Do you think IIT Guwahati certified course can help you in your career?
Introduction
Let us say your friend group really enjoys going to the pizza parlor regularly. But one day, one of your friends said to visit the Chinese restaurant that opened a week back. The whole group is in a dilemma, whether you guys should continue to see the pizza parlor you already know is fantastic or try a new restaurant that could be worse or better than the pizza parlor.
Now, this is the point where you have to make a decision.
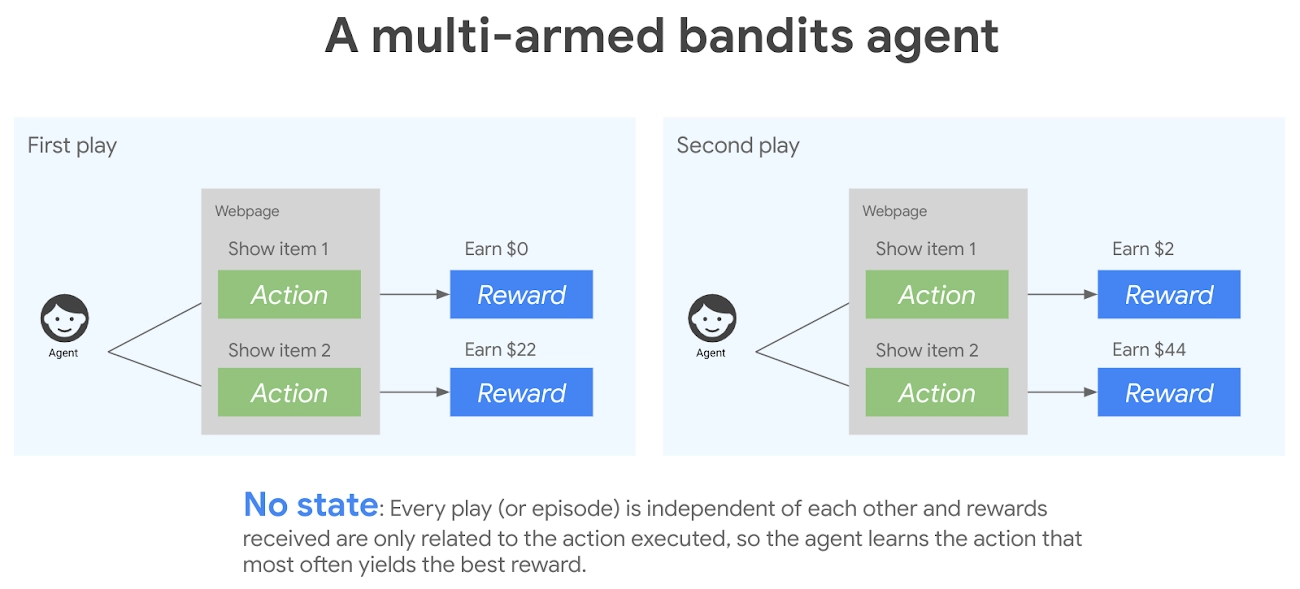
Similarly, computers also learn to make decisions by making mistakes, trying new things, and sometimes taking the same conclusion they took last. This kind of learning is known as Reinforcement learning, a branch of Artificial Intelligence. According to Reinforcement learning, the dilemma to eat at a pizza parlor or the new Chinese restaurant is known as the exploration-exploitation tradeoff. This kind of problem is called the multi-armed bandit problem.
Exploration-Exploitation in Epsilon Greedy Algorithm
Exploitation is when the agent knows all his options and chooses the best option based on the previous success rates. Whereas exploration is the concept where the agent is unaware of his opportunities and tries to explore other options to better predict and earn rewards. As in the example above, going to the same pizza parlor and ordering the best pizza is an example of exploitation; here, the user knows all his options and selects the best option. On the other hand, going to the new Chinese restaurant and trying new things would come under exploration. The user is exploring new things; it could be better or worse, the user is unaware of the result.
The epsilon greedy algorithm chooses between exploration and exploitation by estimating the highest rewards. It determines the optimal action. It takes advantage of previous knowledge to choose exploitation, looks for new options, and select exploration.
The policy improvement is a theorem that states For any epsilon greedy policy π, the epsilon greedy policy π' concerning qπ is an improvement. Therefore, the reward for π' will be more. The inequality is because the max function returns a more excellent value than the arbitrary weighted sum.
A sample code for implementation of epsilon greedy algorithm for choosing the restaurant is as follows:
#Creating class
class Restaurant:
#Defining the various choices
Pizza_parlor=[0,1,2,3]
Chinese_rest= [0,0,0,0]
#Creating function for Exploration
def exploration():
return random.choice(Pizza_parlor)
#Creating function for Exploitation
def exploitation():
return Chinese_rest.index(max(Chinese_rest))
def Choose_restaurant():
if random.random()>epsilon:
print(exploitation())
else:
print(exploration())
You can also try this code with Online Python Compiler
A classic problem named a multi-armed bandit problem is an example of a greedy epsilon algorithm. In this problem n arms or bandits are provided to the machine with the probability rate of success. Each arm is pulled out one by one, and based on the success rate, the reward is given. If a success, the reward is incremented by 1; otherwise, the reward is 0. Our objective is to pull out the arms sequentially to have the maximum reward at the end.
Bandit 1
Bandit 2
Bandit 3
Bandit 4
Bandit 5
Success rate: 25%
Success rate: 67%
Success rate: 79%
Success rate: 12%
Success rate: 55%
The Epsilon greedy algorithm does not just work on the pre-known notion; it explores various other ways with the method of tries and errors to get rewards. We will set the epsilon exploration probability as 10%, and run it for 100 cycles for this case. At the beginning of the algorithm, the agent will be at the exploration stage during the first few cycles, i.e., it will explore all possible arms to get the reward.
Later, as the name suggests, our agent is greedy; therefore, its first preference would be picking the Bandit 3 as it has the maximum success rate. Following this, the second preference would be Bandit 2; now, the agent knows all its bandit's success rates and would select those with high success rates to get the maximum reward.
Advantages and Disadvantages of Epsilon Greedy Algorithm
Advantages of Epsilon Greedy Algorithm
The significant advantage of the epsilon greedy algorithm is that it gets the opportunity to learn from past experiences, like other decision-making models, and explore new outcomes. It can explore new situations and have diverse knowledge, which helps in improved decision-making.
Disadvantages of Epsilon Greedy Algorithm
Epsilon greedy algorithm could sometimes explore new parameters and decide which user is not satisfied.
Ans. It represents an arbitrarily small positive number in regression.
Q2. What is Epsilon in Reinforcement Learning?
Ans. Whenever we select actions based on our already known values, it is known as Epsilon.
Q3. Why does Epsilon decay in reinforcement learning?
Ans. A decay in epsilon value gives the user an optimal action and the desired output.
Key Takeaways
The Epsilon greedy algorithm is all about exploring new parameters and exploiting the already known facts to make a better decision. This article included the fundamental understating of the Epsilon greedy algorithm, its pseudocode, along with an example of practical implementation. Its applications, advantages, and disadvantages. To get an in-depth understanding of Reinforcement Learning, check out this article.




































 18+ registered
18+ registered 

