Do you think IIT Guwahati certified course can help you in your career?
Introduction
Do you know how data are fetched from clusters? How are these operations faster? How does a distributed cluster aggregate to give combined information? As you might hear, the word Clustered and Non-Clustered Index. Let's explore together the difference between Clustered and Non-Clustered indexes. These two terms are data structures used in Database Management Systems to boost data retrieval from tables which are present on clusters. The indexing concept creates a logical or physical representation of data. We can perform queries using these indexes.
This article will discuss the difference between Clustered and Non Clustered indexes. We will also review their related concepts like their features, advantages, disadvantages, etc.
Definition of Indexes
Indexes is one of the important terminology used in SQL. Indexes are used to retrieve the data from the database. It helps uniquely identify the tuple if the taken index is a primary or set of keys. There are many types of Indexes, such are:
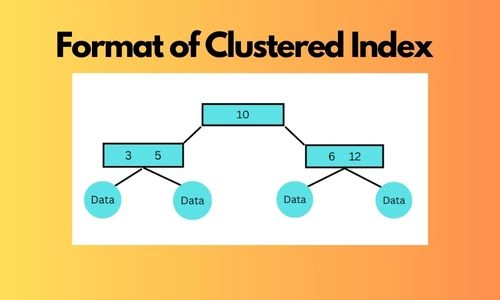
Clustered Indexing is used in the relational database to define the physical way of storing data in a table. The data in the tables are organised following the key values of the Index. We can retrieve information faster using the index key in the query. In Clustered Index, records are present in sorted order in a database table. There is one Clustered Index for each table. Clustered Index are made on columns or sets of columns that identify tuples uniquely. Because of its ordered arrangement, the SQL server can perform quick and efficient access over the range of values. It is recommended to use it for large tables.
Syntax
Step 1 : First, we need to create a table in the Database
CREATE TABLE NinjaTable (
Id INT IDENTITY(1,1) PRIMARY KEY,
FirstName VARCHAR(80),
LastName VARCHAR(80),
Age INT,
);
You can also try this code with Online Javascript Compiler
First, we created a Database and inserted some data. The table has four columns: Id of type Integer, FirstName of type String, LastName of type String and Age of type Integer. Lastly, we define our Clustered Index in the “Age” column. The rows in “Age” will be sorted according to the values in its column.
Features of Clustered Index
Some of the characteristics of a Clustered index are as follows -
Physical Ordering of the Data
The data in a Clustered index is physically stored on a disk corresponding to its ordered Index. It means the data is sorted based on the values in the indexed columns. It results in faster query performance for data access.
Unique
Clustered Index is unique. It means that each value in the indexed columns can only be once in the Index. As Index locate specific rows in the table, duplicate values will cause ambiguity.
Primary Key
Most of the time, Clustered Index is made on the table's primary key. The primary key is unique and identifies each row in the table. Creating a Clustered index on the primary key makes the primary key physically order the data.
One Per Table
A table has only one Clustered Index, as data in the tables are physically sorted in one way. However, a table can have multiple Non-Clustered indexes to optimise queries that do not use the Clustered Index.
Advantages of Clustered Index
Some of the advantages of using a Clustered index are as follows -
Faster Data Retrieval
Data retrieval is more rapid with an index-based Architecture. Queries that filter the indexed column can execute quickly. Retrieving a range of values from the column is efficient.
Reduced Input/Output Operations
Since the data is physically organised based on the Index, fewer disk Input/Output operations are required to retrieve the data. This results in faster query performance and lower disk Input/Output costs.
Improved Performance for Ordered Data
If the data in the indexed column is ordered frequently, a Clustered index enhances speed by reducing the requirement for sorting operations.
Space Efficient
The Clustered Index is more space-efficient than a Non-Clustered index. It supports the integration of the Indexes within the table structure, so we do not need a separate data structure to store the indexed values.
Updating a row in a Clustered index is slower than updating in a Non-Clustered index. As in Clustered Index, keeping the data in a specific order is necessary. So when a row is updated, other rows sometimes need to be moved to ensure the data remains in the correct order. These results slow down the process.
