


























Introduction
Files contain a lot of information required by the system. The computer memory may require certain files during execution. We need very efficient methods to retrieve the information by accessing the files in the least time possible.

File access methods are needed to efficiently read and write data to and from files. Each method has its own advantages and disadvantages, and the choice of method depends on the specific needs of the application. Using an appropriate file access method can improve the performance and efficiency of an application.
In this article, we will learn about the five types of file access methods.
- Sequential access
- Direct access
- Indexed sequential access
- Relative Record Access
- Content Addressable Access
Types of File Access Methods in the Operating System
1. Sequential Access Method
It is one of the simplest access methods and is widely used in editors and compilers. You must have seen the audio cassettes. Even they use the same access method.
The files are a collection of records. Accessing the file is equivalent to accessing the records. In the sequential access method, each record is accessed sequentially, one after the other. Consider the below image for more clarity.
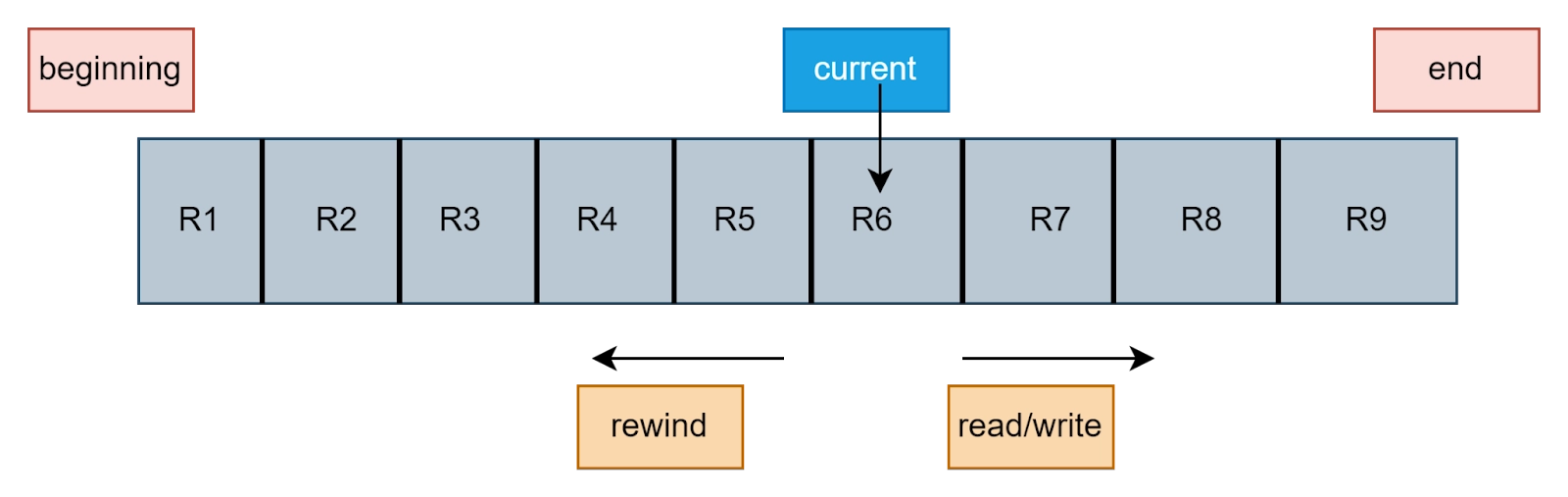
The figure represents a file. The current pointer is pointing to the record currently being accessed. In the sequential access method, the current pointer cannot directly jump to any record. It has to "cross" every record that comes in its path. Suppose there are nine records in the file from R1 to R9. The current pointer is at record R6. If we want to access record R8, we have to first access record R6 and record R7. This is one of the major disadvantages of the sequential access method.
The sequential access method has three operations:
- Read next: It will read the next record in the file. The file pointer (current pointer) will advance to the next record. It is similar to how we traverse the nodes in a linked list.
- Write next: This operation is used when some more information is to be included in the file. A new node (a record) will be added at the end of the file. The end pointer will now point to the node that has been added, marking it as the new end of the file. It is similar to adding a new node at the end of a linked list.
- Rewind: This will bring the read and write pointers to the beginning of the file.
Analysis of Sequential Access Method
- It is very simple to implement. The work is similar to a linked list.
- Since the records cannot be randomly accessed, it is not a very efficient method.
- It is a slow method.
Advantages of Sequential Access Method
Some advantages of the sequential access method include:
- Simple and easy to implement, requiring minimal hardware and software support.
- Low cost, as it doesn't require complex indexing or search algorithms.
- Highly efficient for dealing with large data sets, as data is stored in a linear fashion and can be accessed in a predictable manner.
- Suitable for applications that require processing of data in the order it was written, such as backup systems or data archival.
- Sequential access devices, such as magnetic tape, have a high storage capacity and can store data for long periods of time, making them suitable for archival storage.
Disadvantages of the Sequential Access Method
Here are some disadvantages of the sequential access method:
- Inefficient for random access: Sequential access is not efficient for randomly accessing data within a file, as it requires searching through the entire file to find the desired data.
- Limited concurrency: Concurrent access to a sequential file can be challenging, as only one process can access the file at a time.
- Inflexible data retrieval: Since data must be retrieved in the order it was stored, sequential access can be inflexible for applications that require accessing data in a non-linear fashion.
- Limited real-time access: Sequential access is not suitable for real-time systems, as data retrieval time can be unpredictable
2. Direct Access Method
In the direct access method, the files are considered as a sequence of blocks or records, just like the disk was considered to be divided into equal-sized blocks. The benefit of this method is that we can access any block randomly. The direct access method is known as the relative access method. The exact block address is known only to the operating system. When a user wants to access a particular block, he/she provides the relative block number, which the operating system then uses to find the exact block address.
This type of access method is used in database management systems.

