Do you think IIT Guwahati certified course can help you in your career?
Introduction
The efficiency of a Data Structure depends on how efficiently it handles the query of some problem statement. A good choice of data structure can reduce the execution time and that is what comes in handy in real-life problems. Disjoint Set Union (DSU) is one such data structure. It is also referred to as Union Find because of the functionalities it provides.
In computer science, there's something called a disjoint-set data structure which is like a tool for organizing things. Imagine you have a bunch of different sets, like groups of friends. This tool helps keep track of these groups and tells you which things belong to which group. It's like having a way to sort your toys into different boxes so that none of them are in more than one box at the same time.
Today we will discuss Disjoint Set Union or you can say Union Find algorithm from scratch for your better understanding.
What is a Disjoint Set Data Structure?
The union-find algorithm is a data structure that maintains a collection of disjoint sets. It provides two primary operations: union, which merges two sets into one, and find, which determines which set a particular element belongs to. This data structure is used in graph algorithms, to efficiently handle connectivity and partitioning problems.
To understand disjoint sets, let us break the term into two words - disjoint and sets.
What does disjoint mean? Something which isn’t joined, right?
Now, what is the first thing that comes to our mind when we hear the word sets?
All of us are probably thinking of something like this: S = {1, 2, 3, 4, 5}.
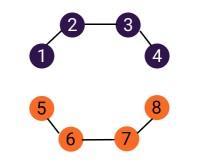
So to understand disjoint sets, let us consider a game of polo. In a game of polo, there are four members on each team. Each member is assigned a jersey number based on the position in which they are playing.
Let us represent this using a graph, where each player is a vertice. For simplicity, I have considered the players 1-4 on the orange team to be numbered from 5-8.
The players in each team can be represented by sets too.
P = {1, 2, 3, 4} and O = {5, 6, 7, 8}
Now, a player of team Purple will not be a player of team orange, so P ∩ O = Φ. In other words, the two sets are disjoint.
Thus,Sets that have no elements in common are known as disjoint sets.
#include <iostream>
#include <vector>
class DisjointSet {
private:
std::vector<int> parent;
public:
DisjointSet(int n) : parent(n) {
for (int i = 0; i < n; ++i)
parent[i] = i; // Initialize each element as its own set
}
int find(int x) {
if (parent[x] == x)
return x;
return parent[x] = find(parent[x]); // Path compression
}
void unionSets(int x, int y) {
int rootX = find(x);
int rootY = find(y);
if (rootX != rootY)
parent[rootY] = rootX; // Union by rank
}
};
int main() {
DisjointSet ds(5);
ds.unionSets(0, 1);
ds.unionSets(2, 3);
ds.unionSets(0, 3);
std::cout << "Parent array after union operations: ";
for (int i = 0; i < 5; ++i)
std::cout << ds.find(i) << " ";
std::cout << std::endl;
return 0;
}
Output:
Parent array after union operations: 0 0 0 0 4
Explanation:
Initially, each element is its own set, so the parent array looks like: [0, 1, 2, 3, 4].
After the union operation ds.unionSets(0, 1), sets containing elements 0 and 1 are merged. The parent array becomes: [0, 0, 2, 3, 4].
After the union operation ds.unionSets(2, 3), sets containing elements 2 and 3 are merged. The parent array remains: [0, 0, 2, 2, 4].
After the union operation ds.unionSets(0, 3), sets containing elements 0 and 3 are merged. Since 0 is the representative element of the set, the parent of 3 becomes 0. The parent array becomes: [0, 0, 2, 0, 4].
The final parent array represents the disjoint sets after all union operations.
Operations on Disjoint Set Data Structures
Two operations that can be performed on Disjoint sets are- find and union. Let us understand what they are one by one.
Find
The find operation in a disjoint set data structure is used to find the representative element (also known as the root) of the set to which a given element belongs. It utilizes path compression to optimize subsequent find operations by making each element point directly to its root.
Implementation:
int find(int x) {
if (parent[x] == x)
return x;
return parent[x] = find(parent[x]); // Path compression
}
Union
The union operation in a disjoint set data structure merges two sets by making one of the representative elements the parent of the other. It employs union by rank to maintain the balance of the resulting disjoint sets, ensuring efficient find operations.
Implementation:
void unionSets(int x, int y) {
int rootX = find(x);
int rootY = find(y);
if (rootX != rootY)
parent[rootY] = rootX; // Union by rank
}
These operations are crucial for efficiently managing disjoint sets, facilitating tasks like connectivity queries and cycle detection in graphs.
