Sample Test Cases
Input 1: 4 5
1 1 0 0 1
1 1 0 0 0
0 0 0 1 1
0 0 0 1 1
Output 1: 2
0 0
2 3
Explanation: There are two islands with length 3 and one with length 1. So four is the most common island size, and the top left corner coordinates of islands are (0, 0) and (2, 3).
Input 1: 3 3
1 1 0 0 1
1 1 0 0 0
0 0 0 1 1
1 0 0 1 1
Output 1: 2
0 4
3 1
Explanation: There are two islands with length 3 and two with length 1. So both are the most common island sizes. So we can output the coordinates of any one.
Approach
We can find the number of the island (number of connected components) using a depth-first search. Also, we can calculate the size of each island by keeping the count of all the valid cells visited during the DFS traversal.
So we can solve this problem by storing the coordinates of the top-left cell with the size of the island in a hashmap.
Steps to solve:
- Initialize a hashmap to hash integer with the vector of pairs. The integer represents the size, and the vector stores the top-left coordinate of all the islands of that size.
- Maintain a visited array to keep note of all cells that have already been visited.
- Traverse the given matrix row-wise, and if the current cell (r, c) is land (A[r][c] == 1) and is not visited (visited[r][c] == 0), initiate DFS traversal from this cell and keeps the count of all cells visited during traversal.
- If we are at coordinate (r, c) and A[r][c] == 1 and visited[r][c] == 0, then all the coordinates (x, y) such that x < r or y < c are already visited (if it was a land). So if we initiate the DFS traversal from (r, c), then we will not visit such cells during traversal. Thus we can claim the cell (r, c) is the coordinate of the top-left cell of an island.
- After traversal, store the size of the island and coordinate of the top-left cell in the hashmap.
- Iterate over the hashmap to find the size of the most common region and then print all the coordinates mapped with it.
Code
#include <bits/stdc++.h>
using namespace std;
const int mxRow = 1000, mxCol = 1000;
//rows, column
int N, M;
//input matrix
int A[mxRow][mxCol];
//boolean array to mark visited cells
//all the cells are initially unvisited
bool visited[mxRow][mxCol];
//displacement vectors (gives the coordinate of all the eight neighbours)
int dx[] = {-1, -1, -1, 0, 0, 1, 1, 1};
int dy[] = {-1, 0, 1, -1, 1, -1, 0, 1};
//function to check, whether the given cell can be visited or not
bool isValid(int x, int y){
//out of bound
if(x < 0 || y < 0 || x >= N | y >= M)
return false;
//water or already visited
if(visited[x][y] || !A[x][y])
return false;
return true;
}
//function to do depth first search for a 2D grid
void dfs(int r, int c, int &cnt){
//mark the cell as visited
visited[r][c] = true;
//visit the neigbours
for(int i = 0; i < 8; i++){
if(isValid(r + dx[i], c + dy[i])){
//if the neigbour is valid increment the length of region by one
cnt++;
dfs(r + dx[i], c + dy[i], cnt);
}
}
}
int main(){
cin >> N >> M; //rows, column
for(int i = 0; i < N; i++){
for(int j = 0; j < M; j++){
cin >> A[i][j];
}
}
//map to store the size and coordinate of top left cell
unordered_map <int, vector <pair<int, int>>> mp;
for(int i = 0; i < N; ++i){
for(int j = 0; j < M; j++){
if(!A[i][j] || visited[i][j])
continue;
//if the current cell is land (i.e, A[i][j] == 1)
//and is not visited (i.e, visited[i][j] == 0)
int cnt = 1; //initialize the region size by 1
//dfs call
dfs(i, j, cnt);
//(i, j) is the coordinates of top left cell
mp[cnt].push_back({i, j});
}
}
int most_common_region = 0; //store the number of most common region
int size = 0; //size of most common region
for(auto u : mp){
if(mp[u.first].size() > most_common_region){
most_common_region = mp[u.first].size();
size = u.first;
}
}
//traverse the vector mapped with size of most common region
//to print the coordinates of top left cells
for(auto u : mp[size]){
cout << u.first << " " << u.second << "\n";
}
return 0;
}
Example
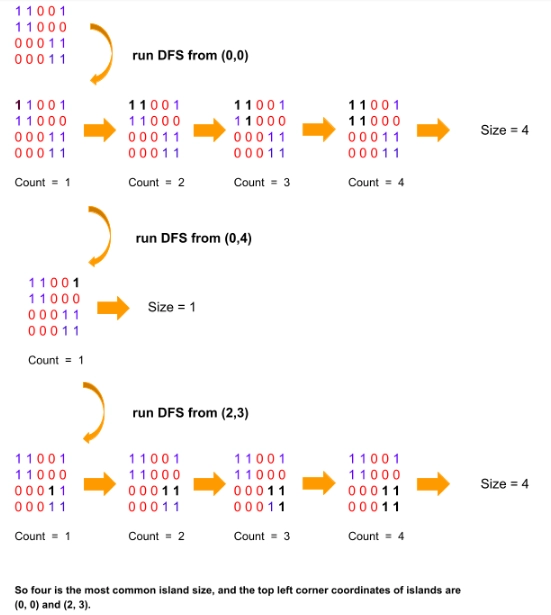
Time Complexity
The overall time complexity is O(N * M).
Space Complexity
We need an extra 2D boolean array of size N x M to mark the visited cells. So the overall space complexity is O(N * M).
Check this out, Fibonacci Series in Python
FAQs
-
What is DFS?
DFS stands for depth-first search. It is a graph theory algorithm for recursively traversing or searching graphs and trees.
-
What is the time complexity of DFS?
The time complexity of DFS is O(V + E), where V is vertices and E is edges.
-
What is the time complexity of unordered_map?
The average case time complexity of an unordered map is O(1).
Key Takeaways
In this article, we solved a graph theory problem. Having a good grasp of graph theory is very important for cracking coding interviews at MAANG.
Check out this coding ninjas' blog on graph theory algorithms for getting a better hold on it.
To learn more about such data structures and algorithms, Coding Ninjas Studio is a one-stop destination. This platform will help you to improve your coding techniques and give you an overview of interview experiences in various product-based companies by providing Online Mock Test Series and many more benefits.
Happy learning!






























 9+ registered
9+ registered 

