



























Introduction
Java HashMap is a Map that uses a hash table for storage, while HashSet is a Set that also employs a hash table for storage.

In this blog, we will learn about HashMap and HashSet Features, Implementation, and their differences. Now let’s go ahead in the blog and learn more interesting differences between HashMap and HashSet.
Also see, Swap Function in Java
What is HashMap?
In Java, HashMap is commonly used. It is useful in a wide range of applications, such as caching systems, database operations, and more. HashMap is a class. It is used to store and retrieve key-value pairs. It is a part of the Java Collections Framework. It also provides a flexible and efficient way to map keys to their corresponding values. In a HashMap, keys are unique and are used to retrieve their associated values. The values can be of any data type, such as strings, integers, or custom objects. HashMap uses a hash function to map keys to their corresponding values, allowing fast retrieval times.
Features of HashMap
Some of the features of HashMap in Java are given below:
-
Iterability: HashMap can be iterated over using iterators, which allow for easy traversal of the key-value pairs stored in the HashMap.
-
Null Values: HashMap allows null values to be stored as keys or values.
-
Fast Lookup: HashMap uses a hash function to map keys to their corresponding values, which allows for fast lookup times. The time complexity on average for operations like put(), get(), and remove() is O(1).
-
Resizable: HashMap can resize dynamically based on the number of elements it contains.
- Not Thread-safe: HashMap is not thread-safe. It also requires synchronization if used in a multi-threaded environment. In such cases, ConcurrentHashMap can be used instead.
Implementation of a HashMap
In Java, HashMap is a data structure. It allows us to store and retrieve key-values. It is an array of buckets for implementation. Here each bucket is a linked list of entries. Each entry in the linked list stores a key-value pair and a next entry in the list. The key is first hashed to generate an index in the bucket array then stored in HashMap. Then the key value pair is added to the linked list. To retrieve a value, the linked list is searched for an entry with the same key. Let’s have a look at Implementation of HashMap code:
Code
- java
java
import java.util.*;
public class HashMapCode {
static class HashMap<K,V> {
private class Node {
K key;
V value;
public Node(K key, V value) {
this.key = key;
this.value = value;
}
}
private int n;
private int N;
private LinkedList<Node> buckets[];
public HashMap() {
this.N = 4;
this.buckets = new LinkedList[4];
for(int i=0; i<4; i++) {
this.buckets[i] = new LinkedList<>();
}
}
private int hashFunction(K key) {
int bi = key.hashCode();
return Math.abs(bi) % N;
}
private int searchInLL(K key, int bi) {
LinkedList<Node> ll = buckets[bi];
for(int i=0; i<ll.size(); i++) {
if(ll.get(i).key == key) {
return i;
}
}
return -1;
}
private void rehash() {
LinkedList<Node> oldBucket[] = buckets;
buckets = new LinkedList[N*2];
for(int i=0; i<N*2; i++) {
buckets[i] = new LinkedList<>();
}
for(int i=0; i<oldBucket.length; i++) {
LinkedList<Node> ll = oldBucket[i];
for(int j=0; j<ll.size(); j++) {
Node node = ll.get(j);
put(node.key, node.value);
}
}
}
public void put(K key, V value) {
int bi = hashFunction(key);
int di = searchInLL(key, bi);
if(di == -1) {
buckets[bi].add(new Node(key, value));
n++;
} else {
Node node = buckets[bi].get(di);
node.value = value;
}
double lambda = (double)n/N;
if(lambda > 2.0) {
rehash();
}
}
public boolean containsKey(K key) {
int bi = hashFunction(key);
int di = searchInLL(key, bi);
if(di == -1) {
return false;
} else {
return true;
}
}
public V remove(K key) {
int bi = hashFunction(key);
int di = searchInLL(key, bi);
if(di == -1) {
return null;
} else {
Node node = buckets[bi].remove(di);
n--;
return node.value;
}
}
public V get(K key) {
int bi = hashFunction(key);
int di = searchInLL(key, bi);
if(di == -1) {
return null;
} else {
Node node = buckets[bi].get(di);
return node.value;
}
}
public ArrayList<K> keySet() {
ArrayList<K> keys = new ArrayList<>();
for(int i=0; i<buckets.length; i++) {
LinkedList<Node> ll = buckets[i];
for(int j=0; j<ll.size(); j++) {
Node node = ll.get(j);
keys.add(node.key);
}
}
return keys;
}
public boolean isEmpty() {
return n == 0;
}
}
public static void main(String args[]) {
HashMap<String, Integer> map = new HashMap<>();
map.put("Ninja1", 70);
map.put("Ninja2", 80);
map.put("Ninja3", 90);
ArrayList<String> keys = map.keySet();
for(int i=0; i<keys.size(); i++) {
System.out.println(keys.get(i)+" "+map.get(keys.get(i)));
}
map.remove("Ninja1");
System.out.println(map.get("Ninja1"));
}
}
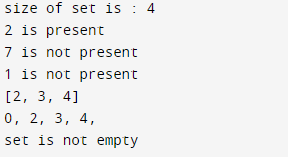
Output



 9+ registered
9+ registered 

