Do you think IIT Guwahati certified course can help you in your career?
Introduction
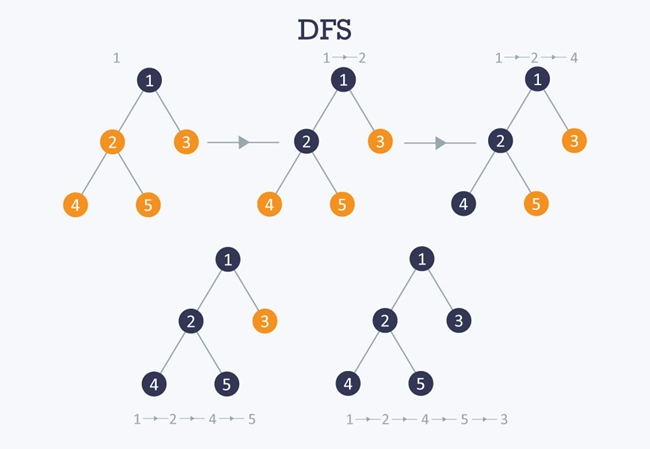
Depth-first search (DFS) is an algorithm for traversing or searching tree or graph data structures. The DFS Algorithm starts at the root node (selecting some arbitrary node as the root node in the case of a graph) and explores as far as possible along each branch before backtracking.
A version of the depth-first search was investigated in the 19th century by French mathematician Charles Pierre Tremaux as a strategy for solving mazes.
Example:
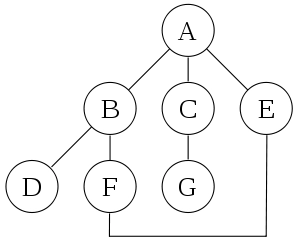
A depth-first search starting at A, assuming that the left edges in the shown graph are chosen before right edges, and assuming the search remembers previously visited nodes and will not repeat them (since this is a small graph), will visit the nodes in the following order: A, B, D, F, E, C, G.
The edges traversed in this search form a Trémaux tree, a structure with important applications in graph theory. Performing the same search without remembering previously visited nodes results in visiting nodes in the order A, B, D, F, E, A, B, D, F, E, etc. forever, caught in the A, B, D, F, E cycle and never reaching C or G. Iterative deepening is one technique to avoid this infinite loop and would reach all nodes.
Output of a Depth-First Search: A convenient description of a depth-first search of a graph is in terms of a spanning tree of the vertices reached during the search. Based on this spanning tree, the edges of the original graph can be divided into three classes: forward edges, which point from a node of the tree to one of its descendants, back edges, which point from a node to one of its ancestors, and cross edges, which do neither. Sometimes tree edges, edges which belong to the spanning tree itself, are classified separately from forwarding edges. If the original graph is undirected then all of its edges are tree edges or back edges.
DFS Algorithm
A standard DFS implementation puts each vertex of the graph into one of two categories:
Visited
Not Visited
The purpose of the algorithm is to mark each vertex as visited while avoiding cycles.
The DFS algorithm works as follows:
Start by putting any one of the graph’s vertices on top of a stack.
Take the top item of the stack and add it to the visited list.
Create a list of that vertex’s adjacent nodes. Add the ones which aren’t in the visited list to the top of the stack.
Keep repeating steps 2 and 3 until the stack is empty.
Pseudocode
DFS-iterative (G, s): //Where G is graph and s is source vertex
let S be stack
S.push( s ) //Inserting s in stack
mark s as visited.
while ( S is not empty):
//Pop a vertex from stack to visit next
v = S.top( )
S.pop( )
//Push all the neighbours of v in stack that are not visited
for all neighbours w of v in Graph G:
if w is not visited :
S.push( w )
mark w as visited
DFS-recursive(G, s):
mark s as visited
for all neighbours w of s in Graph G:
if w is not visited:
DFS-recursive(G, w)
DFS implementation with Adjacency Matrix
Adjacency Matrix:- An adjacency matrix is a square matrix used to represent a finite graph. The elements of the matrix indicate whether pairs of vertices are adjacent or not in the graph.
Representation
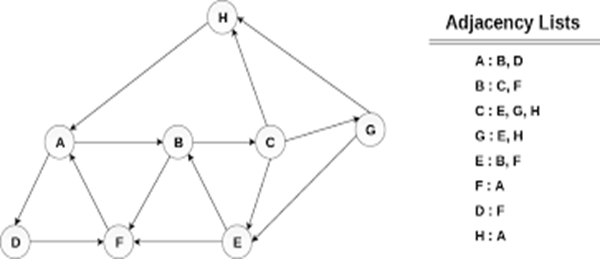
A common issue is a topic of how to represent a graph’s edges in memory. There are two standard methods for this task. An adjacency matrix uses an arbitrary ordering of the vertices from 1 to |V |. The matrix consists of an n × n binary matrix such that the (i, j) th element is 1 if (i, j) is an edge in the graph, 0 otherwise.
