


























Introduction
The concept of clustering became trendy in the time of Machine Learning development. This concept, clustering, deal with many real-world problems like “Finding Similar kinds of people on Twitter”, “Tag Suggestions,” “Search Engines,” “Customer Segmentation,” etc. The expectation-Maximization Algorithm, popularly known as the EM algorithm, is a Model-based clustering algorithm that tries to optimize the fit between the given data and some mathematical model.

These methods, Model-based clustering methods, basically made an assumption that the data are generated by a mixture of an underlying probability distribution. The EM algorithm is just an extension of the popular k-means partitioning algorithm.
Why EM algorithm(Model-Based Algorithm)?
According to the math, we know that the data is a mixture of probabilistic distributions, where a parametric probability distribution represents each cluster. Here each individual distribution is typically referred to as “component distribution.” The main problem of introducing model-based algorithms or methods is to solve the problem of estimating the probability distributions' parameters to fit the data best.
Example:
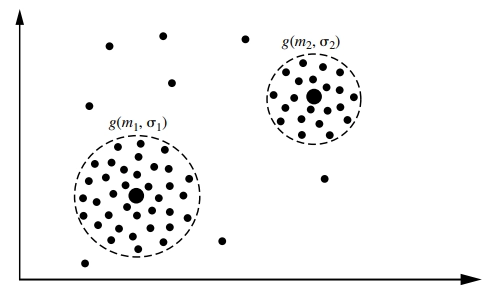
A simple finite mixture density model. The two clusters follow a Gaussian distribution with their own mean and standard deviation.
Reference: Data Mining Concepts and Techniques Second Edition Jiawei Han
The EM Algorithm
The EM Algorithm, Expectation-Maximization Algorithm, is a popular iterative refinement algorithm used for finding the parameter estimates. It is simple and easy to implement. In general, it converges fast and may not lead to generating the global optimal. We said that this algorithm is an extension of k-means. This is because in this EM algorithm, instead of assigning each object to a dedicated cluster, EM gives each object to a cluster according to a weight representing the probability of membership. In other words, there are no strict boundaries between clusters. Therefore, new means are computed based on weighted measures.
The main idea of the EM algorithm is to start with an initial guess estimate of parameters. Then it iteratively rescores the objects against the mixture density produced by the parameter vector. Then the parameter estimates are updated by the use of rescored objects. This can be done in two important steps.
Step-1: Randomly make an initial guess of the parameter vector. In this step, we will randomly select k objects as cluster means or centers and make guesses for additional parameters needed.
Step-2: Update the parameters estimates by using two steps:
(i) Expectation Step:
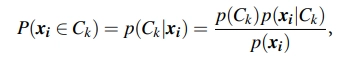
In this step, we will assign each object xi to cluster Ck with the above probability, where each probability follows the gaussian distribution with mean mk and with expectation Ek. Thus we can say that this step will give how probable that each object will belong to a particular cluster. We can say that these probabilities are the expected cluster membership probabilities for object xi.
(II) Maximization Step: Here, we try to maximize the probabilities of each object belonging to that cluster by re-estimating the model parameters by using
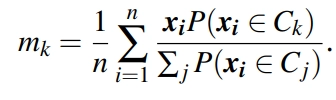
Applications
- It has the ability to fill the missing data in a sample.
- It can be used as a simple unsupervised data clustering algorithm.
- It is frequently used in estimating parameters for mixed models or any other mathematical models. For example, it is estimating the parameters for HMM model.
- The fields of image reconstruction and other fields like medicine and structural engineering also use the EM algorithm.
Key Terms in Expectation-Maximization (EM) Algorithm
- Latent Variables: Hidden variables that are not directly observed but influence the observed data. The EM algorithm estimates these variables during its iterations.
- Expectation Step (E-Step): Computes the expected value of the log-likelihood function using current parameter estimates and observed data.
- Maximization Step (M-Step): Maximizes the expected log-likelihood function to update the parameter estimates.
- Likelihood Function: Measures how well the model explains the observed data based on the current parameter values.
- Convergence: The process of iteratively updating parameters until changes in the log-likelihood or parameters are below a defined threshold.
- Initial Parameters: Starting values for the parameters, which influence the speed and outcome of convergence.


 8+ registered
8+ registered 

