Do you think IIT Guwahati certified course can help you in your career?
Introduction
As we all know, machine learning is becoming an area of interest for many people. It is becoming popular daily, so it becomes important to have good knowledge of machine learning algorithms. Therefore, this blog will discuss ensemble learning, which is a part of machine learning.
In this article, we will cover the topic of the ensemble method in machine learning. We will also discuss bagging and boosting methods, and in the end, we will discuss the implementation of Random forest, Adaboost, and Voting classifier and Regression using scikit-learn.
What are ensemble methods?
The ensemble method or ensemble learning is a model which makes predictions based on the different numbers of models. The goal of ensemble learning is to combine the predictions made by several estimators built using a particular algorithm so that it can produce better and more effective results.
There are two methods of ensemble learning:
Bagging Ensemble Algorithm
Boosting Ensemble Algorithm
Now let us first have a look at the Bagging method then after that, we will learn about the Boosting method.
Bagging ensemble algorithm
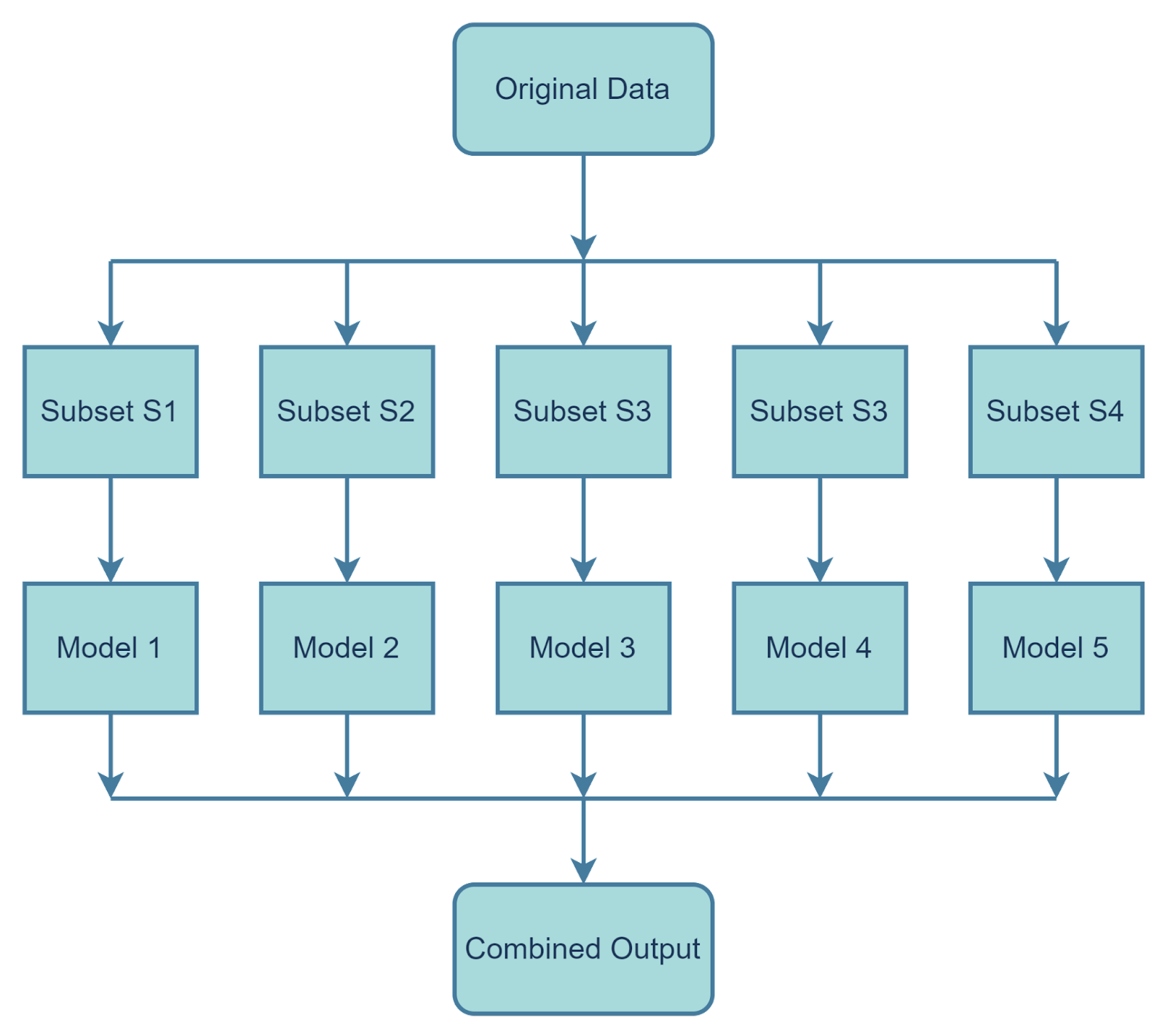
Bagging is a method or algorithm that is also known as Bootstrap aggregation. An ensemble learning method looks for different ensemble learners by varying the dataset.