Less Flexible
It is closely connected to the table structure. It makes it less flexible than a Non-Clustered index. So modifying a Clustered index can be more challenging and may affect the table structure.
More Significant Storage Requirements
A Clustered index can take up more space than a Non-Clustered index if the indexed column has many duplicates.
A Limited Number of Indexes
A table can have only one Clustered Index, meaning we may need to choose between optimising for query performance or data modification performance.
Definition of Non Clustered Index
Non Clustered Index separates the record into a data structure containing an indexed column. It includes the indexed column and a reference pointer to the matching row in the table. Non-Clustered indexes are more flexible in updating the table. It updates the table without changing the structure of the table. They do not interfere with the physical order of the data in the table like Clustered indexes. They provide logical order to retrieve data rather than physical.
Syntax
Step 1 : First, we need to create a table in the Database
CREATE TABLE NinjaTable (
Id INT IDENTITY(1,1) PRIMARY KEY,
FirstName VARCHAR(80),
LastName VARCHAR(80),
Age INT,
);
You can also try this code with Online Javascript Compiler
First, we created a Database and inserted some data. The table has four columns: Id of type Integer, FirstName of type String, LastName of type String and Age of type Integer. Lastly, we define our Non-Clustered Index in the “Age” column. The index will make a copy of the “Age” column along with a reference to the location of the corresponding row in the table.
Non-Clustered Index stores index columns in different data structures rather than the actual table. It has an indexed column and a pointer to the corresponding row.
Physical Order is Unchanged
In the Non-Clustered index physical order of the elements in the table remains unchanged.
Easy to Update
It is more flexible than a Clustered Index. It is simple to change without changing the table structure.
Useful for Frequently Searched Columns
It can also optimise query performance on frequently searched columns. Even it performs better on large tables.
Less Space-Efficient
Non-Clustered Index is less space-efficient than a Clustered Index as it requires extra storage space for the index structure.
Non-Clustered indexes create a distinct structure for searching data, which results in faster data retrieval since the database does not have to scan the entire table.
Efficient Sorting
Non-Clustered indexes are particularly helpful for sorting data as they can rapidly identify the data required without scanning the entire table.
Faster Join Operations
Non-Clustered indexes can speed up the process of joining multiple tables in a query by allowing the database to locate the required data more quickly.
Space Optimisation
It utilises less storage space than Clustered indexes. Because Non-Clustered indexes do not reorganise the data in the table.
Flexibility
Non-Clustered indexes can be created on columns other than the primary key. They provide more options for querying and database design. It also improves performance for a wide range of queries.
Large tables with several Non-Clustered indexes might compromise the database's performance. Indexes must be updated for adding, deleting, and editing data.
Large Disk Space Requirements
A greater amount of disc space is needed to hold the index data for Non-Clustered indexes. It can grow the size of our database.
Not Suitable for Frequently Write Operations
If we have a frequently updated table, the additional overhead is involved in updating the indexes every time data is added, deleted or modified.
May only Cover Some Columns
Non-Clustered indexes are created only on specific columns. If our query requires data from columns not currently indexed, the database will perform more operations to retrieve the data. This will slow down performance.
Difference between Clustered and Non Clustered Index
Below is the difference between Clustered and Non Clustered index -
Parameters
Clustered Index
Non-Clustered Index
Physical Ordering of Data
It determines the physical order of data based on the Index column.
It does not affect the physical ordering of data in the table.
Number of Indexes per Table
Only one Clustered index per table.
Multiple Non-Clusterded Indexes per table.
Key Columns
Good practice to choose the Primary Key.
It can be created on any column of the table.
Index Size
Less than Non-Clustered indexes due to the physical ordering of data.
More than Clustered indexes due to the presence of an additional pointer.
Query Performance
Faster for searching, sorting, or grouping data based on the indexed column.
Faster for queries involving columns not part of the Clustered index or for joining multiple tables.
Insert/Update/Delete Performance
Slower for data modifications.
Faster for data modifications.
Table Size
Generally used for small tables. It is also used for large tables depending on the requirement.
More significant for tables with Non-Clustered indexes because the index size can be substantial.
