Do you think IIT Guwahati certified course can help you in your career?
Introduction
Strings are a fundamental data type in programming, often used to represent text and manipulate textual data. One common problem when working with strings is identifying duplicate characters, which can be crucial in various applications such as data validation, text analysis, and optimization tasks. Whether you're developing a spell checker, creating a text-based game, or simply performing data cleaning, knowing how to efficiently find and handle duplicate characters in a string can significantly enhance your program's functionality and performance. In this blog, we will explore different approaches to identifying duplicate characters in a string.
What Are Duplicate Characters in a String?
Duplicate characters in a string are characters that appear more than once. Identifying these repeated characters is a common task in Java string manipulation, often needed for optimizing data, removing redundancy, or validating input.
Example:
Input: "programming" Output: r, g, m Explanation: The characters r, g, and m appear more than once in the string.
How Are Duplicates Recognized? Duplicate characters are recognized by iterating through the string and counting the number of times each character appears. If a character appears more than once, it's considered a duplicate. In Java, this is typically done using a HashMap<Character, Integer> to store and track frequencies.
Why Is This Problem Important in Java?
Data Cleaning and Optimization: Detecting duplicate characters in Java is essential when cleaning datasets or optimizing strings for storage or transmission. Removing or flagging redundant characters reduces unnecessary processing.
Common in Java Coding Interviews: This is a frequently asked question in Java coding interviews. It tests problem-solving ability, mastery of Java string manipulation, and understanding of core concepts such as loops and conditionals.
Reinforces Key Java Concepts: Solving the duplicate characters in Java problem helps developers practice with collections like HashMap and HashSet. It also deepens understanding of string traversal, character encoding, and efficient memory usage.
Why Identifying Duplicate Characters is Important
Identifying duplicate characters in strings is a valuable task in programming and data processing. It helps ensure data quality, supports input validation, and enhances security by enforcing uniqueness where required, such as in usernames or passwords. Detecting duplicates can also optimize data compression algorithms by reducing redundancy and identifying patterns for efficient storage. In frequency analysis, particularly in fields like natural language processing and cryptography, understanding character repetition can reveal hidden structures or potential security vulnerabilities. Additionally, detecting unintended duplicates can help uncover bugs in data entry or processing systems, ultimately improving the reliability and performance of software applications.
Common Use Cases in Real-World Applications
Duplicate character detection is widely used in real-world scenarios. For instance, text editors and spell-checkers analyze character patterns to highlight repetitive typing errors or incorrect word formation. In security-sensitive applications, ensuring unique characters in passwords can strengthen password policies and prevent weak credentials. Cryptography often relies on character frequency analysis to break ciphers or detect anomalies in encrypted messages. Another common use is in form validations where systems verify that certain fields, like coupon codes or unique identifiers, do not contain repeated characters, ensuring data integrity and preventing accidental duplication.
Problem Statement
You are given a string of characters, and you need to find out the duplicate characters in that string using Java.
Duplicate Characters in a string are those characters that occur more than once in the string. Let’s give an example to understand the above statement.
Sample Input:
sabcdaba.
Sample Output:
a
b
Explanation
In the above input string - sabcdaba, s occurs once, a occurs thrice, b occurs twice, c occurs once, and d occurs once. So a and b are the duplicate characters in the string.
We will use two loops to find out the duplicate characters.
The outer loop will be used to select each character of the string.
The inner loop will be used to count the frequency of the selected character and set the character as visited.
If the frequency of the selected character is greater than one, then print it.