Naive Implementation
A naive implementation of disjoint set data structure involves directly implementing the basic operations without any optimizations like path compression or union by rank. In this approach, the find operation typically traverses the parent pointers until it reaches the root element, without any optimization for path compression. Similarly, the union operation simply merges two sets without considering their sizes or depths, leading to potentially unbalanced trees.
Naive Find Implementation:
int find(int x) {
while (x != parent[x]) {
x = parent[x];
}
return x;
}
Naive Union Implementation:
void unionSets(int x, int y) {
int rootX = find(x);
int rootY = find(y);
if (rootX != rootY) {
parent[rootY] = rootX;
}
}
While this naive approach is straightforward to implement, it may result in inefficient find operations, especially when dealing with large disjoint sets or heavily interconnected data structures. Consequently, it's generally less performant compared to optimized implementations utilizing techniques like path compression and union by rank.
Optimizations
In disjoint set data structures, optimizations are employed to enhance the efficiency of operations such as finding the representative element of a set and merging two sets. These optimizations aim to reduce the time complexity of these operations, making them more suitable for practical applications, especially in scenarios involving large datasets or frequent operations.
There are two ways to improve it
Path Compression
Union by Rank
Path Compression
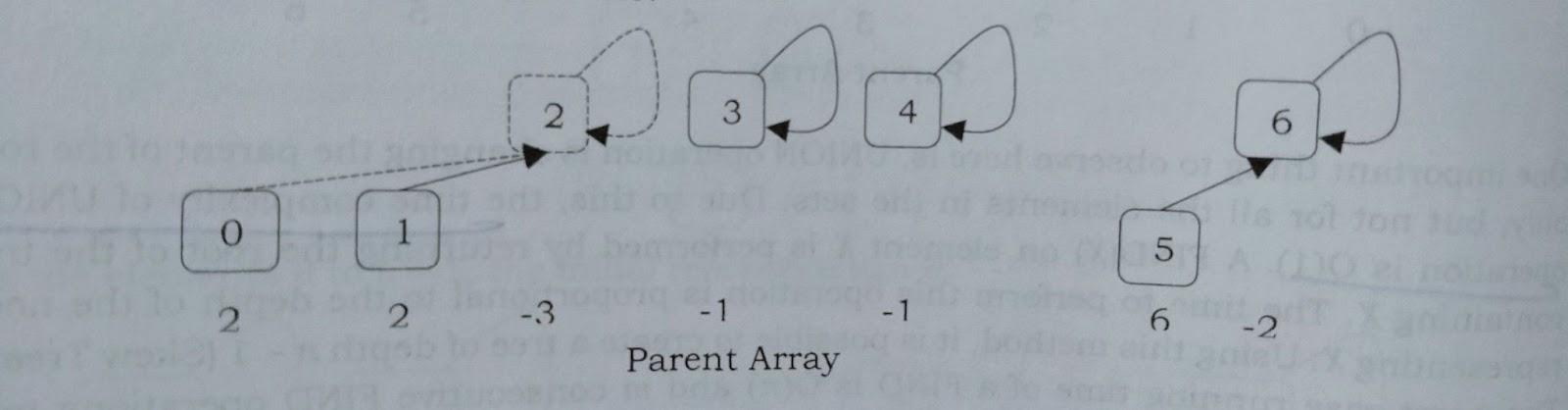
Path compression is a method of flattening the tree structure when find_set(x) is used on it.
This optimization is designed for speeding up the find_set(x) operation.
If we call find_set(x) for some vertex x, we actually find the representative p for all vertices that we visit on the path between x and the actual representative p.
Here the trick is to make the paths for all those nodes shorter, by setting the parent of each visited vertex directly to p.
Therefore, the resulting tree is much flatter, which speeds up future operations on these elements as well as those that reference them.
Consider the below diagram for better understanding:
The left side shows a tree whereas the right side shows a compressed tree for visited nodes 2,3,5,7.
Implementation
The new implementation of find_set(x) is as follows:
int find_set(int v) {
if (v == parent[v])
return v;
return parent[v] = find_set(parent[v]);
}
Complexity Analysis
Time Complexity: O(log N), where n is the number of nodes.
Space Complexity: O(n), where n is the number of nodes.
Let’s move on to other optimization i.e. union by rank without further ado.
