Do you think IIT Guwahati certified course can help you in your career?
Introduction
We live in an interconnected world where the transfer of information takes place so effortlessly. Do you know that distributed systems play a significant role in this? But as these systems are very complex, there can be certain issues, resulting in some unexpected behavior.
If you are wondering what these failures are, why they occur, and how they can be avoided, we will shed some light on these topics, and you will get all the answers to your questions. In this article, we will discuss about failures in distributed systems with their types and failure models.
Moving forward, let's discuss in brief about distributed systems.
Distributed Systems
Distributed systems are like groups of people who work together to complete a task. Like in a group project, each person is allotted a specific task to fulfill a common goal; similarly, in distributed systems, each device consists of its processing power and performs tasks independently. These devices communicate with each other over a network to complete their common goal.
Distributed systems are composed of independent devices that work together to complete a common task by communicating with each other over a network. They are connected through a central computer network and appear as a single computer to the end-user. This connection is facilitated by distributed system software.
Distributed systems offer several advantages, but at the same time, they are subject to some failures. ‘Failure’ here can refer to interruption in services, loss of consistency in the application, etc. Therefore, they contribute to unexpected behavior of the system.
There may be several reasons why failures can occur in distributed systems. Let's understand the failures in distributed systems through an example; assume there is an organization that consists of various distributed systems connected for providing services to its customers, and it experiences a network failure.
Now, since the devices are unable to communicate with each other, so the customers are unable to access services. This network failure causes havoc and decreases efficiency to a great extent and results in a great financial loss.
This type of failure can be referred to as software failure, and similarly, there can also be certain failures due to hardware. Software and hardwarefailures come under system failure. There are four types of failures in distributed systems:
System Failure
Communication Medium Failure
Secondary Storage Failure
Transaction failure.
Moving forward, let's discuss each one in detail.
Types of Failures in Distributed Systems
There are mainly four types of Failures in distributed systems:
System Failure
System failures occur when a certain kind of disruption results in an overall decrease in the system's functionality. The system may freeze or reboot during this type of failure. In System Failures, the content of primary memory is lost; on the other hand, the secondary storage is fine. Due to this, the processor is unable to execute stuff.
Reason: These types of failures occur due to hardware or software failure.
Recovery: System Failure can be handled by rebooting the system and identifying the critical points
Software failure
As the name suggests, these are caused due to the failure in software components that result in the instability of a system and unexpected results.
Factors contributing to software failures include software bugs, design flaws, logical errors, viruses, operator errors, environmental factors, etc.
There are several examples of software failure in the industry; one such failure happened with Knight Capital Group, where a software failure resulted in the loss of 440 million dollars in about 40 minutes. This happened due to a software configuration error, where they introduced a new algorithm among all the trading stocks. Due to this, many wrong orders were generated, and their system could not handle that.
Hardware failure
A hardware failure occurs due to damage to the physical components.
Factors contributing to hardware failure include physical damage, environmental factors, power surges, heat, overworked components, etc.
Communication Medium Failure
There is a channel through which the exchange of information occurs between systems, so when there is a certain kind of interruption or disruption in those channels, it results in communication medium failure. Below are some significant points regarding communication medium failure in distributed systems.
Reason: Communication failure occurs due to failure in the communication link. The standard errors seen during communication medium failure include wrong ordering of messages, disruptions in communication lines (communication lines failure), and lost messages.
In communication line failure, the network may be divided into more than two independent groups. This is referred to as network fragmentation.
Each fragment consists of sites that may continue to run; hence, accessing data from these different fragments becomes challenging and results in failure.
Recovery: The communication medium failure can be handled using error-routing protocols. Error routing protocols help in detecting errors in link and node failures and other network-related problems.
Secondary Storage/ Media Failure
Secondary storage failure occurs when there is a certain kind of malfunctioning in the secondary storage (such as HDDs and SSDs). Below are some of the major points regarding secondary storage failure.
Reason: This type of failure can occur due to errors in hardware or operating systems. The secondary storage consists of a ‘second archive’ that consists of a database; when the failure occurs, it is impossible to access the database.