Implementation:
Java
Java
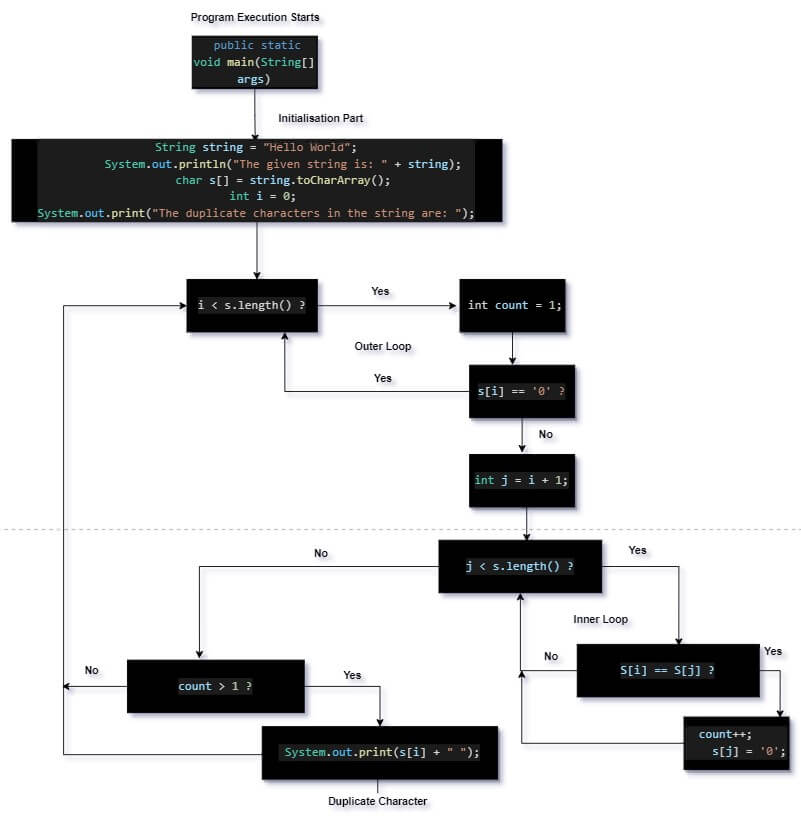
public class DuplicateCharacters { public static void main(String[] args) { // input string String string = "Hello World"; System. out.println("The string is: " + string);
// covert the string to the char array char s[] = string.toCharArray(); int i = 0; // Traverse the string from left to right System.out.print("The duplicate characters in the string are: "); for (i = 0; i < s.length; i++) { // For each character count the frequency int count = 1; // s[i] == '0' means we have already visited this character so no need to count its frequency again. if (s[i] == '0') continue; int j = i + 1; for (j = i + 1; j < s.length; j++) { // If a match found increase the count by 1 if (s[i] == s[j]) { count++; s[j] = '0'; } }
// If count is more than one then print it if (count > 1) { System.out.print(s[i] + " "); } } }
}
You can also try this code with Online Java Compiler
Let’s see the explanation of the code line by line.
A class named DuplicateCharaters is declared in this program, containing the main() method from which the program starts execution.
Inside the main function, a variable “string” of type String is declared.
Next, we print the variable “string” using System.out.println.
Next, the string is converted to a char array using the predefined method toCharArray(). Again we are using System.out.println to display the message “The duplicate characters in the string are:”.
Now the outer for loop is implemented, which will iterate from 0 to the length of the char array.
In each iteration, the variable named “count” is initialised to 1, and after that, we are doing if(s[i] == ‘0’) continue; this condition states that if the ith character of char array is visited, then no need to count its frequency again.
Then the inner for loop is implemented, which will iterate from i + 1 to the length of the char array. Inside the inner loop, the condition s[i] == s[j] is used to count the frequency of the ith character. After that, we set the jth character to ‘0’, i.e. s[j] = ‘0’.
Finally, if the condition(count > 1) is satisfied by the ith character, then the ith character is a duplicate character and displayed using System. Out.println.
Complexity Analysis
The complexity analysis of the above program is shown below:
Time Complexity:
In the worst possible case, when all characters are unique, the inner loop will traverse up to the end of the string for each character in the outer loop.
So, for n length string,
The total number of steps are = (n - 1) + (n - 2) + (n - 3) +......+3+2+1
= n*(n - 1) / 2
The time complexity of the above approach is: O(n²)
Space complexity:
As we are using a character array to store the characters of the string, so for n length string, we need to allocate n spaces. So the space complexity of the above approach is: O(n)
Program Flow Diagram:
The program flow diagram of the above code is shown below:
Method2(Hash map method)
The hashmap method is shown below:
Algorithm:
The steps are as follows:
Take the string as an input.
