



























Introduction
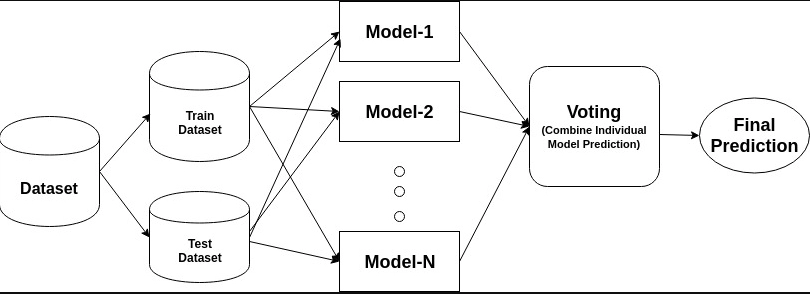
The ensemble is a Latin word derived from the union of parts. Ensemble classification is responsible for combining multiple models. This method trains various models with different datasets and gets the output. Ensemble techniques are of three types: bagging, boosting, and stacking. Ensemble classification is responsible for improving the machine learning outputs by combining weak learner models into one robust model. This allows better predictive outcomes compared to the results of a single model.
Source: Link
Types of Ensemble Classification
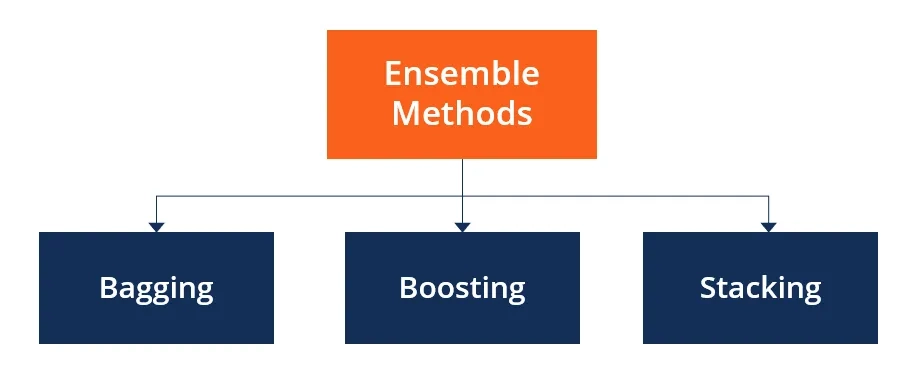
Ensemble classification is of three types:
- Bagging
- Boosting
- Stacking
Source: Link
Let us study them in detail:
Bagging
The first type of ensemble classification is bagging. Another name for bagging classification is bootstrap aggregation used for classification and regression problems. The original dataset is row-wise resampled and trained against multiple decision trees in bagging. Then the final prediction is based on the voting of all the models' predictions combined. Its main focus is to combine the outputs of various weak learners into a single strong learner model.
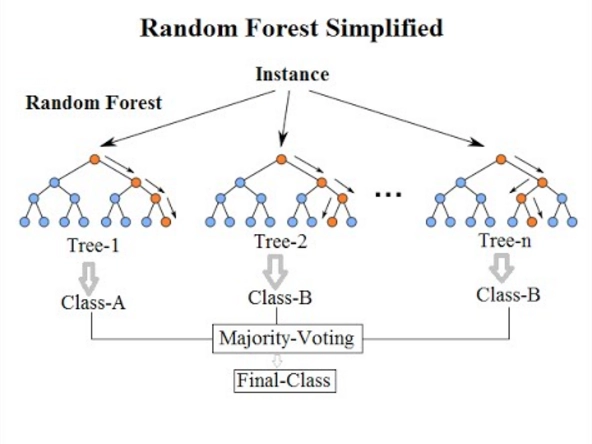
The most common application of Bagging classification is Random Forest.
Source: Link
In a random forest, the dataset is resampled and given to various decision trees to predict. The majority voting system generates the final output.