Recovery: We can deal with this failure by using disk storage and archiving the information.
Transaction Failure
Distributed systems consist of transactions, which are a series of operations. Transaction failure occurs when a transaction is not completed and is interrupted. Below are some of the major points regarding transaction failure.
Reason: Translation failure can occur by when incorrect input is provided.
It may result in wrong execution and can cause a system to go into a deadlock situation.
Certain algorithms prove to be the root cause of failure. Such as, a few concurrency control algorithms do not allow a transaction to move forward in the process if the transaction wants to access a resource that is currently in use by some other transaction.
Recovery: To deal with this kind of failure, we need to abort the transaction and reset the database to the state when the transaction started.
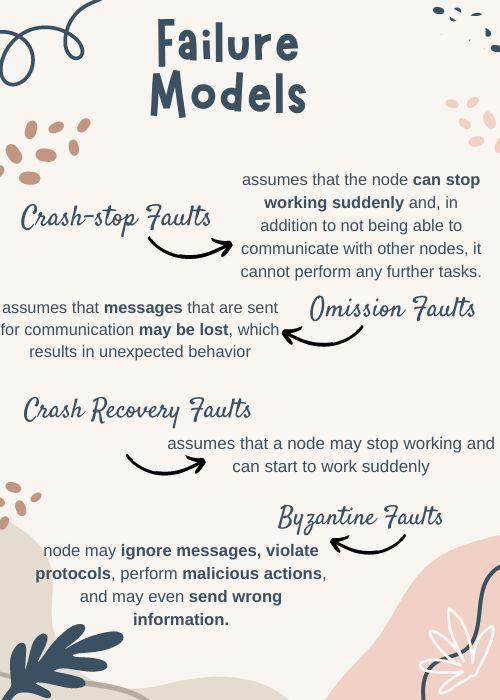
Failure Models
Failure models are the representation of how failures may occur in the system. There are mainly four types of failure models: Crash-stop faults, omission faults, crash recovery faults, and byzantine faults.
Crash-stop Faults
This model assumes that the node can stop working suddenly. Itis not able to communicate with other nodes and cannot perform any further tasks.
Omission Faults
We know that components of the system communicate with each other through certain messages.
The Omission fault model assumes that messages sent for communication may get lost, which results in unexpected behavior.
Crash Recovery Faults
The Crash Recovery Model assumes that a node may stop and start to work suddenly; therefore, there is a partial data loss because of this sudden crash.
Byzantine Faults
The Byzantine fault model assumes that a node may ignore messages, violate protocols, perform malicious actions, and may even send wrong information.
The difficulty of the above models can be stated as follows:
Distributed systems are independent devices that work together to complete a common task by communicating with others over a network and are connected by a central computer network, which consists of distributed system software and appears to be a single computer to the end-user.
What are the types of failures in distributed systems?
There are mainly four types of failure in distributed systems: system failure, communication medium failure, transaction failure, and media failure.
What is System Failure?
System failures occur when a certain kind of disruption results in an overall decrease in the system's functionality. In System Failures, the content of primary memory is lost; on the other hand, the secondary storage is fine.
What is Transaction Failure?
Transaction failure occurs when a transaction is not completed and is interrupted. Translation failure can occur by incorrect data input. It may result in wrong execution and can cause a system to go into a deadlock situation.
What is software failure?
Software failures are caused due to the failure in software components that result in the instability of a system and unexpected results. Factors contributing to software failures include software bugs, design flaws, logical errors, viruses, operator errors, environmental factors, etc.
Conclusion
In this article, we have discussed about failures in distributed systems. We have also discussed types of failures in distributed systems and failure models. To learn about deadlock detection in distributed systems, you can refer to this article- Deadlock Detection in Distributed Systems.
You can read more such descriptive articles on our platform, Coding Ninjas Studio. You will find straightforward explanations of almost every topic on the platform. So take your preparation journey to the next level using Coding Ninjas.































 9+ registered
9+ registered 

