Get a skill gap analysis, personalised roadmap, and AI-powered resume optimisation.
Introduction
Nowadays, fake news has become a very common thing. With the increase in social media users and digital information, it has become difficult to distinguish between fake and real news. Fake news can pose a significant threat to society.
In this blog, we will discuss possible methods for solving the problem of fake news detection and build an artificial news detection project in Data Mining. In the next sections, we will discuss Fake News and some of the terms associated with it in detail.
What is Fake News?
Fake news is generally referred to news which is either incorrect, misleading or exaggerating something to higher levels. It is created to deceive people and fulfill someone's personal interests. We all see fake news circulating from time to time on the internet. These news outlets sometimes seek to gain unfair financial advantages or promote political propaganda.
Some of the characteristics of Fake News include:
Misinformation - This refers to providing information which is intentionally or unintentionally incorrect.
Hoax - This refers to the information created to trick people into believing something which is not true.
Clickbait - It is the information which has misleading headlines which are unrelated to the content.
Propaganda - Propaganda refers to biased news which is circulated to gain unfair advantage over something.
How to Solve the Problem of Fake News Detection?
So how do we separate fake news from real news? Fake news generally contains hoaxes (trick or clickbait) or information that is exaggerated. Using data mining, we can analyze this data and check whether the news statement has any fake information.
The prerequisites required for this project are the following.
Python
Data Mining
Machine Learning
Visualization
In this project, we will first remove all the null entries in the dataset. Then we will transform the data according to our needs by removing special characters and removing stop words. Stop words are the words that occur frequently in the language.
In the next step, we will use various visualization techniques to derive insights from the data and discover patterns in the data. In the final step, we will train our ML Model and calculate results like accuracy.
Steps involved in Fake News Detection Project in Data Mining
Requirements
To develop this project, we will need the following libraries in Python.
Pandas
Seaborn
Matplotlib
Sklearn
NLTK
Dataset
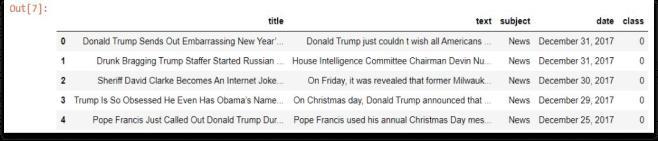
The dataset we are using has the following columns about the news data.
title - This column contains the title of the news article.
text - This column contains the content of the news article.
subject - This column contains the category of the news article.
class - This article contains whether the news article is true (class=1) or false (class=0).
Import the Libraries
We will first install all the dependencies and import all the necessary libraries.
// Importing the libraries
import re
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import string
import nltk
from wordcloud import WordCloud
from nltk.tokenize import word_tokenize, sent_tokenize
from nltk.tokenize import TweetTokenizer
from nltk import PorterStemmer
from nltk.corpus import stopwords
from tqdm import tqdm
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.model_selection import train_test_split
from sklearn.metrics import f1_score, precision_score
from sklearn.linear_model import LogisticRegression
from xgboost import XGBClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn import metrics
You can also try this code with Online Python Compiler
In this set, we will modify the data in the dataset according to our requirements. We will remove all the special characters and spaces, stopwords, and short words (less than three characters) from the new text.