Create a hash map of type {Character, Integer}.
Traverse the string from left to right.
If the current character is already in the hash map, increment its frequency. Else insert the character in the hash map by setting the frequency to 1.
Finally, traverse through the hashmap and search for the characters with a frequency greater than 1.
Implementation:
Java
Java
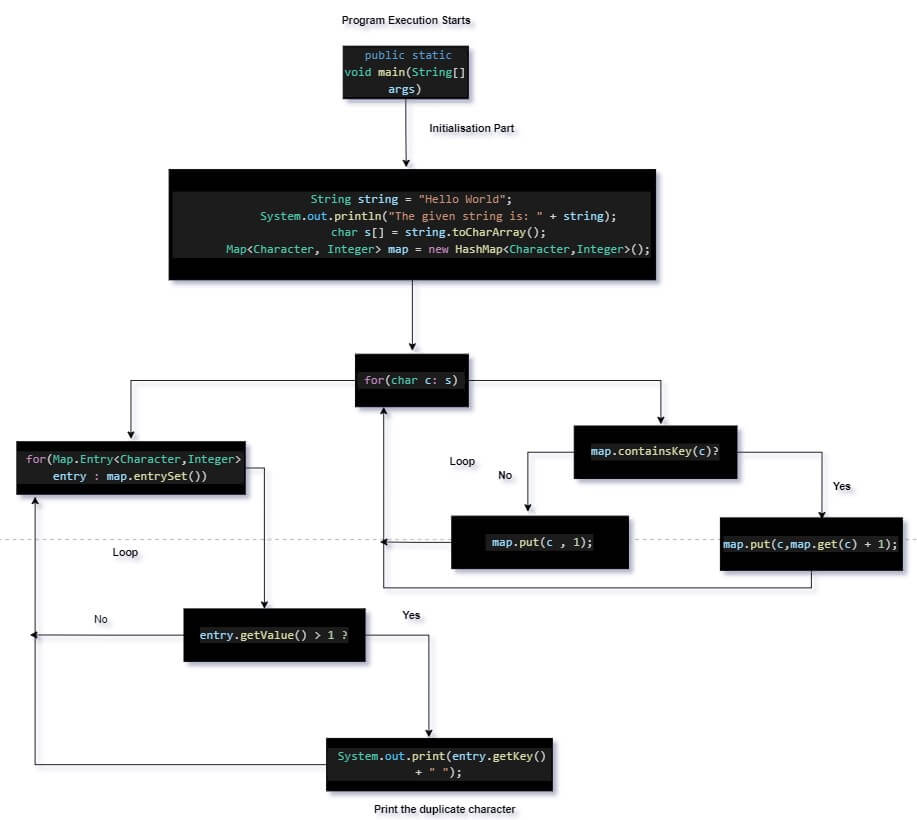
import Java.util.*; public class DuplicateCharacters { public static void main(String[] args) { String string = "Hello World"; System.out.println("The given string is: " + string); char s[] = string.toCharArray(); Map<Character, Integer> map = new HashMap<Character,Integer>(); for(char c: s) { if(map.containsKey(c)) { map.put(c,map.get(c) + 1); } else{ map.put(c , 1); } } System.out.print("The duplicate characters in the string are: "); for(Map.Entry<Character,Integer> entry : map.entrySet()) { if(entry.getValue() > 1) { System.out.print(entry.getKey() + " "); } } } }
You can also try this code with Online Java Compiler
The explanation of the above code is illustrated below:
A class named DuplicateCharaters is declared in this program, containing the main() method from which the program starts execution.
Inside the main function, a variable “string” of type String is declared.
Next, we print the variable “string” using System.out.println.
Next, the string is converted to a char array using the predefined method toCharArray().
Next, a hashmap of type {char,int} is defined using Map<Character, Integer> map = new HashMap<Character,Integer>()
Now a range-based for loop is implemented.