We all know that sometimes a single model is trained on a single dataset. Unlike this bagging creates multiple weak learners or base models trained on a subset of the original dataset.
The number of models which are used and the size of the subsets are all decided by the data scientist.
How does bagging works?
The following are the steps involved in the Bagging algorithm:
First, create multiple subsets from the training dataset by selecting observations.
Create a base model which can also be called a weak model.
Run all the base models simultaneously and independently from each other.
In the end, combine all the predictions from base models to determine the final outcome.
Boosting Ensemble Algorithm
Boosting is an ensemble algorithm that changes the training data and adjusts the weight of the observations based on previous classifications. Unlike the bagging algorithm boosting is dependent on weak learners. The weak learners take the data of previous weak learners into account and adjust the data points, which converts a weak learner into a strong learner.
How does boosting work?
The following are the steps involved in the boosting algorithm:
We will first create a subset from the training dataset where all the data points are given equal weights.
Now a base model will be created for the initial dataset and this model will be used for predictions.
Errors will be calculated using predicted and actual values. The observations which were predicted incorrectly would be given a higher weight.
After this boosting will try to correct the errors of the previous models.
This process will be repeated many times so that errors are minimized.
In the end, a final model would be obtained which would be a strong learner and it would be the weighted mean of the weak learners.
Random forests implementation using scikit-learn
Random forest is an ensemble model which uses bagging as the ensemble method and a decision tree as an individual model. In bagging a number of decision trees are created and each tree is created using a different bootstrap sample of a training dataset. Predictions obtained from the trees are averaged across all the decision trees which results in better performance.
Random forests can be implemented from scratch and since this could prove to be challenging therefore the scikit-learn machine learning library provides an implementation of the random forests. Random forests are provided using the Random forest Regressor and Random Forest Classifier classes.
Now we will see a coded example of a Random forest for the Classification
# test classification dataset
from sklearn.datasets import make_classification
# defining dataset for classification by specifying parameters
num1, num2 = make_classification(n_samples=2000, n_features=20, n_informative=16, n_redundant=3, random_state=8)
# dimension of the dataset
print(num1.shape, num2.shape)
You can also try this code with Online Python Compiler
# evaluate random forest algorithm for classification
import numpy as np
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import RepeatedStratifiedKFold
from sklearn.model_selection import cross_val_score
from sklearn.datasets import make_classification
# defining dataset for classification by specifying parameters
num1, num2 = make_classification(n_samples=2000, n_features=20, n_informative=16, n_redundant=3, random_state=8)
# defining the model for RandomForest Classification
model = RandomForestClassifier()
# evaluating the model
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
n_scores = cross_val_score(model, num1, num2, scoring='accuracy', cv=cv, n_jobs=-1, error_score='raise')
# the final accuracy of the model
print('Accuracy: %.3f (%.3f)' % (np.mean(n_scores), np.std(n_scores)))
You can also try this code with Online Python Compiler
As we all know that boosting is a class of machine learning which involves combining the predictions of many weak learners. A weak learner is a model which is very simple in nature and has very little skill on a dataset.
AdaBoost which is short for “Adaptive Boosting” is a boosting ensemble machine learning algorithm that was one of the first successful boosting approaches.
The AdaBoost algorithm involves using very short decision trees that are weak learners and they are added sequentially to the ensemble. Each subsequent model attempts to correct the predictions made by the previous model.
Now we will see a coded example of AdaBoost for Classification.
