



























Introduction
Elasticsearch is an open-source, RESTful, scalable, document-based search engine based on the Apache Lucene library. It stores, retrieves, and manages textual, numerical, geospatial, structured, and unstructured data as JSON documents via the CRUD REST API or ingestion tools like Logstash.
If you are preparing for an ElasticSearch interview and want a quick guide before your interview, you have come to the right place.

This blog features the top 30 ElasticSearch Interview Questions. Now, without wasting time, let's get started with some crucial ElasticSearch interview questions.
ElasticSearch interview questions for Freshers
1. Explain Elasticsearch briefly.
Apache Lucene Elasticsearch engine is a database that stores, retrieves, and manages document-oriented and semi-structured data. It offers real-time search and analytics for structured and unstructured text and numerical and geographic data.
2. Provide step-by-step instructions for starting an Elasticsearch server.
The following steps describe the procedure:
- Click on the Windows Start button in the bottom-left corner of the desktop screen.
- To open a command prompt, type command or cmd into the Windows Start menu and press Enter.
- Change to the bin folder of the Elasticsearch folder that was created after it was installed.
- To start the Elasticsearch server, type /Elasticsearch.bat, and press Enter.
- This will launch Elasticsearch in the background from the command prompt. Open a browser and type http://localhost:9200 into the address bar. This should show the name of the Elasticsearch cluster and other meta values related to its database."
3. What is Elasticsearch Cluster?
It is a networked group of one or more node instances in charge of task distribution, searching, and indexing across all nodes.
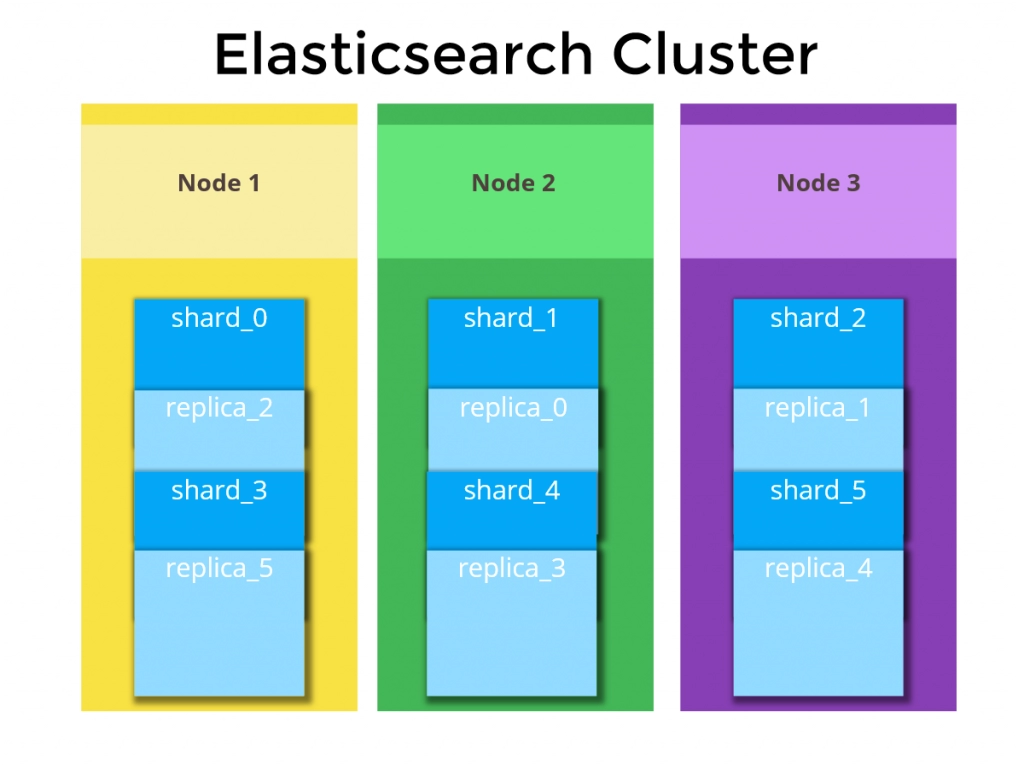
4. What is an Elasticsearch Node?
A node is an instance of Elasticsearch. Master nodes, Data nodes, Client nodes, and Ingest nodes are the various node types.
These are explained below:
- Data nodes store data and perform CRUD (Create/Read/Update/Delete), search, and aggregations.
- Master nodes assist in cluster configuration and management by adding and removing nodes.
- Client nodes send data-related requests to data nodes and cluster requests to the master node and Ingest nodes for document pre-processing before indexing.
5. In an Elasticsearch cluster, what is an index?
Unlike a relational database, an Elasticsearch cluster can contain multiple indices. These indices can be of various types (tables). The types (tables) include multiple Documents (records/rows), and these documents include Properties (columns).
6. Explain Mapping in Elasticsearch?
Mapping is the process of specifying how a document and the fields contained within it will be stored and indexed. Each document is made up of fields, each with its data type. When mapping data, you create a mapping definition, including a list of fields relevant to the document. Metadata fields, such as the _source field, are included in a mapping definition to customize how a document's associated metadata is handled.
7. What is a Document in the context of Elasticsearch?
A document is a JSON file that is stored in Elasticsearch. It corresponds to a row in a relational database table.
8. Could you explain SHARDS in terms of Elasticsearch?
As the number of documents grows, hard disc capacity and processing power become insufficient, and responding to client requests becomes more difficult. In this case, the process of dividing indexed data into small chunks is known as Shards, and it improves results retrieval during data search.
