Do you think IIT Guwahati certified course can help you in your career?
Introduction
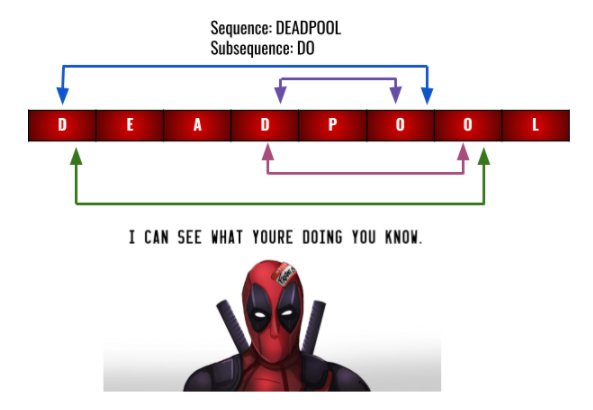
A sequence is an order of elements arranged linearly. Asubsequence is a part of a sequence created by accepting some of the elements in the order they are pushed into the sequence. Consider the example given below:
Problem Statement
Given a sequence and a subsequence, find the number of distinct subsequences in the given sequence.
Example
Input
Enter sequence: deadpool
Enter subsequence: do
Output
Number of distinct subsequences: 4
Recommended: Try theProblemyourself before moving on to the solution.
Method 1: Recursion
Approach
Recursion is all about using a top-down approach. A problem with bigger input is broken down into the same problem with smaller inputs. Iterate through the sequence. If the current elements of the sequence and subsequence are equal, recursively find the rest of the subsequence in the remaining sequence.
Whenever current elements of sequence and subsequence are the same, a choice has to be made as to whether to consider the element. Thus, the number of distinct subsequences can be found using Recursion. For a better understanding, refer to the algorithm given below:
Algorithm
Call the distinctSubsequences() function with ‘SEQ_INDEX’and ‘SUBSEQ_INDEX’arguments as 0 (‘SEQ_INDEX’ and ‘SUBSEQ_INDEX’represent respective indices of sequence and subsequence).
If ‘SUBSEQ_INDEX’= 0 (subsequence is found), then:
Return 1.
If ‘SEQ_INDEX’ = 0 (sequence is ended and subsequence is not found), then:
Return 0.
If SUBSEQUENCE[SUBSEQ_INDEX] = SEQUENCE[‘SEQ_INDEX’](current elements are same), then:
Set OUTPUT1 = distinctSubsequences(SEQ_INDEX + 1, SUBSEQ_INDEX + 1) (recursive call for considering the element).
Set OUTPUT2 = distinctSubsequences(SEQ_INDEX + 1, SUBSEQ_INDEX) (recursive call for ignoring the element).
Return OUTPUT1 + OUTPUT2.
Else (current elements are different):
Return distinctSubsequences(SEQ_INDEX + 1, SUBSEQ_INDEX) (recursive call for ignoring the element).
#include <iostream>
#include <vector>
using namespace std;
string sequence, subsequence;
int distinctSubsequences(int seqIndex, int subseqIndex)
{
// Subsequence is found.
if (subseqIndex == subsequence.length())
return 1;
// Subsequence is not found and sequence is traversed.
if (seqIndex == sequence.length())
return 0;
// If current elements of subsequence and subsequence are equal.
if (subsequence[subseqIndex] == sequence[seqIndex])
{
/* Consider the current element in subsequence found and move on to find the next element of subsequence. */
int output1 = distinctSubsequences(seqIndex + 1, subseqIndex + 1);
/*Ignoring the current element of the sequence and moving on with the current subsequence. */
int output2 = distinctSubsequences(seqIndex + 1, subseqIndex);
return output1 + output2;
}
// If current elements of subsequence and subsequence are not equal.
return distinctSubsequences(seqIndex + 1, subseqIndex);
}
int main()
{
cout << "Enter sequence: ";
cin >> sequence;
cout << "Enter subsequence: ";
cin >> subsequence;
cout << "Number of distinct subsequences: ";
cout << distinctSubsequences(0, 0);
}
You can also try this code with Online C++ Compiler
Time complexity: In the worst case, two recursive function calls are made for every index. So, the number of function calls becomes double with every index. The time complexity is O(2N).