# test classification dataset
from sklearn.datasets import make_classification
# defining dataset for classification by specifying parameters
num1, num2 = make_classification(n_samples=2000, n_features=20, n_informative=16, n_redundant=3, random_state=8)
# dimension of the dataset
print(num1.shape, num2.shape)
You can also try this code with Online Python Compiler
# importing libraries for classification of adaboost algorithm
import numpy as np
from sklearn.ensemble import AdaBoostClassifier
from sklearn.datasets import make_classification
from sklearn.model_selection import RepeatedStratifiedKFold
from sklearn.model_selection import cross_val_score
# defining dataset for classification by specifying parameters
num1, num2 = make_classification(n_samples=2000, n_features=20, n_informative=16, n_redundant=3, random_state=8)
# defining the model for AdaBoost classification
mdl = AdaBoostClassifier()
# evaluating the model
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
no_of_scores = cross_val_score(mdl, num1, num2, scoring='accuracy', cv=cv, n_jobs=-1, error_score='raise')
# the final accuracy of the model
print('Accuracy: %.3f (%.3f)' % (np.mean(no_of_scores), np.std(no_of_scores)))
You can also try this code with Online Python Compiler
Implementation of Voting classifier and regressor using scikit-learn
A voting ensemble is an ensemble machine learning model which combines the predictions of different models into a single model. It is a technique used to improve the performance of the model, ideally, it helps in achieving better performance than any other ensemble model.
A voting ensemble works by combining the predictions of different models. It can be used for both classification and regression. In the case of classification, predictions for each of the labels are summed and the label with the majority vote is predicted. In the case of regression, the average of all the predictions is calculated.
Classification Voting Ensemble: Predictions are calculated by finding the majority vote of the contributing models.
Regression Voting Ensemble: Predictions are calculated by finding the average of the contributing models.
Now we will see a coded example Voting Classifier
# compare hard voting to standalone classifiers
import numpy as np
from sklearn.datasets import make_classification
from sklearn.model_selection import cross_val_score
from sklearn.ensemble import VotingClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import RepeatedStratifiedKFold
from matplotlib import pyplot
# defining the dataset
def get_dataset():
num1, num2 = make_classification(n_samples=2000, n_features=20, n_informative=16, n_redundant=3, random_state=8)
return num1, num2
# get a voting ensemble of all the models
def get_voting():
# defining the base models
models = list()
models.append(('knn_5', KNeighborsClassifier(n_neighbors=5)))
models.append(('knn_7', KNeighborsClassifier(n_neighbors=7)))
models.append(('knn_9', KNeighborsClassifier(n_neighbors=9)))
# defining the voting ensemble
ensemble = VotingClassifier(estimators=models, voting='hard')
return ensemble
# getting a list of models
def get_models():
models = dict()
models['knn_5'] = KNeighborsClassifier(n_neighbors=5)
models['knn_7'] = KNeighborsClassifier(n_neighbors=7)
models['knn_9'] = KNeighborsClassifier(n_neighbors=9)
return models
# evaluating the given model using cross-validation
def evaluate_model(model, num1, num2):
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=4, random_state=3)
scores = cross_val_score(model, num1, num2, scoring='accuracy', cv=cv, n_jobs=-1, error_score='raise')
return scores
# define dataset
num1, num2 = get_dataset()
models = get_models()
# evaluate the models and store results
results, names = list(), list()
for name, model in models.items():
scores = evaluate_model(model, num1, num2)
results.append(scores)
names.append(name)
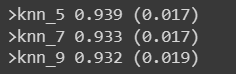
print('>%s %.3f (%.3f)' % (name, np.mean(scores), np.std(scores)))
You can also try this code with Online Python Compiler
Random forest is a type of ensemble learning method which is majorly used for classification and regression.
List some applications of ensemble learning.
Person recognition, includes iris recognition, face recognition, fingerprint recognition, and behavior recognition.
Medical applications like x-rays, human genome analysis, and examining sets of medical data to look for anomalies.
What are weak learners?
In ensemble learning, weak learners are the models that can be used as the fundamental blocks for designing more complex models by combining two or more of them.
What are ensemble methods?
This machine learning technique combines several models to produce one effective and optimal model. Random forest is also a type of ensemble method.
Conclusion
We have discussed the Ensemble method using scikit-learn. We started with the introduction to ensemble methods and then we learned about bagging and boosting after that we discussed coded examples of Random forests, AdaBoost and Voting classifiers.































 9+ registered
9+ registered 

