Do you think IIT Guwahati certified course can help you in your career?
Introduction
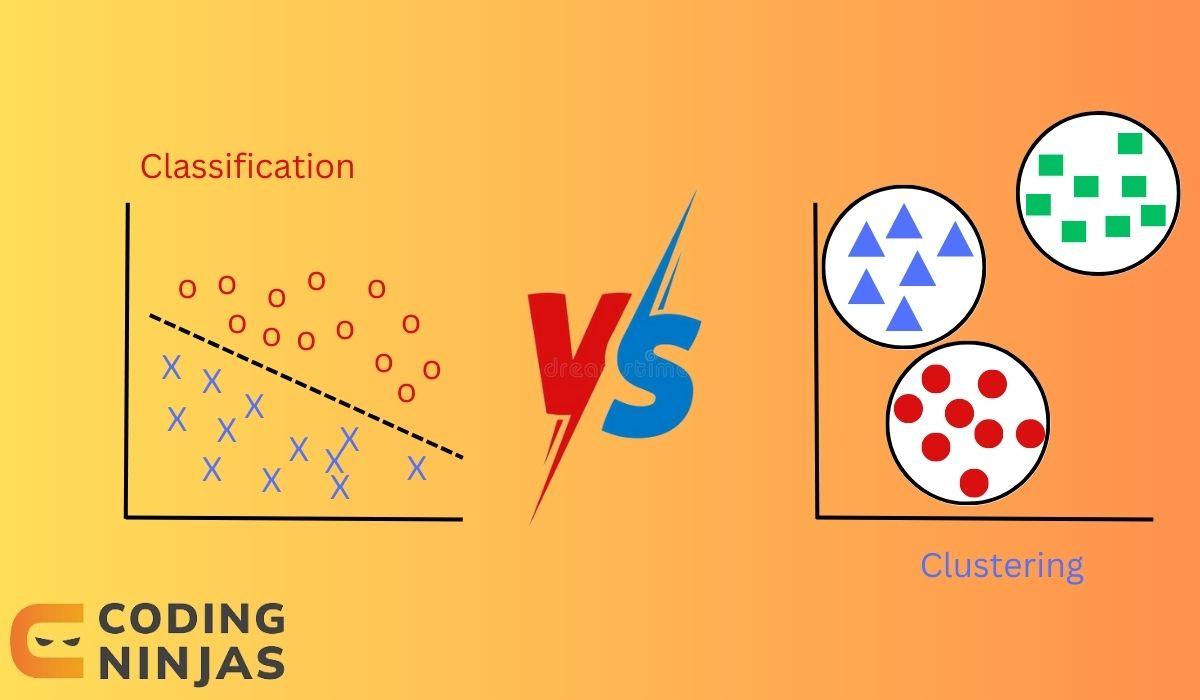
Hello Ninjas! In this article, we will discuss the difference between classification and clustering. Four machine learning techniques exist supervised, unsupervised, semi-supervised and reinforcement learning. Classification is a supervised learning technique, whereas clustering is an unsupervised learning technique.
Let’s begin by first learning what classification is.
Classification
It is one of the most popular machine-learning techniques. It classifies input data into a class, labels, or categories. It is employed in various applications such as facial recognition, image classification, spam filtering, fraud detection, voice recognition, etc. It is a supervised learning method in which the model uses a labelled dataset to train their weights to predict the category or class of unseen data points. For further information on classification, check out this article.
Types of Classification Techniques
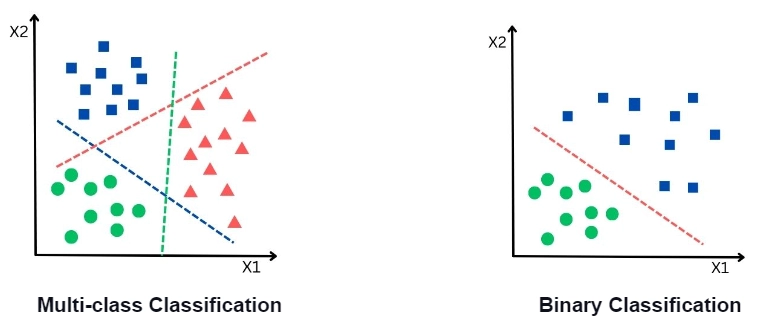
Based on the number of classes or categories to classify, there are two types of classification techniques:
Binary Classification:When the data is classified into only two categories, the problem comes under binary classification—for example, breast cancer classification, spam email filtering, fake news detection, etc.
Multi-Class Classification:When the data is classified into more than two categories, the problem comes under multi-class classification—for example, image classification, voice recognition, face recognition, etc.
Some basic classification algorithms include Logistic Regression, Decision Trees, Naive Bayes, Random Forest, Support Vector Machine (SVM), etc.
