Working Of Encoder-Decoder Model
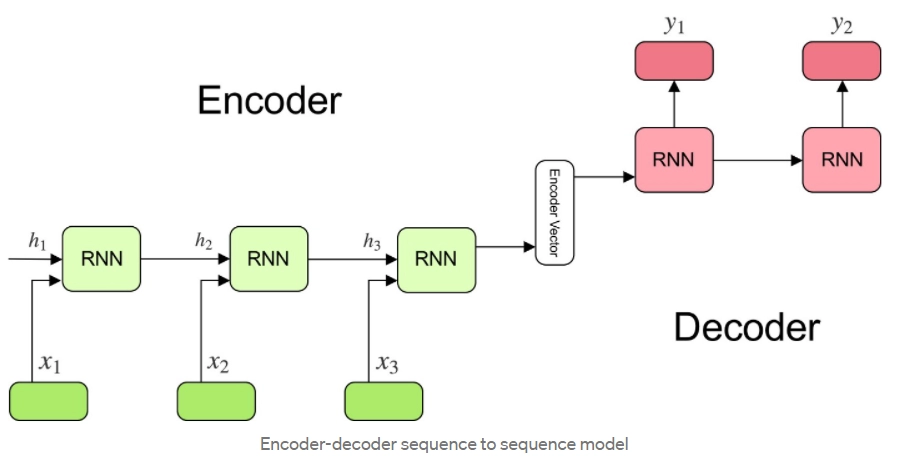
Encoder
The encoder is an LSTM/GRU cell. An encoder part is a stack of several recurrent units (LSTM or GRU cells for better performance). Each unit accepts a single element of the input sequence, collects information for that element, and propagates it forward. The outputs of the encoder are rejected, and only internal states are used.
Enoder cells take only one element as input at a time, so if the input sequence is length x, then the encoder takes x time steps to read the entire sentence.
- Xt is the input at each time step t.
- ht is internal states at time step t of the encoder cell.
- Yt is the final output of encoder cells at time step t.
Let us consider an example of English to Hindi translation. Consider the English sentence- "My name is Mayank Goyal." This sentence contains five words (My, name, is, Mayank, Goyal). Here,
X1 =' My.'
X2=’name'
X3= 'is'
X4=’Mayank'
X5=’Goyal'.
Therefore LSTM/GRU will read this sequence word by word in 5-time steps as follows-
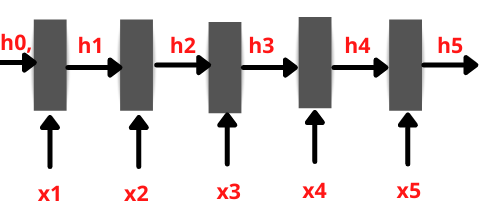
Each input(Xt) is represented as a vector using the word embedding, converting each word into a fixed-length vector. The hidden states h(i) is computed using the formula:
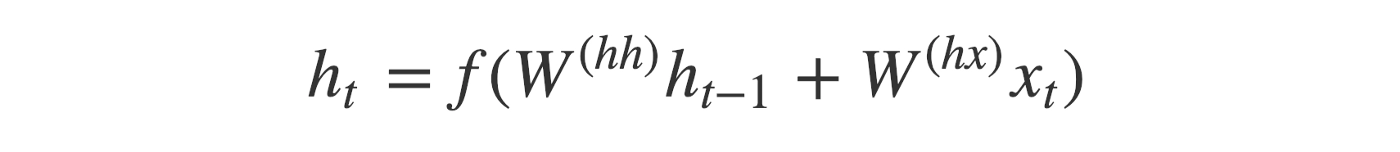
The final state, h5, contains the crux of the entire input sequence.
Intermediate Vector
It is the final hidden state produced from the encoder part of the model. It is calculated using the formula above. This vector encapsulates the information for all input elements to help the decoder cell units to make accurate predictions. It is the initial hidden state of the decoder part of the model.
Decoder Part
Let us understand the working of the decoder part during the training phase. Take the running example of translating My name Mayank Goyal to its Hindi conversion. The decoder also returns the output sequence word by word like an encoder. So we have to generate the output — मेरा नाम मयंक गोयल है| We will add START_ and _END at the stat and end of the sequence for the decoder to recognize the beginning and the ending of the sentence. So after applying changes, our output sentence will be START_मेरा नाम मयंक गोयल है_END.