Characteristics of the Clustered Index:
1. Single Clustered Index per Table: A table can have only one clustered index. The clustered index determines the physical order of data in the table. It is created on the primary key column by default, ensuring unique and sorted values. For example, in a "Students" table, the clustered index could be created on the "StudentID" column, which is the primary key.
2. Sorted Data: The data in the table is physically sorted based on the clustered index key. The index leaf nodes contain the actual data pages of the table. This means that the data is stored in the same order as the clustered index key. For instance, if the clustered index is on the "StudentID" column, the data in the table will be sorted based on the values in that column.
3. Efficient Range Queries: Clustered indexes are highly efficient for range queries. Since the data is physically sorted, range queries can quickly locate the starting point and sequentially scan the data pages until the end of the range. This makes clustered indexes ideal for queries that involve range conditions on the indexed column. For example, a query like "SELECT * FROM Students WHERE StudentID BETWEEN 1000 AND 2000" can benefit from a clustered index on the "StudentID" column.
4. Faster Data Retrieval: Clustered indexes provide faster data retrieval for queries that use the indexed column in the search condition. Since the data is stored in the same order as the index key, the database engine can directly access the data pages without additional lookups. This improves the performance of queries that search for specific values or use the clustered index key in join conditions. For example, a query like "SELECT * FROM Students WHERE StudentID = 1234" can quickly locate the data using the clustered index.
Characteristics of the Non-Clustered Index:
1. Multiple Non-Clustered Indexes per Table: A table can have multiple non-clustered indexes. Each non-clustered index is stored separately from the table data and contains a copy of the indexed columns along with the row pointers. These row pointers reference the actual data pages in the table. For example, a "Students" table can have non-clustered indexes on columns like "LastName" and "Email" in addition to the clustered index on the primary key.
2. Logical Ordering: Non-clustered indexes maintain a logical order of the indexed columns, separate from the physical order of the data in the table. The index leaf nodes contain the index key values and row pointers to the actual data pages. This allows for efficient searching and sorting based on the indexed columns without affecting the physical order of the table. For instance, a non-clustered index on the "LastName" column would enable fast searches and sorting by last name.
3. Covering Queries: Non-clustered indexes can satisfy queries entirely if all the required columns are included in the index key. Such queries are called covering queries. When a query can be answered using only the data in the non-clustered index, without accessing the table data pages, it significantly improves query performance. For example, if there is a non-clustered index on the "LastName" and "Email" columns, a query like "SELECT LastName, Email FROM Students WHERE LastName = 'Smith'" can be satisfied by the index alone.
4. Additional Storage and Maintenance: Non-clustered indexes require additional storage space as they store a copy of the indexed columns and row pointers. Each non-clustered index is maintained separately, and any modifications to the indexed columns or the table data require updating the corresponding non-clustered indexes. This adds overhead to data modification operations. For example, inserting a new row into the "Students" table would require updating all the non-clustered indexes associated with that table.
5. Flexibility in Index Design: Non-clustered indexes offer flexibility in designing the indexing strategy for a table. They allow creating indexes on columns frequently used in search conditions, join conditions, or sorting requirements, even if those columns are not part of the primary key. This enables optimizing queries based on specific access patterns and performance needs. For instance, creating a non-clustered index on the "Email" column can speed up queries that search for students by their email addresses.
Frequently Asked Questions
What is a clustered index in SQL?
A clustered index in SQL organizes the rows of a table physically on disk to match the index's order, enhancing data retrieval efficiency.
What is clustered index and non-clustered index performance?
Clustered indexes improve data access speed as they store rows physically sorted, while non-clustered indexes require additional reads, making them slower.
Can a table have both clustered and nonclustered index?
Yes, a table can have one clustered index and multiple nonclustered indexes, allowing for various optimized query paths.
Conclusion
In this article, we discussed the difference between Clustered and non Clustered index. We went through their Features and Some Implementation section. We learned their Advantages and Disadvantages. We hope you enjoyed this article.
You can visit our other related blogs for more information on these topics.


































 9+ registered
9+ registered 