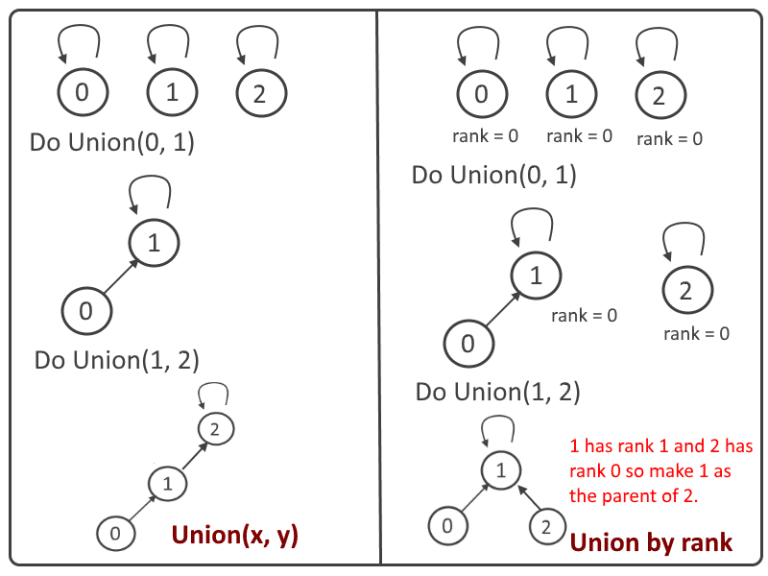
Union by Rank
As we already know when we call find_set(x) and find_set(y) is called it finds the roots that belong to the trees x and y. If the roots of the trees are distinct, the trees are merged by connecting the roots of one to the roots of the other. If this is done carelessly, such as by always making x a child of y, the trees' height can grow as O(n).
We can improve it by employing union by rank.
There are numerous ways that can be taken into account. Here we will discuss the two most popular and most used:
Union by rank based on size
Union by rank based on depth
The underlying principle of the optimization is the same in both approaches: we attach the tree with the lower rank to the one with the higher rank.
Union by rank based on size
Earlier, we stored i (in the parent array) for the root element and the parent of i for other elements. However, in this approach, we store the reverse of the tree size (that is, if the tree size is 3, we store –3 in the parent array for the root element).
Assume that the size of one element set is 1 and store – 1. Other than this there is no change.
Implementation
void make_set(int v) {
parent[v] = v;
size[v] = -1;
}
void union_sets(int a, int b) {
a = find_set(a);
b = find_set(b);
if (a != b) {
if (abs(size[a]) < abs(size[b]))
swap(a, b);
parent[b] = a;
size[a] += size[b];
}
}
Union by rank based on depths
In contrast with UNION by size, in this method, we store the depths instead of height because path compression will change the trees’ heights over time.
Each element is associated with a rank. Initially, a set has one element and a rank of zero.
Implementation
void make_set(int v) {
parent[v] = v;
rank[v] = 0;
}
void union_sets(int a, int b) {
a = find_set(a);
b = find_set(b);
if (a != b) {
if (rank[a] < rank[b])
swap(a, b);
parent[b] = a;
if (rank[a] == rank[b])
rank[a]++;
}
}
Note: For the find_set(x) operation there is no change in the implementation.
Complexity Analysis
Both optimizations are equivalent in terms of time and space complexity.
Time Complexity: O(log N), where n is the number of nodes.
Space Complexity: O(n), where n is the number of nodes.
So in practice, you can use any of them.
Implementation of Disjoint Set
Now that we know the working of the union-find algorithm, we can write the code for it. I’m sure you can write the code yourself, but here’s the solution of all the operations in one place just in case.
C++
C++
// C++ implementation of disjoint set #include <iostream> using namespace std; class DisjointSet { int *rank, *parent, n;
public: // Constructor to create and // initialize sets of n items DisjointSet(int n) { rank = new int[n]; parent = new int[n]; this->n = n; make_set(); }
// Creates n single item sets void make_set() { for (int i = 0; i < n; i++) { parent[i] = i; } }
// Finds set of given item x int find_set(int x) { // Finds the representative of the set // that x is an element of if (parent[x] != x) {
// if x is not the parent of itself // Then x is not the representative of // his set, parent[x] = find_set(parent[x]);
// so we recursively call Find on its parent // and move i's node directly under the // representative of this set }
return parent[x]; }
// Do union of two sets represented // by x and y. void Union(int x, int y) { // Find current sets of x and y int xset = find_set(x); int yset = find_set(y);
// If they are already in same set if (xset == yset) return;
// Put smaller ranked item under // bigger ranked item if ranks are // different if (rank[xset] < rank[yset]) { parent[xset] = yset; } else if (rank[xset] > rank[yset]) { parent[yset] = xset; }
// If ranks are same, then increment // rank. else { parent[yset] = xset; rank[xset] = rank[xset] + 1; } } };
Disjoint set data structures find applications in various fields where efficient management of disjoint sets and connectivity queries is required. Some common applications include:
Graph Algorithms: Disjoint sets are often used in graph algorithms such as Kruskal's minimum spanning tree algorithm and Borůvka's algorithm for finding the minimum spanning tree. They facilitate efficient connectivity checks and cycle detection in graphs.