The direct access method has the following operations:
- Read n: This operation is used to read the nth block. Read 6 would allow us to read block B6.
- Write n: This operation is used to write in the nth block.
- Goto n: This operation is used to directly access the nth block.
Analysis of the direct access method
- Faster than the sequential access method.
- Allows random access. Therefore there is no need to traverse all the blocks.
- Implementation is easy.
Advantages of the Direct Access Method
Some advantages of the Direct Access Method include the following:
- Random access to specific data within a file allows for quick and efficient data retrieval.
- High concurrency, enabling multiple processes to access the same file simultaneously and efficiently share data.
- Flexible data retrieval, suitable for accessing data in a non-sequential fashion.
- Efficient data modification, as changes to specific data can be made without rewriting the entire file.
- Suitable for real-time systems that require fast and predictable data access.
Disadvantages of the Direct Access Method
Some disadvantages of the Direct Access Method include the following:
- Inefficiency for Small Requests: The Direct Access Method can be inefficient when you need to retrieve small pieces of data frequently. This is because the method is optimized for accessing larger chunks of data, so it might not work efficiently for tiny bits of information.
- Space Management Challenges: Managing the available space using the Direct Access Method can be complex. It's like arranging things in a box – if you're not careful, things can get disorganized and jumbled up. This can lead to wasted space and difficulties in keeping track of where data is stored.
- Fragmentation Issues: Fragmentation can happen when there are gaps between stored data blocks. These gaps can result from adding, updating, or deleting records. Like a jigsaw puzzle with missing pieces, fragmentation makes it less efficient to use the available space.
- Varied Record Lengths: The Direct Access Method might not work well when dealing with records of different lengths. Imagine trying to fit objects of different sizes into fixed compartments – it can be challenging and lead to inefficiencies in storage and retrieval.
- Suboptimal Performance Patterns: Certain data access patterns might not work optimally with the Direct Access Method. It's like taking different routes to your destination – sometimes, the method might not be the fastest or most efficient way to retrieve the data you need.
3. Index Sequential Access/ Index Access
The major issue with the sequential access method was that it did not allow random access to the file records/blocks. The index sequential access method solves this problem. In this method, there is an index that holds the pointers to various blocks of the file. In order to access any block of the file, one has to first access the index, and from there, we can get the pointers to various blocks.
This method is very similar to the indexed file allocation method, where we had an index block that held pointers to various other disk blocks that were allocated to the file.
Analysis of Sequential Access Method
- It is a modification of the sequential access method. It allows random access.
- Apart from the file records, an extra index is required to keep track of the blocks.
- In case file size increases, the index may not be able to hold all the pointers due to memory constraints. Hence in such a case multi-level index may be used.
4. Relative Record Access
Relative Record Access is a method to access records in a file based on their relative position rather than their absolute position. Each record is assigned a unique relative record number (RRN) and must have the same fixed size. You can directly access a specific record by calculating its position using its RRN and the fixed record size. It is efficient for random or non-sequential access to records
Key Points of Relative Record Access
- Relative Record Access uses relative record numbers to represent the order of records in a file.
- RRA enables direct access to records, making it faster for random access.
- All records in the file have the same fixed size.
Advantages of Relative Record Access
Some advantages of the Relative Record Access method include the following:
- Direct access to records based on RRNs, saving time and processing power.
- RRA is simple to implement and understand and suitable for small-scale applications.
- It is efficient for random or non-sequential access to records.
- It doesn't require complex data structures or indexing.
Disadvantages of Relative Record Access
Some disadvantages of the Relative Record Access method include the following:
- It is not ideal for files with frequent updates or variable-length records.
- Records changes may disrupt other records' relative positions, which leads to data inconsistencies.
- It is limited to fixed-size records, which may waste space for smaller records.
- It may not be suitable for complex databases with dynamic data changes.
5. Content Addressable Access
Content-Addressable Access (CAA) is used in computer systems to retrieve data based on its content rather than its identifier or location. In Content Addressable Access, data is stored with a unique content-based address, such as a hash value derived from the data itself. When you want to retrieve specific data, you provide its content, and the system uses the content-based address to locate and return the matching data.
Key Points in Content-Addressable Access
- Content-Addressable Access is a method that retrieves data based on its content, not its location or identifier.
- Data is stored with a unique content-based address, typically generated using a hash function.
- When you want to retrieve specific data, you provide its content, and the system uses the content-based address to locate and return the matching data.
Advantages of Content-Addressable Access
Some advantages of the Content-Addressable Access method include the following:
- Data retrieval based on content, rather than traditional search methods, is quick and efficient.
- It reduces the need for maintaining complex data structures and indices.
- It suits applications like caching, data deduplication, and database systems.
- It prevents duplicate data entries, enhancing storage efficiency.
Disadvantages of Content-Addressable Access
Some disadvantages of the content-addressable Access method include the following:
- It handles large datasets with content-based addressing can be computationally expensive.
- The risk of collisions in hash functions may cause data retrieval errors.
- Applications needing ordered data retrieval may not find content-based addressing suitable.
- Selecting an appropriate hash function prevents performance issues and ensures data integrity


 9+ registered
9+ registered 

