Do you think IIT Guwahati certified course can help you in your career?
Introduction
Ensemble learning techniques assist in making the performance of a predictive model better by improving its accuracy. Ensemble learning is a process by which multiple machine learning models combine to solve a particular problem. This problem can be of a classification or regression type. Ensemble learning models have three essential components.
First, we have data sets. The data is jumbled and sent to the machine learning model. The mixing of information is called sampling, and we can either perform row sampling or column sampling.
Next, we have a group of base learners. Base learners are machine learning models that can either be independent or dependent on each other. Every base model gives its prediction according to the data fed to it.
The output of the prediction of all these models combines into a final model. The decision is based on the majority vote or their prediction weights.
Need of an Ensemble learning
Ensemble learning is helping to improve machine learning results by combining several models. This approach allows a prediction of better predictive performance compared to a single model. This is why Ensemble methods placed first in many prestigious machine learning competitions such as Netflix competition, KDD 2009, and Kaggle.
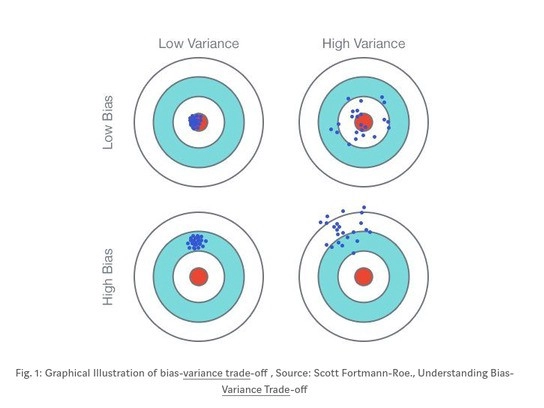
One of the most common turns used in Ensemble learning is bias and variance.
Bias error is helpful to quantify how much the predicted value is different from the actual value on an average. The high bias error means an underperforming model is missing significant trends.
Then we have variance on the other side to quantify how much of the predictions made on the same observation are different. A high variance model will overfit our training population and perform poorly on any training data set.
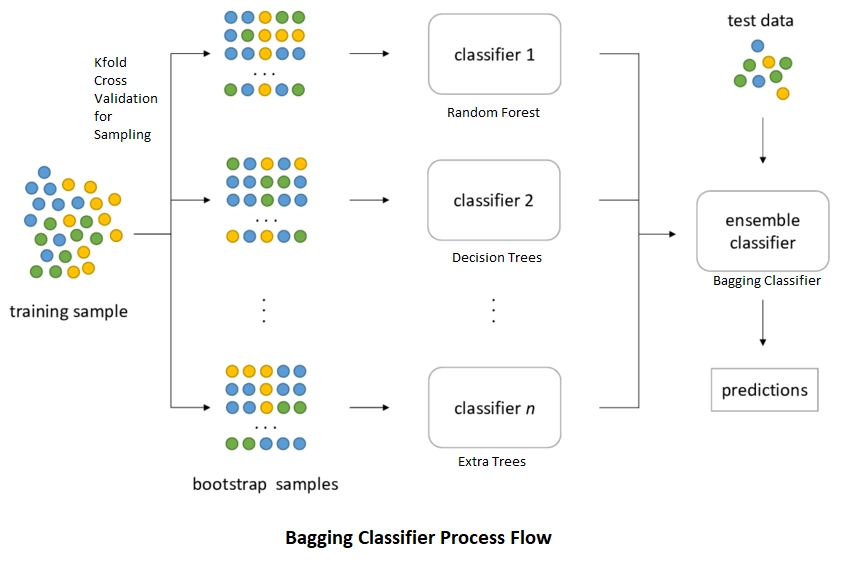
Bagging is an Ensemble learning technique, which is also known as bootstrap aggregation. Bootstrap establishes the foundation of the bagging technique. Bootstrap is a technique in which we select an observation out of the population of n-observations, but the selection is entirely random. The bootstrap process determines each compliance with equal probability. After forming the bootstrap sample, separate models train with the Bootstrap samples. In actual experiments, the bootstrap samples are drawn from the training data set, and the sub-models are tested using the testing datasets. The final output predictions combine the projection of all sub-models.
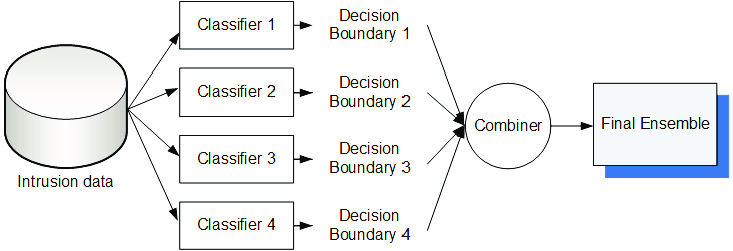
Voting is an Ensemble learning technique in which predictions from multiple models combine. The model starts with creating two or more separate models with the same data set. Then a voting-based ensemble model can be used to wrap the previous model and aggregate the prediction of those particular models. After a voting-based ensemble model is constructed, it can make predictions on new data. The projections made by the sub-models can be assigned weights. Stack aggregation is a technique that helps study these predictions in the best way possible.