def clean_text(input_text):
processed_sentences = []
stop_words = stopwords.words('english')
for sentence in sent_tokenize(input_text):
# Special characters
modified_text = re.sub("[^a-zA-Z]", " ", sentence)
// converting to lowercase
modified_text = modified_text.lower()
# Stemmer
stemmer = PorterStemmer()
# Tokenize the text
token_text = word_tokenize(clean_text)
# Removing stop words and short words
token_text = [stemmer.stem(i) for i in token_text if i not in stop_words and len(i) >= 3]
processed_sentences.append(" ".join(text_tokens))
return " ".join(processed_sentences)
data_set['clean_text'] = data_set['text'].apply(lambda i : clean_text(i))
You can also try this code with Online Python Compiler
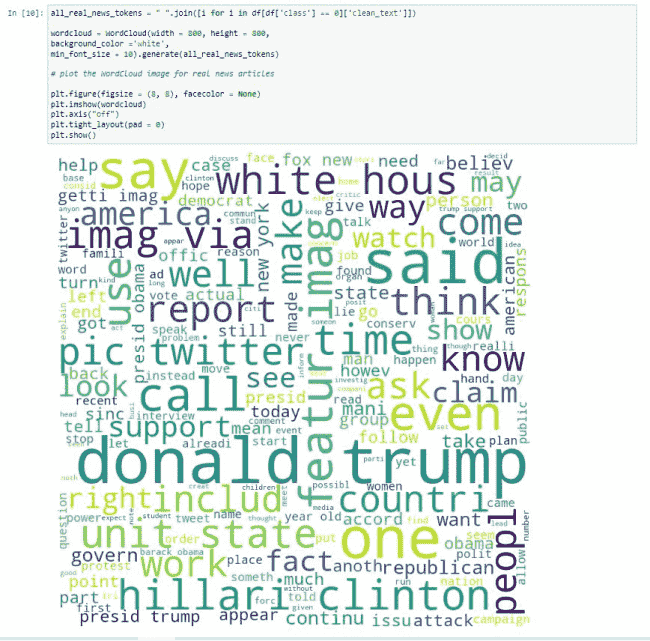
WordCloud is a popular data visualization technique in Python that allows us to view text data as word clouds. The size of each word indicates its frequency in the text.
Let us create and analyze the word clouds of both natural and fake comments separately.
// Real Token wordcloud
real_news_tokens = " ".join([i for i in data_set[data_set['class'] == 0]['clean_text']])
wordcloud= WordCloud(width = 800, height = 800,
background_color ='white',
min_font_size = 10).generate(real_news_tokens)
plt.figure(figsize = (8, 8), facecolor = None)
plt.imshow(wordcloud)
plt.axis("off")
plt.tight_layout(pad = 0)
plt.show()
You can also try this code with Online Python Compiler
In the next step, we must convert this data into the TFIDF method. TFIDF vector stands for the term Frequency-Inverse Document Frequency vector. This vector type is used in natural language processing to analyze the text.
The last step in this project is to train our model. For this project, we will use Logistic Regression and Decision Tree Classifier to evaluate our accuracy score.
# Initialising the model
logisitic_regressor = LogisticRegression(random_state = 0)
logisitic_regressor.fit(x_train_tfidf, y_train_tfidf)
# Computing the F1 score and the precision
prediction_tfidf = logisitic_regressor.predict(x_test_tfidf)
logistic_f1_tfidf = f1_score(y_test_tfidf, prediction_tfidf)
logistic_precision_tfidf = precision_score(y_test_tfidf, prediction_tfidf)
logistic_f1_tfidf, logistic_precision_tfidf
You can also try this code with Online Python Compiler
We received high accuracy (98.45%) and precision (99.39%) scores from our model. This means that our model can differentiate between fake news and real news successfully.
Frequently Asked Questions
What challenges are faced in Fake News Detection?
Some of the challenges faced in Fake News Detection include the randomness of the fake news, the credibility of the source, limitations of algorithms, and finding the optimaltrade-off between false positives and false negatives.
What type of characteristic features can be helpful in fake news detection?
In Fake New Detection, features like word frequency, language patterns, sentiments, source credibility, etc., can be useful for separating fake information from real one. However, these features do not guarantee partial accuracy.
On factors does the Accuracy of a Fake News Detection Model depend?
The frequency of a Fake News Detection Model depends on various factors like the algorithm used for training the machine learning model, size of the dataset, credibility of the source, data features used, etc.
Conclusion
In this article, we made a Fake News Detection Project in Data Mining. In the first section, we briefly discussed the overview of the project. Then we discussed a step-by-step walkthrough of the article with code and its explanation and outputs. In the end, we concluded by discussing some frequently asked questions.
So now that you know about Fake News Detection using Data Mining, you can refer to similar articles.































 9+ registered
9+ registered 

