Do you think IIT Guwahati certified course can help you in your career?
Introduction
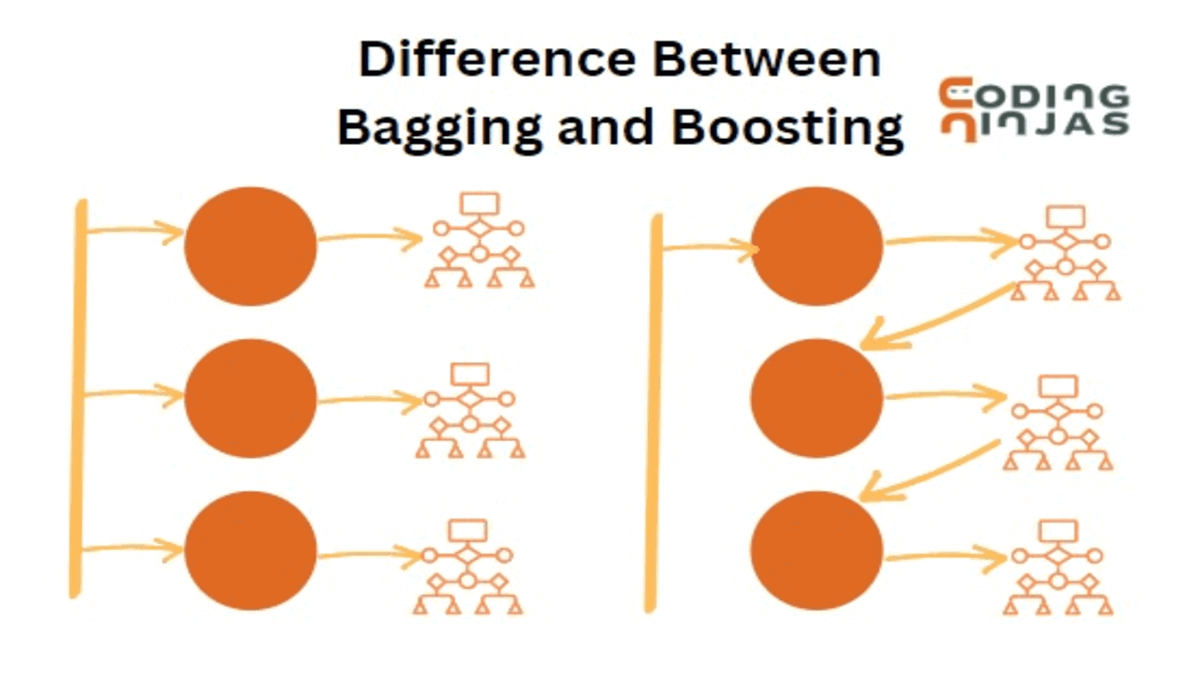
Bagging and Boosting are two powerful ensemble techniques widely used in machine learning to improve model accuracy and reduce errors. Both methods combine multiple models to make predictions, but they do so in fundamentally different ways. Bagging, or Bootstrap Aggregating, aims to reduce variance by building multiple independent models in parallel while Boosting focuses on reducing bias by creating models sequentially, each correcting the errors of its predecessor.
The two types of Ensemble Learning are- Bagging and Boosting.
Let us look at both of them in detail and then move on to describe the difference between Bagging and Boosting.
Bagging
Bagging, short for bootstrap aggregating, is a technique that involves training multiple models using different samples of the dataset. These models are then combined to produce an aggregate prediction.
In bagging, we train each model on a randomly selected subset of the data with replacement, which means some data points may be used multiple times in the training process while others may not.
By using multiple models trained on different subsets of the data, bagging helps reduce the model's variance and improve its accuracy.
Steps involved in Bagging
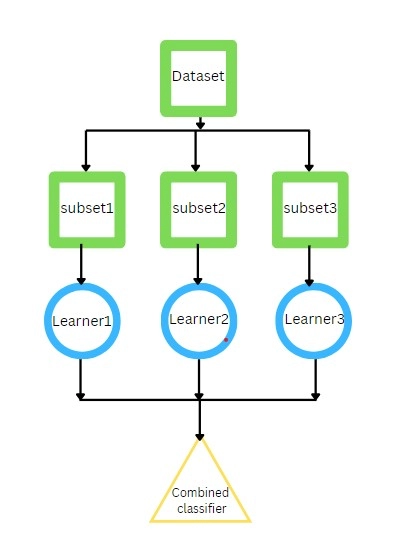
Divide the entire dataset into smaller subsets using random sampling with replacements.
Create a model and train each learner classifier on a separate dataset subset.
Since the subsets are entirely independent of each other, we can train all of the classifiers on their respective subset simultaneously.
Then, combine the results of each individual learner to give the final prediction.
Boosting
Boosting, on the other hand, is a technique that involves training multiple models sequentially; unlike bagging, boosting focuses on improving the model's accuracy by adjusting the weights of the training data.
