Get a skill gap analysis, personalised roadmap, and AI-powered resume optimisation.
Introduction
Discretization transforms continuous data into discrete buckets or intervals. It's a critical process that simplifies data analysis, making complex datasets more manageable and interpretable. This technique is essential in data mining as it helps convert raw, detailed data into understandable formats.
By categorizing continuous attributes into discrete sets, discretization aids in revealing patterns and trends that might otherwise be hidden in the complexity of the data.
What is Discretization in Data Mining?
Discretization in data mining refers to converting a range of continuous values into discrete categories. In simpler terms, it's like grouping ages into categories like 'child,' 'teen,' 'adult', and 'senior' instead of dealing with each age individually. This method is particularly useful in data mining because it can help uncover patterns and relationships in the data that are not immediately apparent when dealing with continuous values.
For instance, imagine a dataset of patient blood pressure readings. Discretization would involve categorizing these readings into 'low', 'normal', and 'high' groups. This categorization makes it easier to analyze the data, especially when working with machine learning algorithms, which often perform better with discrete input.
The primary goal of discretization is to reduce the complexity of continuous data, making it more digestible for analysis. It simplifies the data without losing its intrinsic value, balancing detail and usability.
Some Famous Techniques of Data Discretization
Data discretization encompasses various techniques, each with its unique approach and application. Understanding these methods is crucial for students venturing into data mining. Let's delve into some of the most well-known discretization techniques:
Equal-Width Intervals
This technique divides the range of attribute values into intervals of equal size. The simplicity of this method makes it popular, especially for initial data analysis. For example, if you're dealing with an attribute like height, you might divide it into intervals of 10 cm each.
Equal-Frequency Intervals
Unlike equal-width intervals, this method divides the data so that each interval contains approximately the same number of data points. It's particularly useful when the data is unevenly distributed, as it ensures that each category has a representative sample.
Cluster Analysis
This more complex technique uses clustering algorithms to group data points based on similarity. The clusters formed represent the intervals. It's a powerful method for discovering natural groupings in the data.
Decision Tree Based
Here, decision trees are used for discretization. The tree splits the continuous attribute at various points, and the resulting tree structure helps determine the intervals. This method is beneficial when the discretization needs to align closely with the predictive modeling goals.
Entropy-Based Discretization
This technique uses information entropy to find the optimal data partitioning. It effectively finds boundaries that provide the most informational gain, making it highly suitable for preparing data for information-theoretic models.
Examples of Discretization in Data Science?
Discretization in data science refers to the process of transforming continuous variables into discrete ones. This technique is useful in various areas:
Feature Engineering: Discretization helps convert continuous features (like age or income) into categorical ones, making them easier to interpret and use in models.
Decision Tree Algorithms: Many decision tree algorithms require discrete variables as input. Discretization prepares continuous data for such algorithms.
Histogram Creation: Discretizing data aids in creating histograms, where continuous data is grouped into bins for visualization and analysis.
Data Privacy: Discretization can also be used for anonymizing data, replacing exact values with ranges or categories to protect privacy.
For example, converting age into age groups (e.g., 0-20, 21-40, etc.) or income into income brackets (e.g., low, medium, high) are common forms of discretization used to simplify analysis or model building processes.
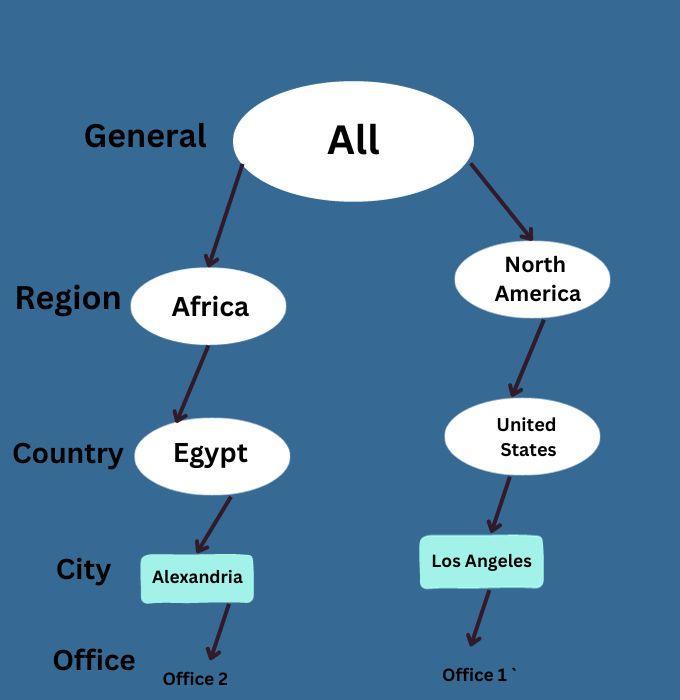
Data Discretization & Concept Hierarchy Generation
This aspect of data mining is about transforming raw data into more abstract layers of knowledge. Concept hierarchy generation is a process that builds upon discretization to further abstract the data. It's like creating a tree where leaves represent the most specific information, and branches represent more general concepts.