Space complexity: For every recursive call constant space is required to store block level variables. As the number of recursive calls is 2N, the depth of the recursion tree will be ‘N’ resulting in space complexity of O(N).
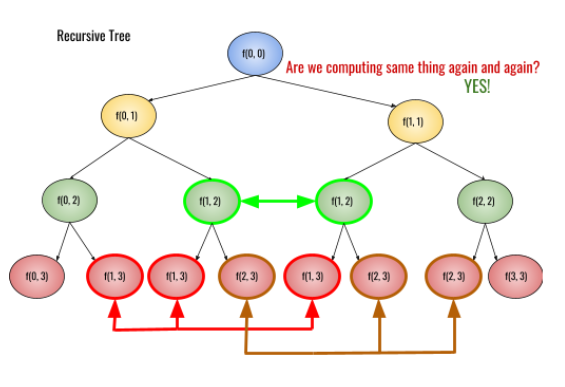
Take a look at the recursion tree shown in the figure below:
With the increase in the size of the recursive tree, the recursive function is called multiple times with the same input argument. Memoization can prune the recursive tree by storing the results of recursive calls. All you need to do is to make some tiny changes in our recursion recipe.
What should we memoize? The recursive function calls are multiplying on the sequence index(seqIndex) and subsequence index(subSeqIndex). We can use a 2-D vector to store the output of various seqIndex-subSeqIndex pairs. The minor modification in our recursion algorithm can help us avoid the exponential time complexity. Thus, the number of distinct subsequences can be found using memoization. Refer to the algorithm given below to understand how to memoize the recursion. (See Dynamic Programming)
Algorithm
Initialize a 2-D vector ‘MEMO’ of size (sequence length x subsequence length) with values -1.
Call the DISTINCT_SUBSEQUENCES() function with ‘SEQ_INDEX’and ‘SUBSEQ_INDEX’arguments as 0 (‘SEQ_INDEX’ and ‘SUBSEQ_INDEX’represent respective indices of sequence and subsequence).
If ‘SUBSEQ_INDEX’= 0 (subsequence is found), then:
Return 1.
If ‘SEQ_INDEX’ = 0 (sequence is ended and subsequence is not found), then:
Return 0.
If MEMO[SEQ_INDEX ][SUBSEQ_INDEX ] is not equal to -1, then:
Return MEMO[SEQ_INDEX ][SUBSEQ_INDEX ].
If SUBSEQUENCE[SUBSEQ_INDEX] = SEQUENCE[‘SEQ_INDEX’](current elements are same), then:
Set ‘OUTPUT1’ = DISTINCT_SUBSEQUENCES(‘SEQ_INDEX’ + 1, ‘SUBSEQ_INDEX’ + 1) (recursive call for considering the element).
Set ‘OUTPUT2’ = DISTINCT_SUBSEQUENCES(‘SEQ_INDEX’ + 1, ‘SUBSEQ_INDEX’) (recursive call for ignoring the element).
Set MEMO[SEQ_INDEX ][SUBSEQ_INDEX ] = ‘OUTPUT1’ + ‘OUTPUT2’.
Else (current elements are different):
Set MEMO[SEQ_INDEX ][SUBSEQ_INDEX ] = DISTINCT_SUBSEQUENCES(‘SEQ_INDEX’ + 1, ‘SUBSEQ_INDEX’) (recursive call for ignoring the element).
Return MEMO[SEQ_INDEX ][SUBSEQ_INDEX ].