Boosting
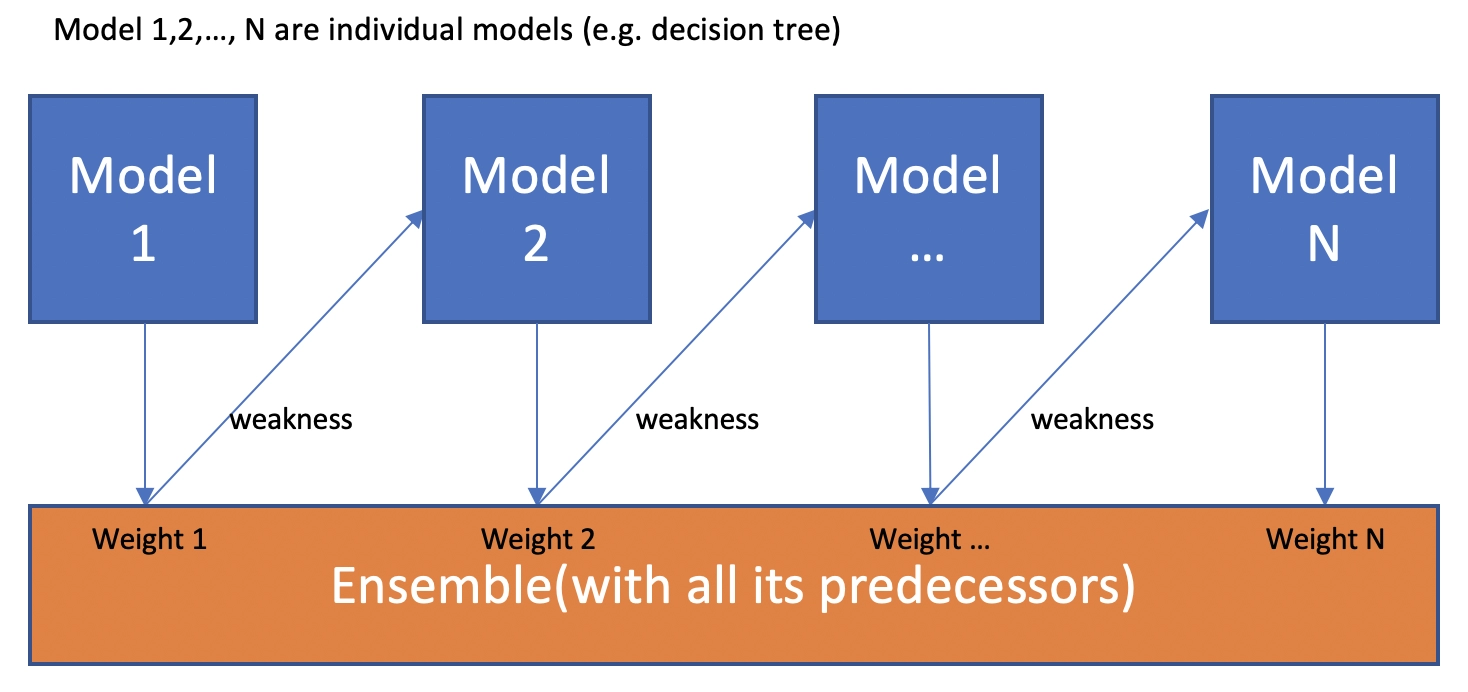
Boosting is another type of ensemble classification. It is a self-learning algorithm that learns by allocating weights for various features in the data. This technique initially begins with equal importance, but every model is assigned a weight based on the previous model's performance after every base model.
Source: Link
The most common use of this technique is in
- AdaBoost model
- XGboost model
- LightGBM model
- Gradient boosting model
How is boosting different from bagging?
Bagging classifier helps reduce the prediction variance by creating resampled data for training various decision trees. On the other hand, boosting is a sequential technique that adjusts the weight of current observation based on the previous classification.
Stacking
The next type of ensemble classification is stacking. This is a method in which a single training dataset is trained on multiple models. The training dataset is divided using the k-fold algorithm, and the final model is built. In stacking, each model indicates a different learning algorithm. The predictions made by these models are known as the first level predictions, i.e., the base model predictions, and these predictions are further used for the second level training, i.e., the meta-model training.
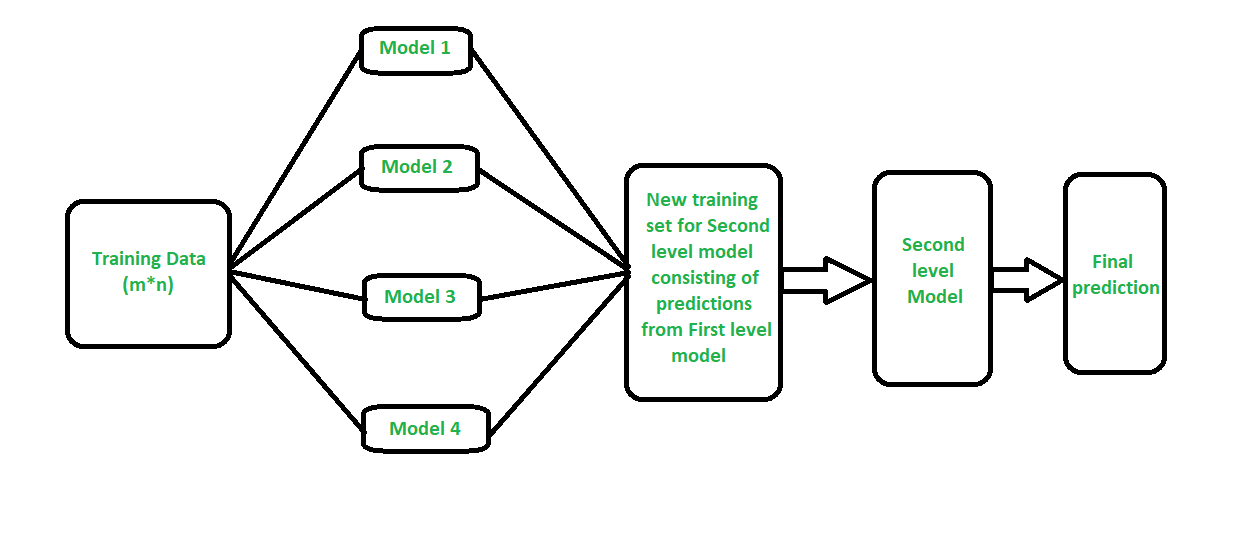
Source: Link
How is stacking different from bagging and boosting?
The main classification between the three categories is that bagging and boosting techniques are homogeneous, i.e., the models used for classification are the same, e.g., decision trees. While in stacking, the models used for classification can be different, like SVM, Logistic Regression, etc.


 9+ registered
9+ registered 

