Do you think IIT Guwahati certified course can help you in your career?
Introduction
Anyone who is into machine learning must have faced the issue of the poor quality model prediction. What can be the reason for it? In machine learning, there is a saying, “Garbage in, garbage out.” If data fed into the model is of poor quality, the model will perform poorly. So the quality of model prediction dramatically depends on the input data,i.e., features. Unnecessary features affect the quality of the model and slow down the training time of the model. So to overcome this shortcoming, Feature selection is essential.
Feature Selection selects the most significant features that directly influence the output variable. Thus, it helps in improving the model accuracy. Feature selection helps remove irrelevant, reductant features or noisy features, reducing the computation time, higher learning accuracy, and better model interpretability.
Note: Feature selection is always performed after data pre-processing.
Now, let us have a look at why we need feature selection.
The higher the number of features, the model is more prone to overfitting. Feature Selection methods help us reduce the dimension of the features without much loss of meaningful information. Thankfully, Scikit-learn has made feature selection easier.
Scikit-learn provides lots of techniques to select features, but most feature selection techniques are divided into three major categories;
Filter-Based:
Filter Method applies statistical measures to compute a score of each feature, and selection is made according to the importance of the individual feature. Filter-based methods are often univariate and consider features independently.
Filter methods are effectively fast, thus reducing the computational time, and are robust to overfitting. But they tend to select redundant variables because they do not consider the relationship between features. These methods are independent of any machine learning algorithms to be used as an input to any machine learning algorithm.
Some of the significant examples of Filter-based methods are:
Anova F-value
Anova F-value is used to calculate the degree of linearity between
dependent and independent features. Higher F-value indicates a
higher degree of linearity and vice-versa.
Chi-Squared Test
We apply Chi-square Test to categorical features, which are calculated
between each feature and selected features.
Information Gain
Calculate the reduction in entropy from transformation. Information
gain calculates the information gained with respect to the output
Calculate the correlation between the feature and the output variable. Independent features should not be correlated among themselves.
Wrapper-based:
Wrapper-based methods select feature sets as a search problem, use a combination of features, evaluate it, and compare it to other varieties. The wrapper method finds the best possible array of features. Due to repeated learning steps and cross-validation, wrapper methods are more expensive than filter and embedded forms.
Generally, wrapper methods are not recommended for the higher number of features.
Standard wrapper methods are:
Subset Selection
In Subset Selection, we start with all the features and remove
the least significant feature at each iteration which improves the
performance of the model.
Forward Stepwise
In forward stepwise, we initially start with zero variables and add
features that improve the model’s accuracy. We keep on
iterating until no improvement is observed.
Recursive Feature Elimination(Backward Stepwise)
It is a greedy optimization algorithm in which keeps on removing the
worst features in every iteration until all the features are exhausted.
Embedded-Based:
The embedded Method is an inbuilt feature selection method. It combines the qualities of filter and wrapper methods. It is implemented by algorithms that have their feature selection methods in them. They are faster and more accurate than filter methods. Embedded methods are less prone to overfitting.
Some of the common examples of embedded-based are:
Regularisation
We add penalties on different coefficients to avoid overfitting. It has
The property to remove the irrelevant features by making their
Coefficients tend to zero.
Let us discuss some of the essential techniques of feature selection:
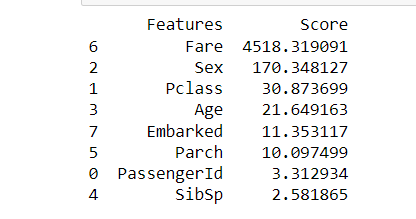
Selectkbest:
It is a filter-based technique that selects only top k features with the most vital relationship with the output variable. The scikit-learn library provides the SelectkBest class, which uses a different statistical test like chi-squared for Anova-F values to select a specific number of features.
We will use the chi-square test to select the top n features below.
We will be using a titanic data set for an explanation.
Code:
from sklearn.feature_selection import SelectKBest from sklearn.feature_selection import chi2
x = df.drop("Survived",axis=1) y = df["Survived"]
bestfeatures = SelectKBest(score_func=chi2, k=6) fit = bestfeatures.fit(x,y) dfscores = pd.DataFrame(fit.scores_) dfcolumns = pd.DataFrame(x.columns) #concat two dataframes for better visualization featureScores = pd.concat([dfcolumns,dfscores],axis=1) featureScores.columns = ['Features','Score'] print(featureScores.nlargest(10,'Score'))
Output:
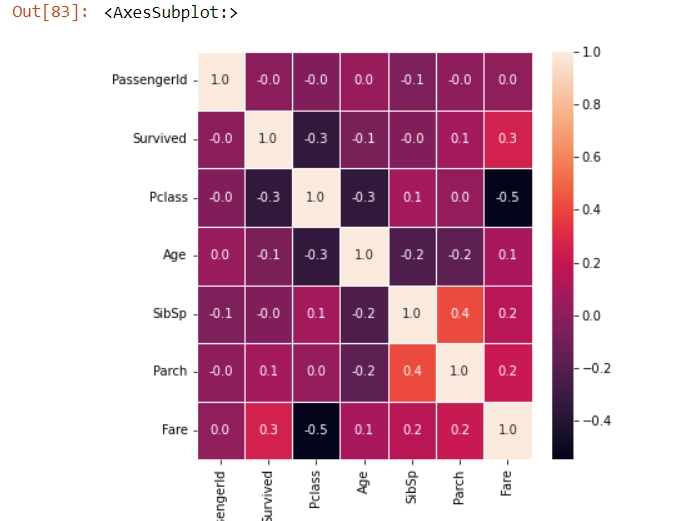
Correlation Matrix With Heatmap
Correlation is another filter-based technique. Correlation helps us find how one feature relates to another or the target variable. Correlation can be positive (increase in one value of feature increases the value of target value) or negative(increase in one matter of feature will decrease the value of the target variable).