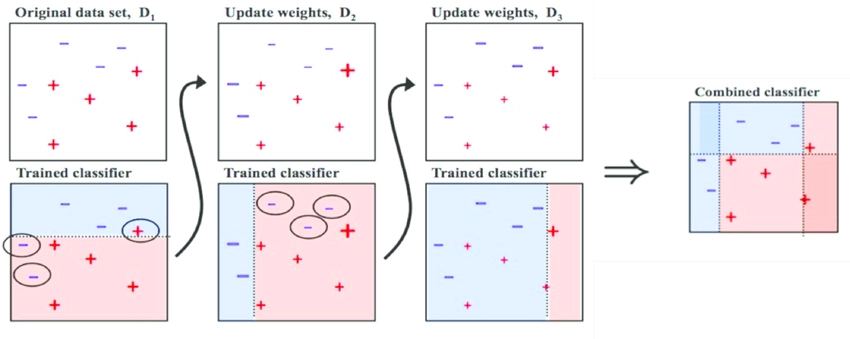
Boosting is a sequential learning technique. The Boosting algorithm works by training a model with its entire training set. Subsequent models are considered by fitting the residual values or errors into an initial model. In this way, boosting attempts to give high weightage to those observations that previous models poorly estimate. When the sequence of these models is created, an accuracy score comes in the picture to predict these models. The results are combined to create a final estimation. Models based on boosting can be extreme gradient boost, gradient boosting, AdaBoost, and many more.
Implementation
I will see the implementation of the Bagging ensemble method. I am using the iris dataset from SK learn dataset library.
# importing essential modules
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier, plot_tree
from sklearn.metrics import accuracy_score
from mlxtend.plotting import plot_decision_regions
import pandas as pd
import numpy as np
data = load_iris()
# creating the data frame
d = {
'sepal length (cm)' : data.data[50:, 1],
'petal length (cm)' : data.data[50:, 2],
'Species' : np.array([i for i in data.target if i> 0])
}
df = pd.DataFrame(d)
df = df.sample(df.shape[0])
#separating ot train and test data
df_train = df.iloc[:60,:].sample(10)
df_test = df.iloc[61:,:].sample(10)
df_tt = df_test.sample(5, replace= True)
X_test = df_tt.iloc[:,:-1].values
y_test = df_tt.iloc[:,-1].values
print(X_test,y_test)
#model ->random samples
def evaluate(model, x ,y):
model.fit(x,y)
plot_tree(model)
plt.show()
plot_decision_regions(x,y,model,legend = 2)
plt.show()
#checking the accuracy
y_pred = model.predict(X_test)
print('y_test :', y_test)
print('y_pred :', y_pred)
print('accuracy score', accuracy_score(y_test,y_pred)*100)
return model
# Building first Decision Tree
df_t = df_train.sample(8, replace=True)
X_train = df_t.iloc[:,:-1].values
y_train = df_t.iloc[:,-1].values
dt = DecisionTreeClassifier()
bag1 = evaluate(dt, X_train, y_train)
#Second Decision tree
df_t = df_train.sample(8, replace=True)
X_train = df_t.iloc[:,:-1].values
y_train = df_t.iloc[:,-1].values
dt = DecisionTreeClassifier()
bag2 = evaluate(dt, X_train, y_train)
# Third Decision Tree
df_t = df_train.sample(8, replace=True)
X_train = df_t.iloc[:,:-1].values
y_train = df_t.iloc[:,-1].values
dt = DecisionTreeClassifier()
bag3 = evaluate(dt, X_train, y_train)
#After building the three models that randomly selects eight values from the dataset,
#Lets perform Aggregation and see the result predicted by the base models upon same data
print('prediction 1', bag1.predict(np.array([2.5,4.9]).reshape(1,2)))
print('prediction 1', bag2.predict(np.array([2.5,4.9]).reshape(1,2)))
print('prediction 1', bag3.predict(np.array([2.5,4.9]).reshape(1,2)))
You can also try this code with Online Python Compiler
prediction 1 [2]
prediction 1 [2]
prediction 1 [2]
# All the models are predicting 2, so the final output is 1.
# As the dataset here is small, so we are getting the accurate value
# If the dataset had been large, we will definitely get inconsistencies
What is Ensemble learning? Ensemble learning is a process by which multiple machine learning models combine to solve a particular problem.
Why do we need Ensemble learning? Ensemble learning is helping to improve machine learning results by combining several models. This approach allows a prediction of better predictive performance compared to a single model.
What is a bias error? Bias error helps to know how much the predicted value is different from the actual value.
What is a variance? variance quantifies how much of the predictions made on the same observation are different from each other.
What is the Bootstrap technique? Bootstrap is a technique in which we select an observation out of the population of n-observations, but the selection is entirely random.
Key Takeaways
Besides Boosting, there are two more Ensemble learning methods which you can find here in much detail.
Interested in learning machine learning must visit the link.






























 9+ registered
9+ registered 