Dynamic Connectivity: Disjoint sets are used to solve dynamic connectivity problems where elements are dynamically added or removed, and connectivity queries need to be answered efficiently. Applications include network connectivity problems and social network analysis.
Image Processing: Disjoint sets are utilized in image processing tasks like image segmentation, where pixels with similar attributes are grouped together into segments or regions. Disjoint set data structures help efficiently manage these segments and perform operations such as merging or splitting them based on certain criteria.
Union-Find Applications: Disjoint sets are commonly used in various union-find applications, including data compression algorithms like Huffman coding, which require efficient union and find operations for merging and querying disjoint sets of elements.
Dynamic Graph Operations: In dynamic graph scenarios where edges and vertices are added or removed dynamically, disjoint set data structures help maintain the connectivity status of the graph efficiently. Applications include network routing algorithms and database management systems.
Optimization Problems: Disjoint sets are used in optimization problems such as clustering and partitioning, where elements need to be grouped into disjoint sets based on certain criteria to optimize objectives like resource allocation or load balancing.
Frequently asked question
What is union-find in algorithm?
Union-Find, also known as disjoint set data structure, is used to efficiently manage disjoint sets of elements. It supports two main operations: union, which merges two sets, and find, which determines the set to which an element belongs.
What is union-find in Kruskal's algorithm?
In Kruskal's algorithm for finding the minimum spanning tree of a graph, the union-find data structure is used to efficiently determine whether adding an edge creates a cycle in the spanning tree. This is achieved by maintaining disjoint sets for the vertices and merging sets of connected vertices during the algorithm's execution.
What is the merge union-find algorithm?
The Merge Union-Find algorithm is an alternative implementation of the union-find data structure that uses a more efficient approach for the union operation. It employs path compression and union by rank optimizations to ensure efficient merging of sets and fast find operations.
What is union-find in a matrix?
Union-Find in a matrix refers to using the union-find data structure to efficiently manage connected components in a matrix or grid. It helps determine connectivity between elements in the matrix, facilitating tasks like identifying islands in a grid or solving percolation problems in computer science and physics.
Conclusion
In this article, we learned about the Disjoint Set (Union Find Algorithm). The Disjoint Set data structure, also known as the Union-Find algorithm, stands as a powerful tool in computer science, offering efficient solutions to various problems requiring management of disjoint sets and connectivity queries. From graph algorithms like Kruskal's minimum spanning tree to dynamic connectivity problems and image processing tasks, the versatility of Union-Find finds applications across diverse fields.
We hope this blog has helped you enhance your Union Find knowledge. Check out our articles to learn more about the Kruskal’s algorithm, Basics of C++, and real-world API. Practice makes a man perfect.
Happy Coding!
Live masterclass
Resume & linkedin tips to crack Amazon GenAI Interviews
by Anubhav Sinha
30 Jul, 2026
12:30 PM
Master PowerBI using Flipkart Dataset & Ace 20LPA+ Data Roles
by Prerita Agarwal
27 Jul, 2026
12:30 PM
Multi-Agent AI Support Bot using OpenAI & Gemini
by Saurav Prateek
28 Jul, 2026
12:30 PM
Zomato Data Analysis Case Study: Ace 25L+ Roles in FoodTech(no use)
by Abhishek Soni
29 Jul, 2026
11:30 AM
Zomato Sales Analytics: SQL + PowerBI for 25LPA Jobs
by Abhishek Soni
29 Jul, 2026
11:30 AM
Resume & linkedin tips to crack Amazon GenAI Interviews
by Anubhav Sinha
30 Jul, 2026
12:30 PM
Master PowerBI using Flipkart Dataset & Ace 20LPA+ Data Roles































 9+ registered
9+ registered 