Heatmap matrix makes it easier to interpret which features are mostly correlated to the target variable. We will plot a heatmap with the help of the seaborn library.
As we can see, the fare is highly related to the number of passengers surviving with respect to others.
Recursive Feature Elimination
It is a wrapper-based method generally used for smaller datasets. The main idea is to build a model on the entire dataset and compute the importance of each feature. We eliminate the least important feature, and the whole model is re-built, and we calculate the importance scores. We keep on iterating until the number of features is not equal to the number of features subset specified by the user. At last, we use optimal features to train the model.
Code:
from sklearn.ensemble import RandomForestClassifier from sklearn.model_selection import StratifiedKFold from sklearn.feature_selection import RFECV rfc = RandomForestClassifier(random_state=101) rfecv = RFECV(estimator=rfc, step=1, cv=StratifiedKFold(10), scoring='accuracy') rfecv.fit(x, y)
print('Optimal number of features: {}'.format(rfecv.n_features_)) print(np.where(rfecv.support_ == False)[0])##index of those features ##which are eleminated
Output:
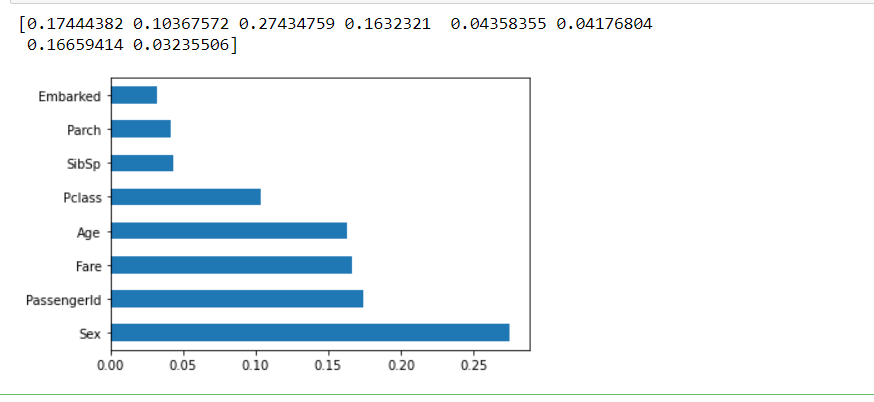
Feature Importance
Feature Importance is an example of embedded methods. Feature importance gives us the importance of each feature on your data; the higher the score, the more critical the feature is towards your output variable. We will be using an extra tree classifier for extracting top k features. Feature importance gives us better interpretability of the data.
Code:
from sklearn.ensemble import ExtraTreesClassifier import matplotlib.pyplot as plt model = ExtraTreesClassifier() model.fit(x,y) print(model.feature_importances_) #use inbuilt class feature_importances of tree based classifiers #plot graph of feature importances for better visualization feat_importances = pd.Series(model.feature_importances_, index=X.columns) feat_importances.nlargest(10).plot(kind='barh') plt.show()
Output:
Regularisation
Regularization is an embedded technique that adds a penalty to different parameters of machine learning algorithms to avoid overfitting. In L1 regularization, we apply the penalty over the coefficients multiplied by features. L1 has the property that it can shrink irrelevant features coefficients to zero. Thus, we can remove the feature from the model.
While in L2 regularisation, the coefficients are not shrunk to zero.
Code:
from sklearn.linear_model import Lasso, Ridge, LogisticRegression from sklearn.feature_selection import SelectFromModel from sklearn.preprocessing import StandardScaler scaler = StandardScaler() scaler.fit(x.fillna(0)) sel_ = SelectFromModel(LogisticRegression( penalty='l2')) sel_.fit(scaler.transform(x.fillna(0)), y) sel_.get_support()
From so far, we can see that sex and fare are the two features which are highly correlated with the output variable, while passangerId and sibsp are the least important features.
Those are some of the widely used techniques for feature selection. Except for Recursive Feature Elimination, all other methods are computationally less expensive and easier to implement.
Frequently Asked Questions:
1. How is feature Selection different from Dimensional Reduction? Ans. The objective of both is to remove irrelevant data. But dimensional reduction creates a new combination of features from the existing ones, while feature selection excludes features without any alteration.
2. Why should we use a subset of data instead of actual data? Ans. Unnecessary data impacts the model's performance and increases the training and testing time. So fewer data helps in solving these problems.
3. How to know which features are essential? Ans. By using feature importance of the model. It returns the importance score of each feature. The higher the score, the more relevant the data, and vice-versa.
4. What are the critical differences between Filter Methods(FM) and Wrapper Methods(WM)? Ans. The filter method is computationally less expensive than Wrapper Methods. Filter Methods use statistical methods for filtering, while the Wrapper method uses cross-validation. While the subset of features from the Wrapper Method is more prone to overfitting than Filter Methods.
Key Takeaways:
So that is the end of the article. Let us brief the article:
Firstly we saw why we need feature selection and how feature selection is essential for better model accuracy. Then, we saw the basic three feature selection methods in-depth and a few implementations of some of the most widely used cases of feature selection. Finally, we saw the critical differences between filter methods and wrapper methods.
Thus, Feature selection is one of the most vital techniques for model improvement.
Do not worry if you want to have in-depth knowledge of different techniques. We have a perfect tutor to help you out.






























 8+ registered
8+ registered 