In boosting, we train each model on the entire dataset, but the weight of each data point is adjusted based on how well the previous model performed on that data point.
We give a higher weight to the data points the previous model misclassified while a lower weight to data points that are correctly classified. By providing more attention to the problematic data points, boosting helps improve the model's overall accuracy.
Steps involved in Boosting
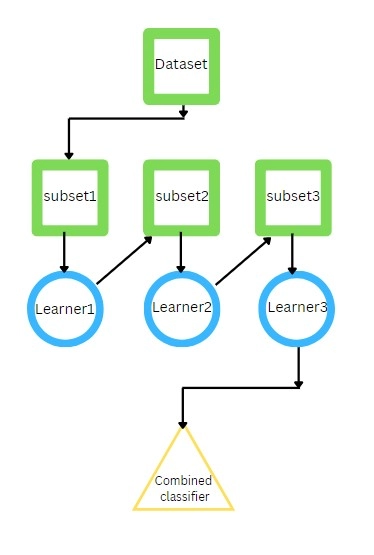
Train the base model on the data to evaluate its performance. It gives some correct classifications and some misclassifications.
Train the next learner on the dataset, keeping the previous learner's misclassification in mind, and try to correct the errors of the previous model.
Repeat this step to train all the learners till you can correctly classify the output.
Test the entire model on a testing dataset to evaluate the performance.
Now that we have looked into the basic outline of bagging and boosting, we will look at the difference between bagging and boosting.
Difference between Bagging and Boosting
In this section, we will see the difference between bagging and boosting. .
Bagging
Boosting
The classifiers are trained parallelly.
The classifiers are trained sequentially.
Each model is built independently.
Each model is built upon the previous model and is affected by the previous model’s performance.
The original dataset is divided into data subsets.
The subset of the current learner contains the elements misclassified by the previous dataset.
Each model has an equal weight on the final prediction.
Each learner’s weight on the final prediction depends on their individual performance.
The aim is to reduce the variance.
The aim is to reduce the bias.
Predictions of the same type are combined.
Predictions of different types are combined.
Used when the classifiers are unstable.
Used when the classifiers are stable.
Some types are Random Forest, Bagging meta-estimator, BORE, etc.
Some types are Adaboost, Gradient Boosting, XGBoost, etc.
Reduces Overfitting: Bagging helps reduce overfitting by averaging out predictions from multiple models. This is especially useful with high-variance models like decision trees.
Improves Stability: By creating multiple subsets of data and training independent models, bagging reduces the model's sensitivity to small changes in the training set, enhancing its stability.
Parallel Processing: Since models are trained independently, bagging can be parallelized, making it computationally efficient and scalable.
Handles High Variance Well: Bagging works effectively with algorithms that tend to overfit by decreasing variance, resulting in more generalized models.
Advantages of Boosting
Reduces Bias: Boosting sequentially corrects errors from previous models, which helps to reduce bias, making it suitable for complex data with high bias.
Increases Accuracy: Each model focuses on the mistakes of the previous one, producing a strong overall model with improved accuracy on challenging datasets.
Adaptability: Boosting can adapt to different kinds of data by focusing more on misclassified points, making it effective for imbalanced datasets.
Good for Weak Models: Boosting is well-suited for combining weak learners, like shallow trees, into a powerful predictive model by carefully adjusting weights based on errors.
Above, we looked at the difference between bagging and boosting. Let us look at some of the questions commonly asked about this.
Frequently Asked Questions
Which technique is better, bagging or boosting?
The choice of technique depends on the specific problem and the nature of the data. Bagging can be more effective in reducing overfitting while boosting can be more effective in improving accuracy. The fact that boosting does not prevent overfitting data while bagging affects this decision.
Can bagging and boosting be used together?
Yes, bagging and boosting can be used together in a technique called Bagging AND Boosting. This technique involves bagging to create multiple subsets of the training data and then boosting to train models on each subset.
Which algorithms are commonly used with bagging and boosting?
Bagging is commonly used with decision trees, and the resulting ensemble is known as a random forest. Boosting can be used with various base learners, including decision trees, logistic regression models, and neural networks.
How do bagging and boosting differ in terms of computational complexity?
Bagging can be faster than boosting because the models can be trained independently. Boosting, on the other hand, requires sequential training of the models, which can be computationally expensive. However, optimized boosting versions, such as XGBoost and LightGBM, are designed to be faster and more memory-efficient.
Is decision tree bagging or boosting?
A decision tree itself is neither bagging nor boosting. However, techniques like Bagging (e.g., Random Forest) and Boosting (e.g., AdaBoost) use decision trees.
Conclusion
We hope this article was insightful and you learned something new. In this blog, we learned about Bagging and its implementation. We also learned about Boosting and its implementation. In the end, we saw the difference between bagging and boosting.






























 9+ registered
9+ registered 

