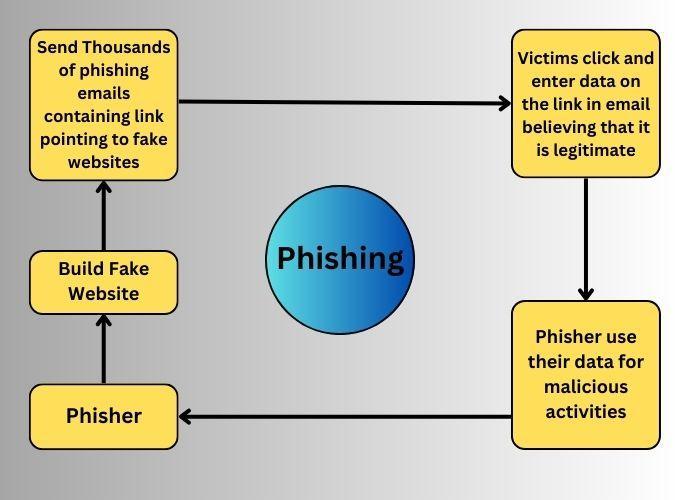
Phishing is a major cyber hazard that occurs when an unauthorized website obtains the victims' credentials. Phishing sites, which expect to steal the victims' confidential data by diverting their attention to a fake website page that looks exactly like the real thing, are another type of criminal that has emerged on the internet, and it is particularly concerned with a variety of areas such as account management and retailing.
In general, phishing is a sort of common fraud that occurs when a malicious website appears as an authentic one. In this article, you will get to know the method of detecting phishing in Data Mining.
What is Phishing?
Phishing is a harmful attempt to gain personal information such as usernames, passwords, and credit card details (and money). It is often done by email spoofing or instant messaging, and it frequently directs people to enter personal information at a nongenuine website with the same look and feel as the authentic site, with the only difference being the URL of the website in question.
Detecting phishing websites frequently includes a search in a directory of harmful websites. Since most phishing websites are temporary, the directory cannot always keep track of everything, including new phishing websites. As a result, several strategies can be used to handle the problem of detecting phishing websites more effectively. A study of multiple strategies shows that the random forest classifier performs better. The only way for an end user to profit from this is for detection to be implemented in a browser plugin. As a result, the user can be cautioned in real-time when browsing a phishing site.
Detection of Phishing
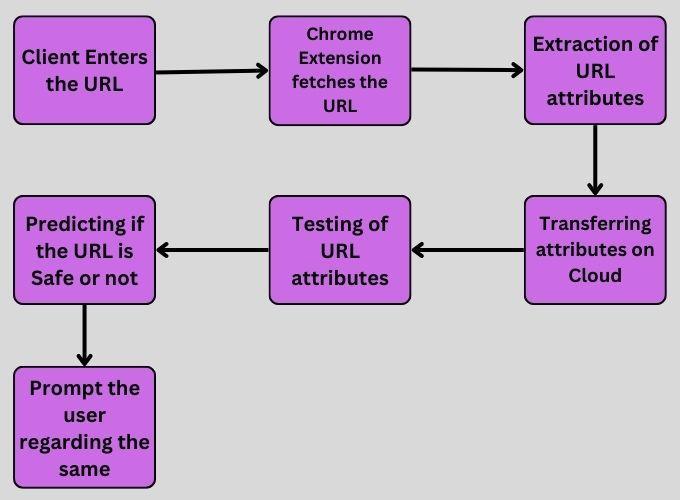
A web host model is employed in the proposed approach to detect phishing websites. The model will be trained using a training dataset and will be based on a classification method. This model will be deployed online and will connect directly with the Chrome extension. The URL and website properties will be used to detect the phishing website. This system will integrate all functions performed on the client and server sides.
