Do you think IIT Guwahati certified course can help you in your career?
Introduction
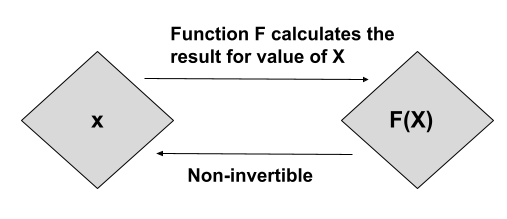
Double hashing is a method used in computer science to resolve collisions in a hash table. A hash table is a data structure that stores key-value pairs and uses a hash function to map keys to their corresponding values.
There are numerous techniques for storing and accessing data in computer systems. Hashing utilizes an algorithm best suited for the users' needs and clubs similar pieces of data together or provides a unique id that helps in accessing the data stored in the system. Let us take a detailed look into it.
What is Hashing?
Hashing is the technique of modifying any given key and mapping its value into a hash table. This hash table stores the keys and the corresponding values, which can be directly accessed through the key. Thehash functionis used to assign a value to a key, using which the element can be accessed in constant time(O(1)). So, operations like searching, insertion, and deletion become much easier and faster. A good hash function uses a one-way hashing algorithm or message-digest, which makes it challenging to generate the original string from the hash function. Hashing plays quite an important role in cryptography, data encryption, password authentication, and Cyber security.
What is Double Hashing?
Double hashing is a method used to resolve collisions in a hash table. A hash table is a Data Structure that stores key-value pairs and uses a hash function to map keys to their corresponding values. When multiple keys map to the same value, it creates a collision. Double hashing is a technique to resolve these collisions by using two different hash functions to map keys to values.
When a collision occurs, the first hash function determines the initial position for the key-value pair in the table. If that position is already occupied, the second hash function calculates an offset from the initial position. The key-value pair is then stored in the next available position, the sum of the initial position and the offset.
This method of resolving collisions can help to reduce the number of collisions and improve the performance of a hash table. However, it does require more computation to calculate the offset, which can increase the time required to insert or look up a key-value pair.
Collisions in Double Hashing
When the hash value of a key corresponds to an already occupied bucket in the hash table, it is referred to as a collision. It occurs when more than one value added to a particular hash table occupies the same slot in the table generated by the hash function.
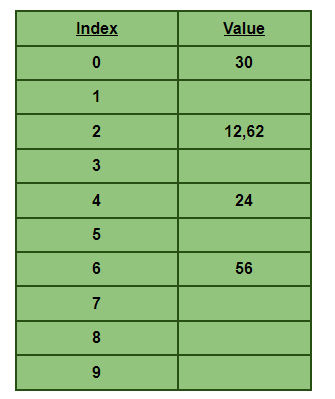
For example, let us consider a hash table with size 10, where the following items are to be stored:12, 24, 56, 30, 62.
Let us assume that the hash function is given by: H1(K) = K % 10
We take the numbers one by one, apply the hash function to it, and the result tells us the index that the numbers will occupy in the hash table.
Applying the hash function, to the given numbers,
H1(12) = 12 % 10 = 2
H1(24) = 24 % 10 = 4
H1(56) = 56 % 10 = 6
H1(30) = 30 % 10 = 0
H1(62) = 62 % 10 = 2 ← Collision Occurs
Thus, a collision occurs at the 2ndindex, where both the values produce the same value of 2 after passing through the hash function.
Double hashing is used to resolve collisions in a hash table, which can occur when multiple keys map to the same value. There are a few reasons why double hashing is useful in this situation:
Improved performance: Double hashing can help to reduce the number of collisions and improve the performance of a hash table. Since the second hash function is used to calculate an offset, it is less likely that the same position will be occupied multiple times, reducing the number of collisions.
Better distribution of keys: Double hashing can help to distribute keys more evenly across the hash table, which can improve the overall performance of the hash table.
Flexibility: Double hashing can be used with different types of hash functions, which means that it can be easily adapted to different situations.
Robustness: Double Hashing is more robust to the poor choice of the primary hash function.
Implementation of Double Hashing
// Implementation of double hashing.
#include <bits/stdc++.h>
using namespace std;
// Predefining the size of the hash table.
#define SIZE_OF_TABLE 11
// Used for the second hash table.
// 8 and 11 are coprime numbers.