For instance, consider a dataset with the attribute 'city'. Discretization might involve categorizing different cities into regions like 'North', 'South', 'East', and 'West'. Concept hierarchy generation takes this a step further by categorizing these regions into even broader categories, such as 'Coastal' and 'Inland'.
The process involves:
Defining Rules for Grouping
Establishing how to group the discrete data into broader categories. It's about deciding what characteristics or properties should be used to create the higher-level groupings.
Building the Hierarchy
This is the actual construction of the hierarchy, where data is organized into a tree-like structure, starting from very specific data points at the bottom and moving up to more general categories.
Applying the Hierarchy in Analysis
Once the hierarchy is built, it can be used to analyze data at different levels of abstraction. This allows for more versatile analysis, from detailed inspection at the lower levels to general trends at the higher levels.
This methodology is especially useful in scenarios where the goal is to understand data at multiple levels of granularity. For example, a retail business might use it to analyze sales data, starting from individual products (lowest level), through product categories (middle level), up to overall sales trends (highest level).
Data Discretization and Binarization in Data Mining
Data discretization and binarization are pivotal in transforming continuous data for effective analysis in data mining. Binarization is a special form of discretization where data is converted into binary formats – typically '0' and '1'. This process is particularly useful when dealing with algorithms that perform better with binary input.
How Binarization Works in Data Mining?
Binary Transformation: Continuous or categorical data is transformed into a binary format. For example, a temperature range can be divided into 'High' (1) and 'Low' (0).
Threshold Setting
This involves determining the cut-off point that distinguishes between the two binary categories. For continuous data, any value above a certain threshold can be set to 1, and below it to 0.
Application in Algorithms
Many machine learning algorithms, especially those based on rules or sets, find it easier to process binary data. This simplicity often leads to more efficient and faster computations.
Example of Binarization
Consider a dataset containing the ages of individuals. To apply binarization, one could set a threshold age, say 50. Ages above 50 would be categorized as '1' (perhaps labeled as 'Senior'), and those below 50 as '0' ('Non-Senior').
Python
Python
ages = [22, 34, 55, 67, 45, 29] binarized_ages = [1 if age > 50 else 0 for age in ages] print(binarized_ages)
You can also try this code with Online Python Compiler
In this Python example, a list comprehension is used to binarize the age data based on the threshold of 50.
Why is Discretization Important?
Discretization plays a crucial role in data mining for several reasons. It transforms continuous or complex data into a simpler, more manageable form, facilitating easier analysis and interpretation. Here's why discretization is so important:
Enhances Data Understanding
By breaking down continuous variables into discrete categories, discretization makes it easier to understand and interpret data. It's like turning a complex story into a series of straightforward chapters.
Improves Machine Learning Model Performance
Many machine learning models, especially categorical models, work more effectively with discrete data. Discretization can improve the accuracy and efficiency of these models.
Reduces Noise in Data
By categorizing data into intervals, discretization can help to smooth out noise, making the underlying patterns in the data more evident.
Simplifies Complex Data
In many real-world scenarios, data can be overwhelmingly complex. Discretization helps in simplifying this data, making it more accessible for analysis and decision-making.
Facilitates Data Visualization
Discrete data is often easier to visualize effectively. It allows for clearer and more interpretable charts and graphs, which is crucial for data analysis and presentation.
Aids in Handling Missing Values: In datasets with missing values, discretization can provide a straightforward approach to categorizing data, thereby dealing with gaps in a sensible and systematic way.
Frequently Asked Questions
Can Discretization Lead to Loss of Information?
Yes, discretization can lead to some loss of information. When continuous data is categorized into discrete intervals, nuances within the intervals might get overlooked. However, the key is to balance between simplifying data for analysis and retaining significant information. The choice of discretization method and the number of categories play a crucial role in minimizing this loss.
How Does Discretization Affect Data Mining Algorithms?
Discretization can significantly impact the performance of data mining algorithms. For algorithms designed to work with categorical data, discretization can make continuous data more compatible, often enhancing the algorithm's effectiveness. However, it's crucial to apply discretization appropriately, as improper use can lead to misleading results or reduced model accuracy.
Is Discretization Always Necessary in Data Mining?
Discretization is not always necessary in data mining, but it's often beneficial. The decision to use it depends on the nature of the data and the specific goals of the analysis. For some datasets, especially those with a strong focus on continuous variables, other methods like normalization or standardization might be more appropriate.
Conclusion
Discretization in data mining serves as a bridge between raw, continuous data and meaningful, categorical insights. It enhances data understanding, facilitates machine learning processes, and aids in effective data visualization and noise reduction. While it sometimes leads to information loss, the benefits of discretization in simplifying and clarifying data make it a valuable tool in the data mining arsenal. Remember, the key to successful discretization lies in choosing the right technique and maintaining a balance between data simplification and information retention. By mastering discretization, students and practitioners in the field of data mining can unlock deeper insights and drive more informed decisions from their data.

































 9+ registered
9+ registered 