Code
#include <iostream>
#include <vector>
using namespace std;
string sequence, subsequence;
int distinctSubsequences(int seqIndex, int subseqIndex, vector< vector<int>> &memo)
{
// Subsequence is found.
if (subseqIndex == subsequence.length())
return 1;
// Subsequence is not found and sequence is ended.
if (seqIndex == sequence.length())
return 0;
// Checking lookup before recursive calls.
if (memo[seqIndex][subseqIndex] != -1)
return memo[seqIndex][subseqIndex];
// If current elements of subsequence and subsequence are equal.
if (subsequence[subseqIndex] == sequence[seqIndex])
{
/* Consider the current element in subsequence found and move on to find the next element of subsequence. */
int output1 = distinctSubsequences(seqIndex + 1, subseqIndex + 1, memo);
/*Ignoring the current element of the sequence and moving on with the current subsequence. */
int output2 = distinctSubsequences(seqIndex + 1, subseqIndex, memo);
// Storing the output of recursive calls before return.
memo[seqIndex][subseqIndex] = output1 + output2;
}
else
{
// Storing the output of recursive calls before return.
memo[seqIndex][subseqIndex] = distinctSubsequences(seqIndex + 1, subseqIndex, memo);
}
return memo[seqIndex][subseqIndex];
}
int main()
{
cout << "Enter sequence: ";
cin >> sequence;
cout << "Enter subsequence: ";
cin >> subsequence;
// Creating a 2D vector.
int seqLength = sequence.length();
int subseqLength = subsequence.length();
vector< vector<int>> memo;
// 2D vector initialization with value -1.
memo.resize(seqLength, vector<int>(subseqLength, - 1));
cout << "Number of distinct subsequences: ";
cout << distinctSubsequences(0, 0, memo);
}
You can also try this code with Online C++ Compiler
Enter sequence: steveRogers
Enter subsequence: ster
Output
Number of distinct subsequences: 3
Complexity Analysis
Time complexity: As the recursive function is memoized, every recursion call will be run only once. The maximum number of SEQ_INDEX - SUBSEQ_INDEX pairs possible as recursion function arguments are sequence length x subsequence length. So, the time complexity is O(N x M), where ‘N’ = sequence length and ‘M’ = subsequence length.
Space Complexity: Extra space is used to memoize the code. The size of the memo vector is equal to sequence length x subsequence length. So, the space complexity is O(N x M), where N = sequence length and M = subsequence length.
Method 3: DP with Tabulation
Unlike recursion, DP with tabulation follows a bottom-up approach(from smaller input to bigger input). The solution is built using the base case as it is the smallest input possible. Let’s see how we can do it for our problem statement.
To build the solution for problems with bigger input using smaller size problems, we need to store the results of the latter. Remember, The maximum number of seqIndex-subSeqIndex pairs possible is sequence length x subsequence length.
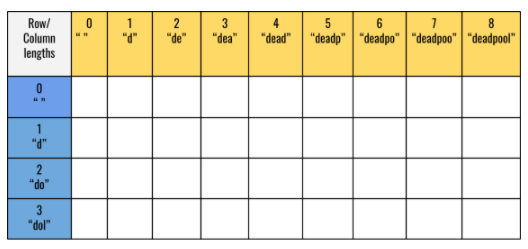
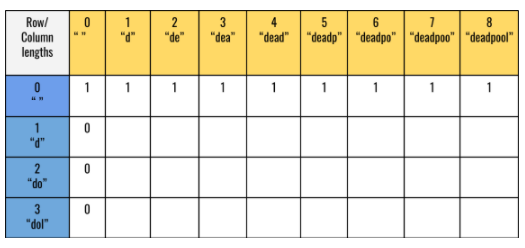
Let’s store the outputs of the possible inputs in a 2-D integer vector dp. The row indices represent subsequence lengths,whereas columns represent the sequence lengths. For sequence = “deadpool” and subsequence = “dol”, the dp vector may look like the figure given below:
Try to find the smallest input possible. The smallest possible input is one where the recursive call for a smaller input is not possible. We have two base cases:
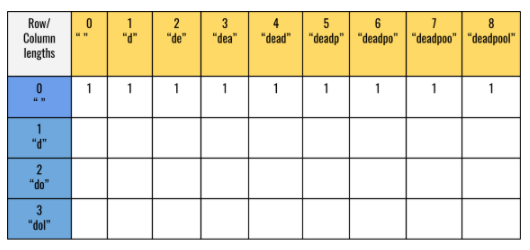
When the subsequence is an empty string: The output for this case should be 1. Because every sequence has an empty sequence as a subsequence. So, the table now looks like the figure given below:
2. When the sequence is an empty string: If the sequence is empty, the subsequence can not be found in the sequence. So, the output should be 0 for this case. Even for an empty sequence, an empty subsequence is possible. So, if the subsequence is also empty, the output should be 1. After handling both the base case, the table looks like the figure given below:
Every cell represents the output for the current sequence and subsequence length. Thus, Cell dp[3][8] represents the output of the problem statement.
