


























Introduction
While training the neural network, everyone might encounter the two terms backpropagation and stochastic gradient descent. You might get confused about what these two terms do. Training a neural network means adjusting the weights of the model in such a way that the loss of the overall dataset is minimized.
Forward propagation in training neural networks is just to calculate the loss of the model. While propagating backward, weights are updated to minimize the total loss. The forward and backward propagation is done until the loss is minimum. In this way, a neural network is trained. So, where do we need backpropagation and stochastic gradient descent?
In this article, we will see the use of backpropagation and stochastic gradient descent. Furthermore, we will discuss how backpropagation is different from stochastic gradient descent.
Backpropagation
To understand backpropagation, let us first see what gradient is. The gradient of the function gives an idea about the function, whether it is increasing or decreasing in a particular direction.
During the training of neural networks, the main goal is to minimize the cost function. We need to propagate backward and update the weights in order to minimize the cost. As the neural network may have many hidden layers and weights of every ith layer depends on the i+1th layer. Suppose the neural network has n layers. The weights of the n-1th layer depend on the output layer, and the output is directly proportional to the cost function. Now, we will find the cost function derivative with respect to every weight and bias in the n-1th layer. Using the chain rule, we can find the gradient of weight in any layer, i.e., dL/dwi. We will obtain gradients for every weight; this result is used to update the weights by subtracting the result from the original weights. Hence the subtraction of the result from the weight(wi - (lerning_rate)*dL/dw) may cause greater change. Therefore we use the learning rate to take baby steps to reach the minima of the cost function as shown below.
wi = wi - (lerning_rate)*dL/dw.
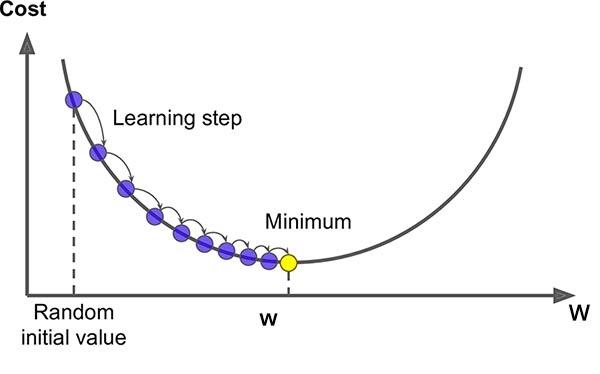
We will perform the above operation for every weight in every layer, so the overall value of the cost function is minimized.
In simple words, backpropagation is an algorithm where the information of cost function is passed on through the neural network in the backward direction.
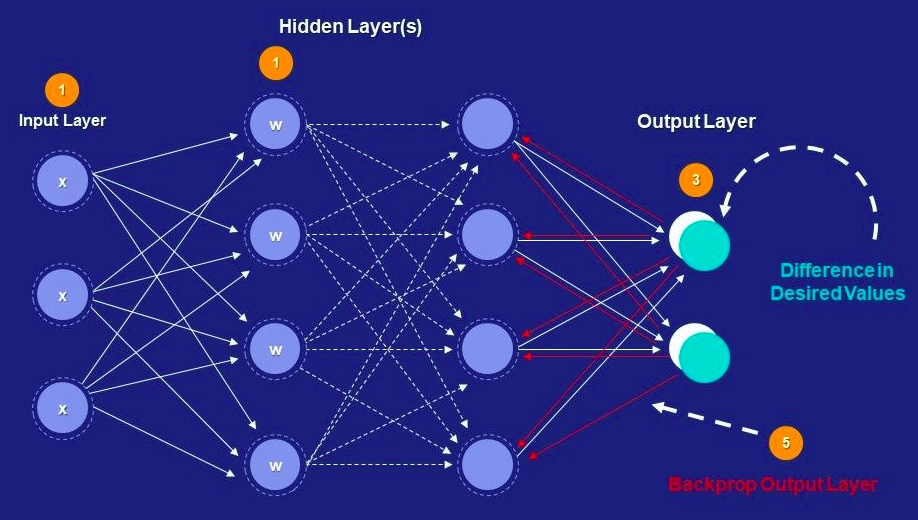
Below is the image of backpropagation.


 8+ registered
8+ registered 