#define CO_PRIME 8
// Defining the hashTable vector.
vector<int> hashTable(SIZE_OF_TABLE);
class DoubleHash
{
int size;
public:
// To check whether the table is full or not.
bool isFull()
{
// In case the table becomes full.
return (size == SIZE_OF_TABLE);
}
// Calculating the first hash.
int hash1(int key)
{
return (key % SIZE_OF_TABLE);
}
// Calculating the second hash.
int hash2(int key)
{
return (CO_PRIME - (key % CO_PRIME));
}
DoubleHash()
{
size = 0;
for (int i = 0; i < SIZE_OF_TABLE; i++)
hashTable[i] = -1;
}
// Function for inserting a key into the hash table.
void insertHash(int key)
{
// We first check whether the hash is full or not.
if (isFull())
return;
// Obtaining the index from the first hash table.
int index = hash1(key);
// In case a collision occurs.
if (hashTable[index] != -1)
{
// Obtaining the index from second hash table.
int index2 = hash2(key);
int i = 1;
while (1)
{
// Obtaining the new index.
int newIndex = (index + i * index2) % SIZE_OF_TABLE;
//If no collision occurs, the key is stored.
if (hashTable[newIndex] == -1)
{
hashTable[newIndex] = key;
break;
}
i++;
}
}
//If no collision occurs, the key is stored.
else
hashTable[index] = key;
size++;
}
// For searching a key in the hash table.
void search(int key)
{
int i1 = hash1(key);
int i2 = hash2(key);
int i = 0;
while (hashTable[(i1 + i * i2) % SIZE_OF_TABLE] != key)
{
if (hashTable[(i1 + i * i2) % SIZE_OF_TABLE] == -1)
{
cout << key << " does not exist" << endl;
return;
}
i++;
}
cout << key << " found" << endl;
}
// For displaying the complete hash table.
void displayHash()
{
for (int i = 0; i < SIZE_OF_TABLE; i++)
{
if (hashTable[i] != -1)
cout << i << " --> "
<< hashTable[i] << endl;
else
cout << i << endl;
}
}
};
// Driver's code.
int main()
{
// Assuming the number of initial values to be 5.
int n = 5, i, k;
int a[100];
// We first need to insert keys into the table.
DoubleHash hash;
cout << "Enter 5 values: \n";
for (int i = 0; i < n; i++)
{
cin >> a[i];
hash.insertHash(a[i]);
}
// First, we search for a key that is present in the table.
cout << "Enter a key that you want to search \n";
cin >> k;
hash.search(k);
// Lets display the hash table.
// Since we took the SIZE_OF_TABLE as 11 we will get the indices from 0-10.
cout << "\n The hash table looks like:\n";
hash.displayHash();
return 0;
}
You can also try this code with Online C++ Compiler
Best Case: In the best case, no collision would occur and thus, the time complexity will be given by O(1).
Average Case: The average case time complexity is also given by O(1). However, its proof is too complex to be discussed here.
Worst Case: In the worst case, we have to probe over all N elements; thus the time complexity is given by O(N).
Space Complexity of Double Hashing
Hash tables usually have a maximum capacity of some constant multiplied by N (the constant is predetermined and N is the total number of elements.)
Thus the space complexity of double hashing is O(N).
Advantages of Double Hashing
No extra space is required.
Primary Clustering does not occur.
Secondary Clustering also does not occur.
It can be used with different types of hash functions.
It reduces the clustering effect of keys and decreases the chance of keys being stored in consecutive buckets.
Disadvantages of Double Hashing
Poor cache performance.
It's a little complicated because it uses two hash functions.
It has a bit harder implementation.
It consumes more memory than other collision resolution techniques.
It may not be the best choice for small tables.
Frequently Asked Questions
What is the purpose of double hashing?
The purpose of double hashing is to resolve collisions in a hash table. However, multiple keys may map to the same value in some cases, creating a collision. Double hashing is a technique used to resolve these collisions.
How do you find double hashing?
We first create a hash table with a fixed size to find double hashing. Afterward, with the help of two hash functions, we determine the initial position and offset. If the initial position is occupied, use the offset to determine the next position.
What are the 3 types of hashing?
The three types of hashing techniques are linear hashing, chaining and Cuckoo hashing. Each one has its own characteristics and trade-offs. Linear Hashing and Chaining are simpler to implement, but Cuckoo Hashing is more efficient in average-case performance.
Conclusion
So, this blog discussed the various types of hashing techniques and how Double Hashing proves to be the best technique to resolve collisions. It threw some light on the implementation of double hashing and a comparison between other methods as well.































 8+ registered
8+ registered 

