Do you think IIT Guwahati certified course can help you in your career?
Introduction
Hey Ninjas!! Have you ever wondered how to restore a piece of data from a large data set? Partitioning in Hive can be used to do this. For example, you could partition a table of student marks according to the exam date to restore a student's data. Then, in this case, you can run a query instead of scanning the whole table.
We can use Dynamic Partitioning to restore or retrieve a specific subset of data from a large dataset. In this article, we will explore how Dynamic Partition in Hive works.
Hive
It is a data warehousing package that is built on top of Hadoop. It is primarily used in data analysis by data analysts. It runs SQL queries called HQL (Hive Query Language). The open-source data warehouse system helps analyze large data sets stored in many files. It is highly scalable.
A user submits a query to a Hive. The query gets analyzed by Hive and converts this SQL query into Map Reduce Jobs. A megastore is attached to the Hive and provides data about the data. The Hadoop clusters receive and process the jobs. This Hadoop cluster is a combination of Masterand worker nodes.The master node assigns tasks to the worker nodes, and upon job completion, the workers return the results to the system, which delivers the final result to the user. To explore more about Hive, check out the link.
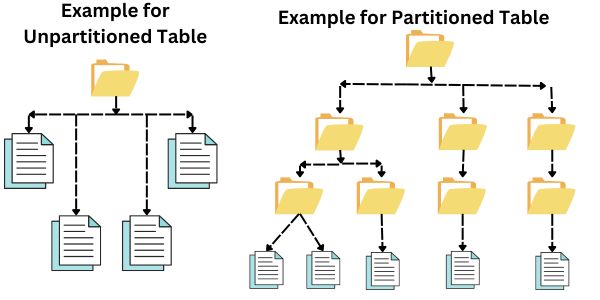
Hive Partitioning
Partitioning in Hive refers to dividing the table into small parts based on the values of a particular column, like name, date, course, city, etc. Partitioning allows effective data organization, and it improves query performance. Executing a query reduces the amount of scanned data.
Hadoop Distributed File System (HDFS) stores massive amounts of data in the petabyte range. It is challenging to achieve any query on this vast amount of data by Hadoop users. Hive narrows down the restraint for searching. We convert this SQL query into MapReduce Jobs and pass them to the Hadoop clusters. As a result, running MapReduce Jobs over such a vast table becomes very ineffective. There are two types of Hive Partitioning:
Static Partitioning
Dynamic Partitioning
This article will explore Dynamic Partitioning in Hive and discuss some related points.
It specifies each record's partition key and value while inserting data into the partitioned table. Static partitioning is commonly used when dealing with a small number of partitions. In static partitions, the individual files are loaded based on the partition. When partitioning data, we must ensure that specific data is placed accurately in the correct position. To use the Static partition, we should use the property as follows:
Mapred.mode = strict
We can use this in the hive-site.xml configuration file.
Dynamic Partitioning in Hive
Dynamic partition refers to a single insert to the partition table. There is no requirement to create the partition over the table explicitly. When using Dynamic Partitioning in Hive, multiple sub-directories are created. It provides more flexibility. It offers more flexibility.
Syntax
To enable the dynamic partition, we use this Hive Command
Set hive.exec.dynamic.partition = true
We will enable dynamic Partitioning for our application.
Set hive.exec.dynamic.partition.mode = nonstrict
We will set the mode to non-strict to demonstrate how to perform dynamic Partitioning.
Dynamic Partitions are also called variable Partitioning. Variable Partitionary means nodes that are not pre-configured, dynamically configured during runtime based on the file size or partition. It ensures proper distribution of memory and RAM. In the dynamic partition, every individual row of data is read and assigned with the Map-reduce job. Dynamic Partitioning by disable by default in the Hive prevents accidental partitioning.
First, we create a non-partitioned table that stores the data.
Code
Create table stud_report_card (
id int, Student_name string, marks int,
subject string
) ROW FORMAT delimited fields terminated by “,
” LINES TERMINATED BY ‘\n’ STORED AS TEXTFILE;
Output
Explanation
We initially created a non-partitioned table because the "LOAD" command cannot insert data into a partitioned table. Only the "INSERT" command inserts data into a partitioned table. When we run the "INSERT" command, the MapReduce process starts, and this method subsequently places the data in the proper partition of the table.
Step 2: Load table
Second, we have to load the table from a local system.
Code
Load data local inpath ‘/home/VIDHI/Hive/hive/details_student’ into the stud_report_card;
Output
Explanation
Data has been loaded into the system. We have used the ‘local’ keyword to load this data, which is present in the local system. If your data is in the HDFS, we can remove the keyword and execute our command.
NOTE: It's essential to set the property. If you do not use it, it will show you an error stating to enable the property. You can execute this code below to set the property before making a partitioned table.
Set hive.exec.dynamic.partition.mode = nonstrict;
Step 3: Create a Partitioned Table
Third, create a partitioned table where you want to insert the data with a dynamic partition.
Code
create table student_detail (
id int, Student_name string, marks int
) partitioned by (subject string);
Output
Explanation
We have created a partition table named ‘student_details.’ We have defined a partition column called ‘subject.’ The values of partitions are added dynamically based on the data inserted.
Step 4: Insert the Data
Fourth, insert the data as per your requirement with the partition.