An adjacency list consists of an array A of |V | lists, such that A[u] contains a linked list of vertices v such that (u, v) ∈ E (the neighbors of u). In the case of a directed graph, it’s also helpful to distinguish between outgoing and ingoing edges by storing two different lists at A[u]: a list of v such that (u, v) ∈ E (the out-neighbors of u) as well as a list of v such that (v, u) ∈ E (the in-neighbors of u).
What are the tradeoffs between these two methods? To help our analysis, let deg(v) denote the degree of v, or the number of vertices connected to v. In a directed graph, we can distinguish between out-degree and in-degree, which respectively count the number of outgoing and incoming edges.
The adjacency matrix can check if (i, j) is an edge in G in constant time, whereas the adjacency list representation must iterate through up to deg(i) list entries.
The adjacency matrix takes Θ(n 2 ) space, whereas the adjacency list takes Θ(m + n) space.
The adjacency matrix takes Θ(n) operations to enumerate the neighbours of a vertex v since it must iterate across an entire row of the matrix. The adjacency list takes deg(v) time.
What’s a good rule of thumb for picking the implementation? One useful property is the sparsity of the graph’s edges. If the graph is sparse, and the number of edges is considerably less than the max (m << n 2 ), then the adjacency list is a good idea. If the graph is dense and the number of edges is nearly n 2 , then the matrix representation makes sense because it speeds up look-ups without too much space overhead. Of course, some applications will have lots of space to spare, making the matrix feasible no matter the structure of the graphs. Other applications may prefer adjacency lists even for dense graphs. Choosing the appropriate structure is a balancing act of requirements and priorities.
CODE
// IN C++
#include<bits/stdc++.h>
using namespace std;
void DFS(int v, int ** edges, int sv, int * visited) {
cout << sv << endl;
visited[sv] == 1;
cout << “ ** ” << visited[sv] << ”sv is” << sv << endl;
for (int i = 0; i > v >> e;
//Dynamic 2-D array
int ** edges = new int * [v];
for (int i = 0; i > f >> s; edges[f][s] = 1; edges[s][f] = 1;
}
int * visited = new int[v];
for (int i = 0; i < v; i++) {
visited[i] = 0;
}
/*Adjacency Matrix Code, if you want to print it as well remove comments
for(int i=0;i<v;i++)
{
cout << endl;
for(int j=0;j<v;j++)
{
cout << edges[i][j] << ” “;
}
}
*/
//here 0 is starting vertex.
DFS(v, edges, 0, visited);
}
You can also try this code with Online C++ Compiler
Algorithms that use depth-first search as a building block include:
Finding connected components.
Topological sorting.
Finding 2-(edge or vertex)-connected components.
Finding 3-(edge or vertex)-connected components.
Finding the bridges of a graph.
Generating words in order to plot the limit set of a group.
Finding strongly connected components.
Planarity testing.
Solving puzzles with only one solution, such as mazes. (DFS can be adapted to find all solutions to a maze by only including nodes on the current path in the visited set.)
Maze generation may use a randomised depth-first search.
Finding connectivity in graphs.
DFS Pseudocode (Recursive Implementation)
The pseudocode for DFS is shown below. In the init() function, notice that we run the DFS function on every node. This is because the graph might have two different disconnected parts so to make sure that we cover every vertex, we can also run the DFS algorithm on every node.
DFS(G, u)
u.visited = true
for each v∈ G.Adj[u]
if v.visited == false
DFS(G, v)
init() {
For each u∈ G
u.visited = false
For each u∈ G
DFS(G, u)
}
You can also try this code with Online C++ Compiler
Space Complexity: The space complexity for BFS is O(w) where w is the maximum width of the tree. For DFS, which goes along a single ‘branch’ all the way down and uses a stack implementation, the height of the tree matters. The space complexity for DFS is O(h) where h is the maximum height of the tree.
The stack data structure is used for DFS. When a search runs into a dead end during any iteration, the Depth First Search (DFS) algorithm employs a stack to keep track of where to go next to continue the search.
What do you mean by BFS?
Finding the shortest path in a graph or tree is done using the vertex-based method of BFS or breadth-first search. Before moving on to nodes at the following depth level, it starts at the root node of the tree or graph and explores every node at the current depth level.
Is DFS faster than BFS?
We can say that DFS is faster than BFS, but it depends on the distance between the target node and the root node. BFS is better when the target( goal node) is close to the source(root node). DFS is better when the target is far from the source(root node).
Conclusion
We discussed how to implement DFS using Adjacency Matrix. We implemented the DFS algorithm to mark each vertex as visited while avoiding cycles. Hope you enjoyed the article.






























 9+ registered
9+ registered 

