XGBoost Features
Model Features
The model's implementation incorporates features from the sci-kit-learn and R implementations and novel features such as regularisation. Gradient boosting can be done in three different ways:
- The learning rate is crucial and included in the Gradient boosting algorithm, also known as the gbm.
- With both L1 and L2 regularisation, regularised Gradient boosting is possible.
System Features
The library has a variety of computing settings, that is:
- CPU cores play a vital role; parallelization occurs during the tree construction
- By using multiple devices, distributed computing may train extensive models.
- For exceedingly massive datasets that don't fit in memory, out-of-core computing is used.
Algorithm Features
The algorithm's implementation was designed to maximize computation time and memory resources. One of the design goals was to make the most available resources to train the model. The following are some significant elements of algorithm implementation:
- Implementation of Sparse Aware with automatic handling of missing data values.
- A block structure supports the parallelization of tree construction.
- Continued Training to improve a previously fitted model using new data.
XGBoost’s Algorithm
The Gradient boosting decision tree machine is implemented in the XGBoost package.
Multiple additive regression trees, Gradient boosting, stochastic Gradient growing, and Gradient boosting machines are all terms used to describe this approach.
Boosting is an ensemble strategy that involves adding new models to old models to remedy faults. Models are added logically until there are no more improvements to be made. Take AdaBoost algorithm, for example, weights data points that are difficult to forecast.
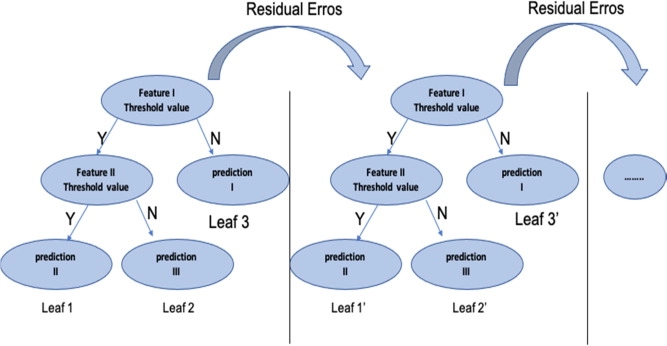
Gradient boosting is an algorithm that involves creating new models that forecast the errors of previous trees, which are then combined to form the final prediction.
Both regression and classification predictive modeling issues can be solved using this method. Gradient boosting gets its name because it uses a gradient descent approach to minimize loss when adding new models.
PYTHON CODE
# Importing the libraries
import numpy as nps
import matplotlib.pyplot as plts
import pandas as pds
#Dataset churn_modelling
dataset = pds.read_csv('Churn_Modelling.csv')
x = dataset.iloc[:, 3:13].values
Y = dataset.iloc[:, 13].values
# Encoding of categorical data
from sklearn.preprocessing import LabelEncoder, OneHotEncoder
labelEncoder_X_1 = LabelEncoder()
X[:, 1] = labelEncoder_X_1.fit_transform(X[:, 1])
labelEncoder_X_2 = LabelEncoder()
X[:, 2] = labelEncoder_X_2.fit_transform(X[:, 2])
oNEhotencoder = OneHotEncoder(categorical_features = [1])
X = oNEhotencoder.fit_transform(X).toarray()
X = X[:, 1:]
# Ratio 0.2 for Splitting the dataset into the Training set and Test set
from sklearn.model_selection import train_test_split
X_tr, X_ts, y_tr, y_ts = train_test_split(
x, Y, test_size = 0.2, random_state = 0)
# Fitting XGBoost to the training data
import xgboost as xb
my_ml = xb.XGBClassifier()
my_ml.fit(X_tr, y_tr)
# Predicting the Test set results
y_pre = my_model.predict(X_ts)
# Making the Confusion Matrix
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(y_test, y_pred)

You can also try this code with Online Python Compiler
Output
Metric-’Accuracy’=0.8645
How to optimize?
- Regularization: Because trees assemble decisions, they occasionally provide quite complex results. XGBoost employs Lasso and Ridge Regression regularisation to penalize the highly complex model.
- Parallelization and Cache block: In XGboost, we can't train several trees simultaneously, but we can create different tree nodes simultaneously. Data must be sorted for this to happen. It keeps the data in blocks to minimize the cost of sorting. It saved the data in compressed column format, with each column ordered by its corresponding feature value. By balancing any parallelization overheads in the calculation, this choice enhances algorithmic performance.
- Tree Pruning: XGBoost starts pruning trees backward, using the max depth argument as the stopping criteria for branch splitting. This depth-first method dramatically enhances computing performance.
FAQs
1. What is the XGBoost algorithm?
XGBoost is a scalable and highly accurate version of Gradient boosting that pushes the limits of computing power for boosted tree algorithms. It was designed primarily to increase machine learning model performance and computational speed.
2. What is XGBoost, and how does it work?
The Gradient boosted trees algorithm is implemented in XGBoost, a widespread and efficient open-source implementation. Gradient boosting is a supervised learning approach that combines the estimates of a set of smaller, weaker models to predict a target variable accurately.
3. Is XGBoost a classification or regression?
Execution speed and model performance are the two key reasons to employ XGBoost. On classification and regression predictive modeling issues, XGBoost dominates structured or tabular datasets.
4. What is the use of XGBoost?
XGBoost can be defined as a scalable machine learning system for tree boosting that uses a tree-based ensemble machine learning algorithm. Extreme Gradient Boosting is abbreviated as XGBoost. To determine the optimum tree model, it employs more precise approximations.
Key Takeaways
So that's the end of the article.
In this article, we have extensively discussed the Extreme Gradient Boosting Machine and its implementation in python.
Isn't Machine Learning exciting!! We hope that this blog has helped you enhance your knowledge regarding Gradient Boosting Machine and if you would like to learn more, check out our articles on MACHINE LEARNING COURSE. Do upvote our blog to help other ninjas grow. Happy Coding!





























 6+ registered
6+ registered 