On the server, a classifier model will be trained using the random forest technique, while on the client, a Chrome extension will be constructed and added to the Chrome web browser. The Chrome extension may retrieve the URL for any website that the client accesses using the Chrome browser. Various website properties can be derived from the URL and the displayed webpage. These retrieved URL properties will be used as test data for a cloud-based classifier that may be trained on a phishing website dataset.
The classifier will determine whether the URL entered is malicious or safe. If it is a phishing website, the user will be warned that if they continue on this URL, their credentials may be compromised. However, if it is a safe website, the user can carry out further actions on that page.
Chrome Extension
They are little software tools that allow you to personalize your browsing experience. They allow users to customize Chrome functionality and behavior to meet their own needs or tastes. They can range from a small icon, like the Google Mail Checker extension seen on the right, to completely overtaking a page.
Pre-Processing
The dataset is obtained from the UCI repository and placed in a NumPy array. The dataset has 30 features that must be reduced so that they can be extracted on the browser. Each feature is tested on the browser to ensure that it may be extracted without the use of an external online service or a third party.
Based on the experiments, 17 features were picked out of 30 with little loss in test data accuracy. The amount of features increases accuracy while decreasing the ability to detect quickly due to feature extraction time. The dataset is then divided into training and testing sets, with 30% set aside for testing. Training and testing data are both saved to disk.
Training Data
The proposed model will be trained using a publicly available dataset from the UCI repository. It has 11055 records, 4,898 of which are phishing websites and 6,157 of which are authentic websites. After preprocessing, 70% of the data is used for training with a random forest classifier.
Exporting Module
During the training phase, every machine learning algorithm learns the values of its parameters. Each decision tree in Random Forest is an autonomous learner, and each decision tree learns node threshold values as the leaf nodes learn class probabilities. As a result, a format for representing the Random Forest in JSON must be developed.
Algorithm
For training data, we will primarily employ the random forest classifier in the proposed system.
Random Forest Algorithm
The random forest algorithm is a supervised classification and regression algorithm. This algorithm, as the name implies, generates a forest with various trees at random. In general, the more trees there are in a forest, the more sturdy it appears. Similarly, with the random forest classifier, the more the number of trees in the forest, the higher the accuracy of the outputs.
Begin by randomly selecting samples from a given dataset
This method will then build a decision tree for each sample. The forecast result from each decision tree will then be obtained
Every expected result will be voted on in this phase
Finally, choose the most voted forecast result as the final prediction result
Why Random Forest Algorithm
Random forests perform better than single decision trees for a wide range of data items
The variance of a random forest is lower than that of a single decision tree
Random forests are extremely adaptable and accurate
Even when a major amount of the data is missing, the Random Forest method maintains good accuracy
Frequently Asked Questions
What is data mining?
Data mining refers to a technology that involves the mining or extraction of knowledge from extensive amounts of data. Data Mining is the computational procedure of locating patterns in massive data sets involving artificial intelligence, machine learning, statistics, and database systems.
How can I identify a Phishing scam?
Any email that requests personal or sensitive information should be thoroughly scrutinized and not trusted. Even if the email contains genuine logos, text, or links to trustworthy websites, it could be false. Never reveal any of your personal information.
What is a Firewall, and why is it used?
A firewall is a network security device that monitors and regulates network traffic at the system/network's perimeter. Firewalls are primarily used to defend the system/network from viruses, worms, malware, and other malicious software. Firewalls can also be used to prevent unauthorized remote access and content filtering.
What is Penetration Testing?
The process of discovering vulnerabilities in the target is known as penetration testing. In this situation, the business would have implemented all possible security measures and would want to see whether there is any other way that their system/network could be hacked.
Conclusion
The goal of the proposed system is to detect phishing in data mining. When the visitor views the website, the features will be extracted using the URL. To train the proposed model, the Random Forest Algorithm might be employed. The primary function of this system is to detect phishing websites and inform users in advance so that their credentials are not exploited. This article efficiently describes the method of detecting phishing in data mining.






























 9+ registered
9+ registered 