Code
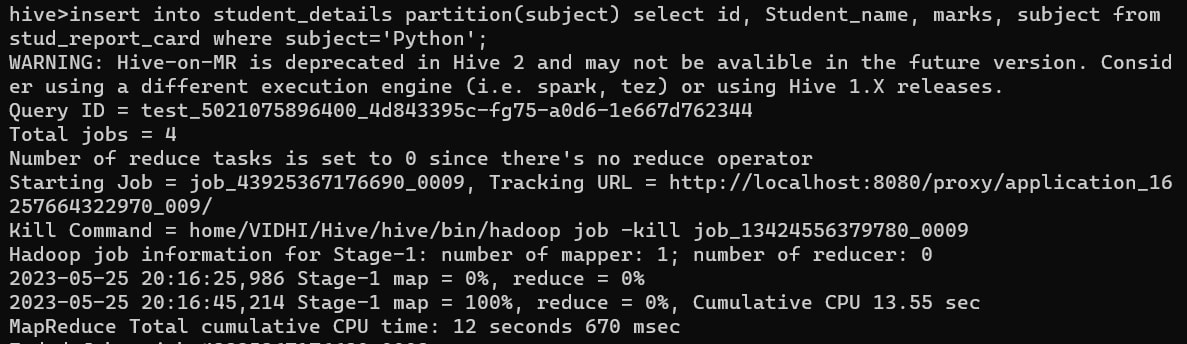
Insert into student_details partition(subject)
Select
id,
Student_name,
marks,
subject
from
stud_report_card
where
subject = ’Python’;
Output
Explanation
This command can insert data with a dynamic table partition over the column subject. We can insert data using the 'subject' column with a dynamic table partition.
Step 5: Display the table
Fifth, display the table after executing the query.
Code
Select
*
from
student_detail;
Output
Explanation
This query will return all rows from the table. The '* Select' keyword helps display all rows. We observe that response time also gets improves.
Advantages of Dynamic Partition
There are many advantages of Dynamic Partition in Hive:
Beneficial for loading large files into a table.
Data is read row-wise.
Partitions are created based on memory and RAM usage.
We observed a reduction in query processing time.
Load is distributed horizontally across the cluster.
Disadvantages of Dynamic Partition
There are some disadvantages of Dynamic Partition in Hive:
The possibility of creating many small partitions is present.
Loading data with dynamic partitioning takes more time compared to static partitioning.
It can not perform altered operations.
Difference between Static and Dynamic Partition in Hive
Static Partitioning
Dynamic Partitioning
We explicitly define partitions and their values during table creation or loading.
Partitions are created automatically based on the value encountered during data insertion.
Manual creation of partition directories.
Automatically created partition directories.
It is difficult to add new partition values.
More flexible as compared to Static Partition.
A deep understanding of all possible partition values is required
Advanced knowledge of partition values is optional.
Having fewer partitions and less metadata overhead
The high number of partitions and potential metadata overhead
How do you handle data skew when using dynamic Partitioning?
We can handle skew data by using bucketing with dynamic Partitioning to distribute the data evenly across the partitions. We can even perform techniques like data sampling to improve query performance.
Can dynamic Partitioning be used with different file formats in Hive (e.g., Parquet, ORC)?
We can perform dynamic Partitioning with different file formats like Parquet and ORC( Optimized Row Columnar). Hive dynamic Partitioning is independent of the file format used for storing the data.
Can dynamic Partitioning be combined with other features in Hive, such as bucketing or sorting?
We can combine dynamic Partitioning with bucketing and sorting. We can use a dynamic partition with bucketing to distribute the data evenly. Sorting can increase the efficiency of the data within the partitions.
How does dynamic partitioning work in Hive?
Dynamic Partitioning in Hive automatically determines and creates partitions based on the values encountered during data insertion. There is no need for explicit partition specification in dynamic Partitioning.
What are the advantages of using dynamic Partitioning over static Partitioning?
The advantages of dynamic Partitioning are that they provide more flexibility and scalability and simplify the data-loading process. It can automatically create directories. No advanced knowledge of Partitioning is required.
Conclusion
This article has explored various aspects of Hive and Dynamic Partitioning. We have defined its overview in this article. Dynamic Partitioning in Hive is a powerful tool that provides flexibility, scalability, and simply the process of data loading. We have explained the concept of dynamic Partitioning in-depth and its working. We demonstrated its working, highlighting its automatic partition creation based on data values.
Further, we examined the advantages and disadvantages of Dynamic Partition in Hive. Lastly, we compared static and dynamic Partitioning to understand their differences. This article provides a comprehensive overview of Hive partitioning and its dynamic variant.
You can find more informative articles or blogs on our platform. You can also practice more coding problems and prepare for interview questions from well-known companies on your platform, Coding Ninjas Studio.
Live masterclass
Prompt Engineering: Must-have GenAI Skill for 30L+ Roles at Amazon
by Anubhav Sinha
16 Jul, 2026
12:30 PM
Using Netflix Data to Master Power BI
by Ashwin Goyal
13 Jul, 2026
12:30 PM
Top GenAI Skills to crack 30L+ CTC at Amazon & Google
by Sumit Shukla
14 Jul, 2026
11:30 AM
JioHotstar Sports Analytics using IPL Dataset
by Prerita Agarwal
15 Jul, 2026
12:30 PM
Prompt Engineering: Must-have GenAI Skill for 30L+ Roles at Amazon


































 8+ registered
8+ registered 

