Do you think IIT Guwahati certified course can help you in your career?
Introduction
In deep learning, embedding layers plays a vital role, especially when dealing with problems of NLP(Natural Language Processing). In the article below, I will explain what embedding layers are in Keras, how it works, and a few codes to get to know the implementation. First, to understand embedding layers in Keras, we need to understand Word Embedding.
What is word embedding?
While feeding data to a neural network, mapping all the words to some specific numbers is necessary, as neural networks cannot understand the language of ordinary humans.
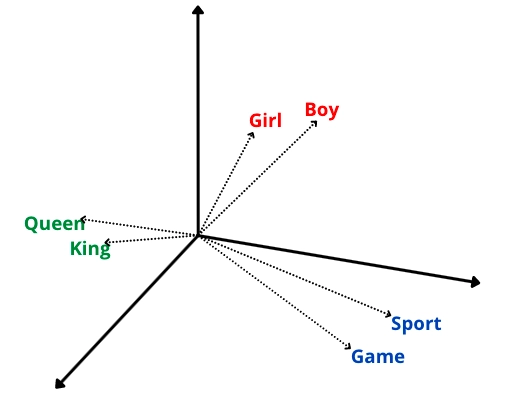
Word embedding is a technique to represent the word with the vector of numbers. In simple terms, word embedding means text as numbers. Suppose two vectors in the vector space are closer to each other, then the two words are expected to have a similar meaning.
The above image shows that the words “Girl” and “Boy” are related to each other, so they are placed close to each other in a vector space.
Why need word embedding?
Before the term embedding was unknown, people used the traditional bag of words method or one hot encoding method to map the words to numbers. To implement this method, a lot of memory was required as generated vectors were sparse and large, and each vector represents a single word. To overcome this problem, word embedding techniques came into existence.
What is the embedding layer in Keras?
Keras provides an embedding layer that converts each word into a fixed-length vector of defined size. The one-hot-encoding technique generates a large sparse matrix to represent a single word, whereas, in embedding layers, every word has a real-valued vector of fixed length. A minimum number of dimensions are required to express a word is the main advantage of this technique. Due to the reduction in dimensions, the representation of a word takes minimum space compared to one-hot-encoding.
The embedding layer requires integer encoded input data to represent each word uniquely. To prepare data, we can use TokenizerAPI provided by Keras.
The embedding layers are flexible because they are used in transfer learning to load a pre-trained word embedding model. Also, embedding layers can be part of the deep learning model where embedding is done along with the model itself.
The first hidden layer of the network is the embedding layer. It takes three arguments.
input_dim: It is the vocabulary size of the input data. Suppose your data is encoded using integers from 0 to 500, then the vocabulary size will be 501 words.
output_dim: It defines the length of the resulting vector for each word. The size of the vector may vary from 1 to any large integer.
input_length: input_length is the total number of words in the input sequence. If all the sentences in your dataset contain 50 words, the input_length for that embedding layer will be 50.
The output of the embedding layer is a 2D vector where every vector represents a single word from the vocabulary.
To understand the embedding layer, I will be taking an example where I will show the embedded representation of a word. Let us move towards the implementation part.
Implementation
I will be taking a few sentences for training purposes in the implementation part. Every sentence is remarked as ‘1’ or ‘0’, ‘1’ representing a positive statement, and ‘0’ as a negative statement.
Below are some sentences and their remarks.
#define sentences sentences = ["Programming is a good habit", "This is bad code you must improve it", "This is a perfect idea", "Your code was clean and neat", "You are excellent programmer", "You have performed badly in the examinations", "You could have made it better", "Good work! Keep it up.", "Poor performance", "Improve yourself"] #define remarks remarks = array([1,0,1,1,1,0,0,1,0,0])
To embed each word, we need to perform the following steps:
Import all the necessary libraries.
Convert all the sentences into words, i.e., tokenize all the sentences into words.
Define every sentence in the form of a one-hot-encoded vector.
Use pre-padding or post-padding to make the length of every one-hot-encoded vector the same.
Serve these padded vectors as input for embedded layers.
To predict the label, flatten it and apply a dense layer.
Importing libraries
Firstly, we will import all the libraries required to prepare the model.
from numpy import array from keras.preprocessing.text import one_hot from keras.preprocessing.sequence import pad_sequences from keras.models import Sequential from keras.layers import Dense from keras.layers import Flatten from keras.layers.embeddings import Embedding
In the above code snippet, we have imported numpy and keras. Array, one_hot, pad_sequences, Sequential, Dense, Flatten, Embedding are other functions imported from numpy and keras.
Tokenization and one_hot_encoding
Furthermore, we will tokenize all the sentences into words and define every sequence in the form of a one-hot-encoded vector
# integer encode the sentences vocabulary_size = 50 encoded_sequence = [ one_hot(s, vocabulary_size) for s in sentences ] print( encoded_sequence )
one_hot function will take a sentence and vocabulary_size as input.
The above code will convert all the sentences into integer encoded form using the one_hot function imported from keras.
After performing the one_hot function on the sentences, the above result is the output.
But we can see that all the one_hot_encoded vectors are not of equal length, so to overcome this problem, we pad every sentence using the pad_sequences function.
Padding
# pad documents to a max length of 10 words max_length = 10 padded_sequence = pad_sequences( encoded_sequence, maxlen = max_length, padding='pre' ) print( padded_sequence )
The above code will pad every sequence. Following is the output after applying the pad_sqeuences function on the one_hot_encoded vectors. We can see that every sequence has a length of ten numbers.
Number of zeros added to each vector = max_length - length of one_hot_encoded vector
Till now we have created proper input data that we can feed to the embedding layer.
Embedding layers
In the code below we are creating embedding layers.
# define the model model = Sequential() embedding_layer = Embedding( vocabulary_size, 10, input_length = max_length ) model.add( embedding_layer ) model.add( Flatten() ) model.add( Dense(1, activation='sigmoid') ) # compile the model model.compile( optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'] ) # summarize the model print( model.summary() )
We are creating a sequential model. In the embedding layer, vocabulary_size is input_dim parameter, output_dim is set to 10, and input_length of the sequence is the length of the padded sequence (max_length), i.e., 10. After flattening it apply a dense layer using the sigmoid activation function.
Compile the model using the adam optimizer and use the binary_crossentropy as a loss function.
Word embedding is the best way to deal with NLP problems. Rather than using the bag-of-words and the one_hot_encoding technique, use the word embedding technique as it saves a lot of space and reduces dimensions.
Key Takeaways
Things you have learned from this article:
Use of word embedding in NLP.
How to use embedding layers in keras.
Why word embedding is more efficient than one_hot_encoding and bag-of-words.
Isn't Machine Learning exciting!! We build different models using different algorithms and improve those algorithms to achieve higher accuracy. So are you excited to learn different machine learning algorithms, don't be confused; we have a perfect partner, the MACHINE LEARNING COURSE, to guide you in your learning process.





























 6+ registered
6+ registered 