How to fill the rest of the cells? Remember, in recursion, every time we encounter the same current elements in sequence and subsequence, either ignore the current element and move forward, or we can consider the current element. This is where recursive calls were made. For dynamic programming, we assume that the results of recursive calls are already stored in our dp vector.
Thus, the number of distinct subsequences can be found using tabulation. Refer to the algorithm given below for a better understanding.
Algorithm
Set ‘SEQ_LENGTH’= length of the sequence.
Set ‘SUBSEQ_LENGTH’ = length of the subsequence.
Initialize the ‘DP’vector of size (seqLength +1) x (subseqLength+1) with 0.
For variable i = 0 to ‘SEQ_LENGTH’:
Set DP[0][i] = 1.
For variable i = 1 to ‘SEQ_LENGTH’:
For variable j = 1 to ‘SUBSEQ_LENGTH’ :
If SEQUENCE[i - 1] = SUBSEQUENCE[j - 1], then:
Set DP[i][j] = DP[i - 1][j - 1] + DP[i][j - 1].
Else:
Set DP[i][j] = DP[i][j - 1].
Return DP[SEQ_LENGTH][SUBSEQ_LENGTH].
Code
#include <iostream>
#include <vector>
using namespace std;
int distinctSubsequences(string sequence, string subsequence)
{
// Creating a 2D vector.
int seqLength = sequence.length();
int subseqLength = subsequence.length();
vector< vector<int>> dp;
// 2D vector initialization with value 0.
dp.resize(subseqLength + 1, vector<int>(seqLength + 1, 0));
// When the subsequence is an empty string, the output should be 1.
for (int i = 0; i <= seqLength; i++)
dp[0][i] = 1;
for (int i = 1; i <= subseqLength; i++)
{
for (int j = 1; j <= seqLength; j++)
{
// If current elements are equal.
if (subsequence[i - 1] == sequence[j - 1])
dp[i][j] = dp[i - 1][j - 1] + dp[i][j - 1];
else
dp[i][j] = dp[i][j - 1];
}
}
return dp[subseqLength][seqLength];
}
int main()
{
string sequence, subsequence;
cout << "Enter sequence: ";
cin >> sequence;
cout << "Enter subsequence: ";
cin >> subsequence;
cout << "Number of distinct subsequences: ";
cout << distinctSubsequences(sequence, subsequence);
}
You can also try this code with Online C++ Compiler
Time Complexity: The code runs on two nested linear loops. So, the time complexity is O(N2).
Space Complexity: Extra space is used to create the ‘DP’vector. The size of the ‘DP’ vector is equal to (sequence length + 1) x (subsequence length + 1). So, the space complexity is O(N x M), where ‘N’ = sequence length and ‘M’ = subsequence length
Frequently Asked Questions
How is a substring different from a subsequence?
A substring consists of consecutive characters that occur in a string or an empty string however subsequences are strings that maintain the original order of occurrence of the characters but do not necessarily include only adjacent characters.
Can a subsequence be a substring?
Yes, a subsequence can be a substring provided all the characters in the subsequence are adjacent to the next character in the sequence or the subsequence is empty. A substring however can is always a subsequence.
Which one is better Recursion or Recursion with Memonisation?
Recursion with Memonisation is better than just recursion as it helps to avoid recomputation of the cases that have already been accounted for. We can store the result of a case and use it later on if required instead of computing it again.
Conclusion
You have learned three different methods to find the number of distinct subsequences for a given sequence. We have given our best to help you understand the concepts required to solve this problem. But your work is not done here. Even the sequence “deadpool” has “do” embedded four times in it. So, do more than just read the stuff. Good coders always practice what they learn. Head over to Coding Ninjas Studio to practice what you have learned.































 9+ registered
9+ registered 

