Do you think IIT Guwahati certified course can help you in your career?
Introduction
Computer vision has grabbed enthusiasts’ attention ever since its concepts were put forth. However, The past few years have been nothing short of revolutionary for this domain of deep learning owing to the rise of technology that can handle the intense computation it demands. Smartphones and laptops make intensive use of computer vision wherever possible. Computer vision is the branch of AI that deals with image learning. But how exactly does a computer recognize an image? It is similar to how humans perceive and interpret visuals. Suppose you are given two images and you have to identify if the given images are similar. How would you go about it? You would look for some essential features of both the images and see if they match. Computers simulate it in the same way.
What is Feature Matching?
Before we learn about feature matching, let us understand what exactly do we mean by a feature. A feature is a piece of information that can be used to solve a computational task related to a certain application. Points, edges, or objects specific to a structure in the image may be considered a feature. Features can be subdivided into 2 main categories-
Keypoint Features - These are the features that are located in some specific locations in the image. It could be a mountain peak or building corners. They are described by the appearance of patches of pixels surrounding the location.
Edges - Edges define the boundaries and can be excellent indicators because they signify a sharp discontinuity in pixel values. Edges can be matched based on their local appearance and orientation.
Components of Feature Matching
Interest Point Identification
First, we need to identify an interest point. An interest point is expressive in texture. It is a point at which the direction of the boundary of the object changes significantly. Or it could be the intersection of two edge segments.
The actual definition might be a bit ambiguous. Let us understand with an example.
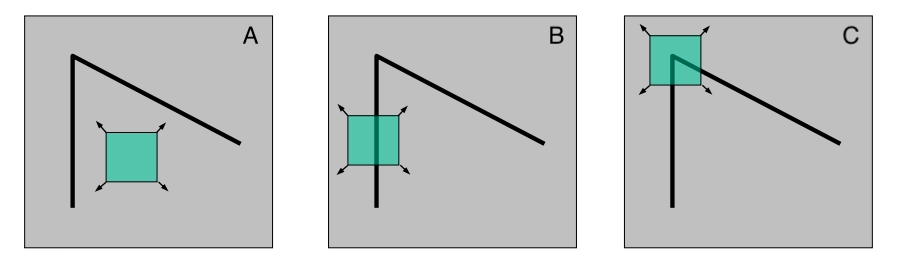
In the above three images, we have to decide which one would make the best interest point. In image A, the window is over the flat gray area which is consistent all over the window. So there would be no change in any direction. In image B, the window is over the edge and there is no change in the direction of the edge. In image C, the window is over the corner and there would be a significant change in any direction. Safe to say, C would make the best interest point among the three. There are a few properties associated with interest points that are worth keeping in mind.
Interest points are well localized.
They are stable under varying conditions of illumination and other factors and can be reliably computed with a decent degree of repeatability.
They should provide for efficient detection.
Harris corner Algorithm, Scale-invariant feature transform, and Speeded up Robust feature are a few techniques that can be employed for interest point identification.
Description
The visual descriptions are defined around each feature point and these are invariant to other factors like illumination and in-plane rotation. This is done with the help of descriptor vectors that capture all the necessary information. They describe elementary characteristics like colour, shape, and texture around the feature point.
Feature descriptors store the information by encoding it into a unique numerical series which enable the computer to differentiate among the features. Ideally, descriptors capture information in such a way to make it invariant to transformations. Descriptors can be subdivided into 2 categories - Local and Global descriptors.
Local Descriptor: The aim is to capture the information in the most immediate surroundings of the feature point. They try to resemble the local neighbourhood of the feature point.
Global Descriptor: They capture the image as a whole. This makes it highly unreliable in real-world scenarios since the slightest transformation in an image sample may cause the model to fail.
SIFT(Scale invariant feature transform), SURF(speeded up robust features), and BRISK(binary robust invariant scalable keypoints) are some of the commonly used techniques for generating descriptors.
Feature Matching
Feature matching or image matching is widely used for various real-world applications such as object recognition and image registration. It establishes the correspondences between two similar images based on the resulting interest points and detectors. We match the local descriptors to draw the correspondence between the images in comparison.
Feature matching is the process of comparing two images based on their respective keypoints(features and descriptors). The search distance algorithm is a widely used technique for the process.
Mention some real-life applications of feature matching.
Google lens on your smartphone studies the corresponding features in the captured image to bring the results. Face detection unlocks on your smartphone detects essential features on the user’s face to grant them access.
Which of the 2 classes of descriptors - local or global is more reliable and why?
Local descriptors capture the information in the immediate surrounding of the feature point. This is a more robust technique since capturing information locally around each feature point makes it invariant to transformations.
Global descriptors capture the image as a whole which makes it highly vulnerable to failures due to transformation in images.
Conclusion
This blog gives a high-level overview of feature matching. The blog discusses all the stages involved in the process and lists out the popular algorithms for each of these processes. We recommend going through a blog a few times to get a better grasp of the details.






























 9+ registered
9+ registered 