In each iteration of the loop, we check whether the current character is inside the hashmap by using the map.containsKey() method.
If the character is already on the map, we are just incrementing the frequency of the character using map.put(c,map.get(c) + 1).
The else condition is implemented on the following line where we put the current character inside the map with a frequency set to 1.
Again we are using System.out.println to display the message “The duplicate characters in the string are:”.
On the next line, another for loop is implemented where we are just checking the frequency of each character using the getValue() method. If the frequency of the character is more than one, then we are just printing the character.
Complexity Analysis
The time and space complexity analyses are shown below:
Time Complexity:
As we are scanning the character array only one time so, the Time complexity of the above code is = O(n)
Space Complexity:
Here, we store the characters in the hashmap, so the space complexity becomes O(n).
Program Flow Diagram:
The program flow diagram of the above code is shown below:
Approach to Find Duplicate Characters in a String in Java
Finding duplicate characters in a string in Java can be approached in several ways, depending on the requirements and constraints of your application. Below, we'll outline a common and efficient method using a HashMap to count occurrences of each character, and then identify the duplicates.
Steps:
Initialize Data Structures: Use a HashMap to store the frequency of each character in the string.
Iterate Over the String: Loop through each character in the string, updating the HashMap with the count of each character.
Identify Duplicates: Loop through the HashMap to find characters with a count greater than one, indicating duplicates.
Output the Results: Print or store the duplicate characters as needed.
Example:
Here is a sample Java program that demonstrates this approach:
import java.util.HashMap;
import java.util.Map;
public class FindDuplicates {
public static void main(String[] args) {
String input = "programming";
findDuplicates(input);
}
public static void findDuplicates(String str) {
// Create a HashMap to store character frequencies
HashMap<Character, Integer> charCountMap = new HashMap<>();
// Convert the string to a character array
char[] chars = str.toCharArray();
// Iterate over the character array
for (char c : chars) {
// Update the character count in the HashMap
charCountMap.put(c, charCountMap.getOrDefault(c, 0) + 1);
}
// Print characters with a count greater than 1
System.out.println("Duplicate characters in the given string:");
for (Map.Entry<Character, Integer> entry : charCountMap.entrySet()) {
if (entry.getValue() > 1) {
System.out.println(entry.getKey() + ": " + entry.getValue());
}
}
}
}
Explanation:
HashMap Initialization: The HashMap charCountMap is used to store each character and its frequency.
Character Array Conversion: The string is converted to a character array for easy iteration.
Frequency Counting: As the program iterates over each character, it updates the count in the HashMap using getOrDefault to handle characters not yet in the map.
Identifying Duplicates: The program then iterates over the entries in the HashMap and prints characters with a count greater than one, indicating duplicates.
Frequently Asked Question
What do you mean by the duplicate characters in a string?
The characters that occur more than once in a string are duplicate characters.
How do we find duplicate characters in a string?
To find the duplicate characters in a string, you need to count the occurrence of each unique character in the string. If the count is greater than 1, that character is a duplicate.
How do you find the duplicate characters in a string in Java without using collection?
You can use the hashmap in Java to find out the duplicate characters in a string - The steps are as follows, i) Create a hashmap where characters of the string are inserted as a key, and the frequencies of each character in the string are inserted as a value.| ii) If the hashmap already contains the key, then increase the frequency of the character by one otherwise, put the character in the hashmap. iii) Finally, check for characters with a frequency greater than 1.
Can a map contain duplicate keys?
No, the map does not allow duplicate keys, it allows duplicate values.
Conclusion
In this article, we have extensively discussed how to find out the duplicate characters in a string. Identifying and handling duplicate characters in a string is a common problem in programming, essential for various applications ranging from data validation to text processing. Throughout this blog, we explored different approaches to solving this problem.
In Java, we focused on leveraging a HashMap to efficiently count character frequencies and identify duplicates. This method is not only straightforward but also scalable for larger strings and diverse character sets.


































 9+ registered
9+ registered 