9. Define REPLICA, and what is the benefit of making a duplicate?
A replica is an exact copy of the Shard, which is used to boost query throughput or achieve high availability during peak loads. These replicas aid in the efficient management of requests.
10. Explain how to add or create an index in Elasticsearch Cluster.
To create a new index, use the create an indexed API option. The index configuration, index field mapping, and index aliases are required to create the index.
11. Explain the concepts of relevancy and scoring in Elasticsearch.
When you do an internet search, say, Apple. It could show the search results for fruit or a company named Apple. You might want to buy fruit online, look up a recipe from the fruit, or learn about the health benefits of eating fruit or apple. In contrast, you may want to visit Apple.com to learn about the company's latest product offerings, Apple Inc.'s stock prices, and how a company has performed on the NASDAQ in the last six months, one year, or five years.
Similarly, when we search Elasticsearch for a document (a record), you are interested in finding the relevant information. The Lucene scoring algorithm calculates the probability of receiving relevant information based on relevance. The Lucene technology aids in searching a specific record, i.e., a document, based on the frequency of the term appearing in the document, how frequently it appears across an index, and the query designed using various parameters.
12. What are the various methods for searching in Elasticsearch?
The following are the various methods for searching in Elasticsearch:
- Using a search API across multiple types and indices: We can search an entity across multiple types and indices using the Search API.
- Request for a search using a Uniform Resource Identifier: We can search for requests using parameters in conjunction with the URI or Uniform Resource Identifier.
- Query DSL (Domain Specific Language) search within the body: For the JSON request body, DSL, or Domain Specific Language, is used.
13. What are the different types of queries supported by Elasticsearch?
There are two types of queries: full text or match queries and term-based queries.
- The search term is not examined by the term query. Only the precise term we supply will be used in the term enquiry. This means that when searching text fields, the term query may produce poor or no results.
- To locate documents based on specific values in structured data, we can utilize term-based queries. Date ranges, IP addresses, prices, and product IDs are a few examples of organized data. Term-level queries don't look up search phrases like full-text queries do. Rather, term-level inquiries correspond to the precise phrases kept in a field.
14. Explain how aggregation works in Elasticsearch?
Aggregations aid in the collection of data from the search query. Metrics, averages, minimums, maximums, sums, and statistics are some examples of aggregations.
15. Can you compare term-based queries and full-text queries?
Domain-Specific Language (DSL) Elasticsearch queries, also known as Full-text queries, use the HTTP request body and have the advantage of being clear and detailed in their intent, making it easier to tune these queries over time.
Term-based queries use the inverted index, a hash map-like data structure that aids in the location of text or strings from the body of an email, keywords, numbers, dates, and so on


 8+ registered
8+ registered 