Let us understand the working visually-

Where,
y1=मेरा
y2=नाम
y3=मयंक
y4= गोयल
y5= है
The initial states (ho) of the decoder are set to the final states of the encoder. We can think that the decoder is trained on the information collected by the encoder. Now, we input the START_ so that the decoder generates the next word. Moreover, after the last word in the Hindi sentence, we make the decoder learn to predict the _END. Decoder consists of a stack of several recurrent units where each unit predicts an output yt at each time step t. Each unit accepts a hidden state from the previous unit and produces an output and its hidden state. We compute the hidden state hi using the formula given below:
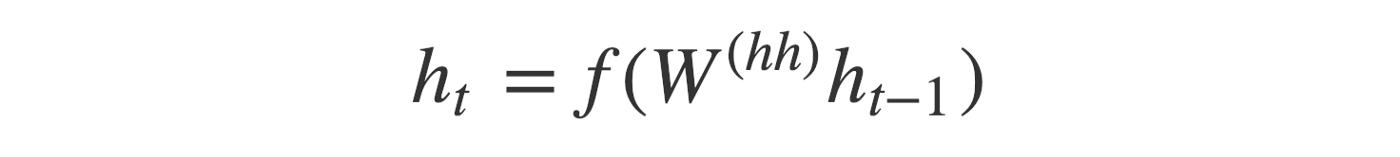
As we can see, we are using the previous hidden state to compute the next one. The output yt at each time step t is calculated using the formula given below:
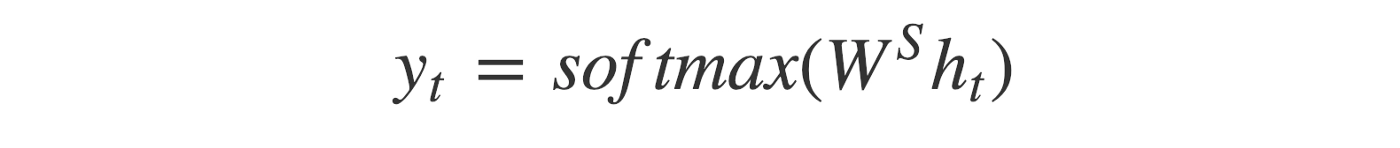
We calculate the output using the hidden state and the respective weight W(S) at the current time step. We use Softmax to create a probability vector that will help us determine the final output (e.g., the word in the question-answering problem). At last, we calculate the loss on the predicted outputs from each step, and the errors are backpropagated through time to update the model's parameters. The final states of the decoder are discarded as we get the output. Hence it is of no use.
That is how the encoder-decoder model works.
Applications
Google Translation
The Encoder-decoder model reads an input sentence, understands the message and the concepts, then translates it into a second language. Google Translate is built upon an encoder-decoder structure.
Sentimental Analysis
Encoder-decoder models understand the meaning of the input sentence and output a sentiment score. The sentiment score is usually rated between -1 (negative) and 1 (positive), where 0 is neutral. It is used in call centers to analyze the client's emotions and reactions to specific keywords or company discounts.
Video/Image Captioning
These models generate a sentence describing an image. The image is fed as the input and outputs a sequence of words. This also works with videos.
Frequently Asked Questions
1. What does the encoder/decoder model do?
Ans. Encoder decoder models allow for a process in which a machine learning model generates a sentence describing an image. It receives the image as the input and outputs a sequence of words. This also works with videos.
2. What is the difference between Autoencoder and encoder-decoder?
Ans. An encoder-decoder architecture has an encoder section that takes an input and maps it to a latent space. The decoder section takes that latent space and maps it to an output. Usually, this results in better results. An autoencoder takes x as input and reconstructs x as an output.
3. What are encoders and decoders in deep learning?
Ans. An Encoder-Decoder architecture was developed where an input sequence was read in entirety and encoded to a fixed-length internal representation. A decoder network then used this internal representation to output words until the end of the sequence token was reached.
Key Takeaways
Let us brief the article.
Firstly we saw what sequence to sequence model, and how encoder and decoder are used is. Moving on, we saw the architecture of the encoder-decider model and its working. Lastly, we saw some of the applications of the encoder-decoder model.
Recommended Reading: Instruction Format in Computer Architecture
The above explanation covers the most straightforward encoder-decoder model. So, we cannot expect it to perform well on complex tasks. The reason is that using a single vector for encoding the whole input sequence cannot capture the complete information.
That is the end of the article. I hope you all like it.
Happy Learning Ninjas!





























 8+ registered
8+ registered 