The above algorithms can be further classified into linear and non-linear classifications based on whether the data points are linearly separable. For further information, visit this blog.
Clustering
It is used to group or divide a dataset into multiple groups or clusters of similar data points. This division is based on data characteristics or features. As it is an unsupervised learning technique, it does not require a labelled dataset for clustering the data points. It involves analysing or identifying patterns or similarities between the data points, and similar data are grouped. The similarities are based on various features of the data. For example, One can use the number of wheels of a vehicle to identify whether a vehicle is a car or a bike. So, the number of wheels is a feature that can be used for clustering cars and bikes.
Types of Clustering Techniques
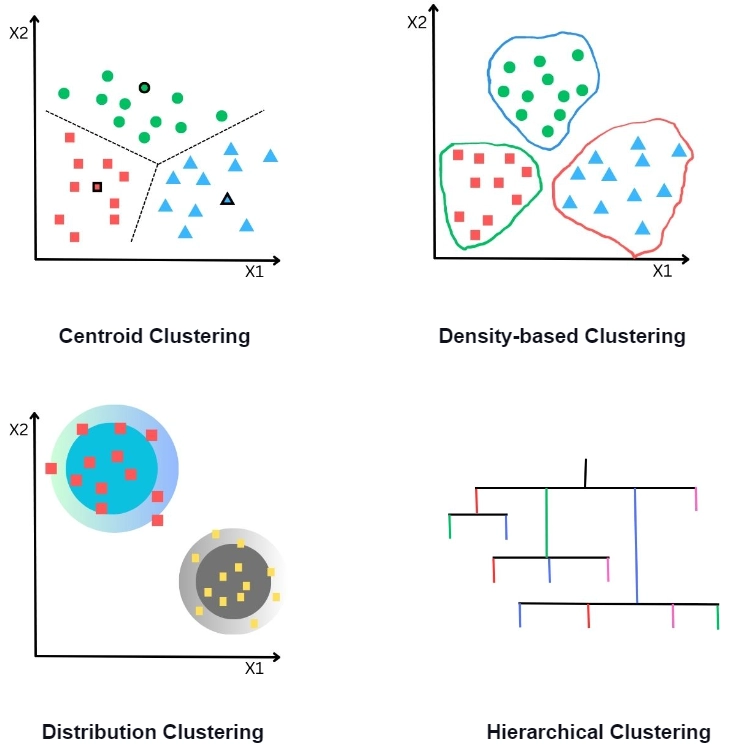
There are four types of clustering techniques:
Hierarchical Clustering:This technique creates a hierarchy of clusters by merging either smaller groups into larger ones or dividing larger groups into smaller ones. For example, files and folders are clustered on hard disks, etc.
Density-based Clustering: This technique identifies higher data point densities and considers their clusters. Points in lower density are considered to be noise or outliers.
Centroid-based Clustering: This technique divides the dataset into clusters based on the number of centroids. Each data point lies in one of the centroid’s regions.
Distribution-based Clustering: If the data points follow a specific distribution like the Gaussian distribution, then this method divides the data into different clusters based on the probability of the data belonging to the group.
Some basic clustering algorithms include K-means, DBSCAN, Spectral Clustering, etc.
Difference Between Classification and Clustering
Here are some critical differences between classification and clustering:
Parameter
Classification
Clustering
Type
Supervised Learning
Unsupervised Learning
Goal
Classification predicts the output label or class of any input data.
Clustering groups similar data or instances without knowledge of their categories.
Evaluation
Classification algorithms are evaluated using accuracy, precision, recall, and F1-score metrics, which measure how well the algorithm predicts the correct class labels.
Clustering algorithms are evaluated based on how well they group instances based on similarity by using metrics such as silhouette score, purity, and completeness.
Algorithms
Logistic regression, SVM, Naive Bayes, etc.
K-means, DBSCAN, C-means clustering, etc.
Domain
Classification is used in tasks such as image classification, sentiment analysis, spam filtering, etc.
Clustering is used in customer segmentation, anomaly detection, document grouping, etc.
Frequently Asked Questions
Q1. What is the difference between classification and clustering?
Classification consists of assigning labels to predefined categories; whereas clustering combines similar data points without predefined labels.
Q2. What is the difference between clustering and grouping?
Clustering is a form of grouping based on statistical distribution and similarity, often used in unsupervised machine learning for data analysis.
Q3. What is the main difference between classification, regression, and clustering techniques Class 9?
Classification predicts discrete labels, regression predicts continuous values, and clustering organizes data into groups without prior labels.
Conclusion
In this article, we have learned the basics of classification and clustering and the difference between classification and clustering. We also saw different algorithms for each kind and their use cases. To learn more about these techniques, you can check out our other blogs:





























 6+ registered
6+ registered 

