Do you think IIT Guwahati certified course can help you in your career?
Introduction
Hello Coders!
In this blog, we will tackle a problem where we have to find the maximum unique element in every subarray of size K for a given array. We will discuss the simple and efficient solutions to this problem and look at our solution's space and time complexity. We hope that you are excited to solve this problem.
So what are we waiting for? Let’s dig deep into the problem.
Problem Statement
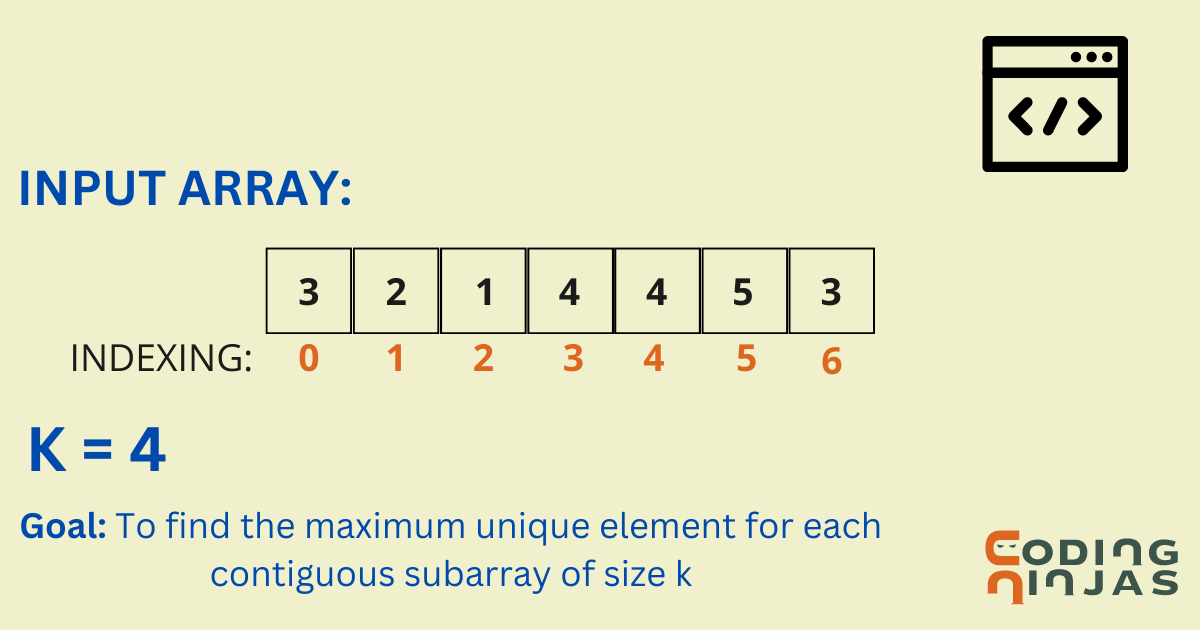
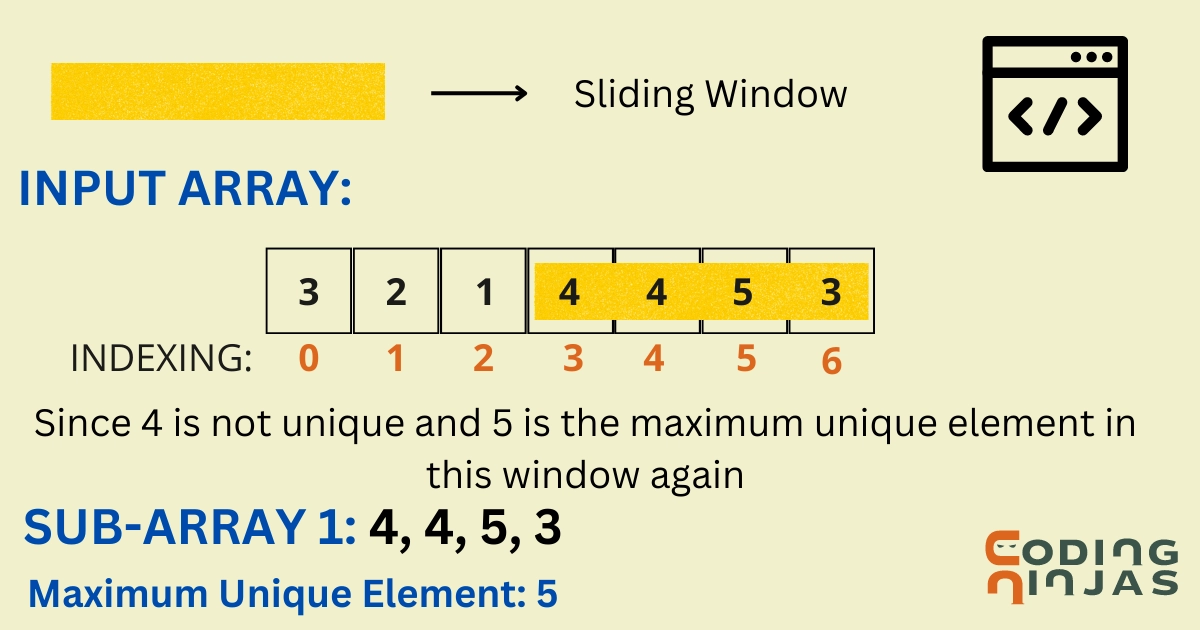
The problem is to “find the maximum unique element in every subarray of size K,” such that it has no duplicates in that subarray for a given array.
Let us look at some examples.
Example 01
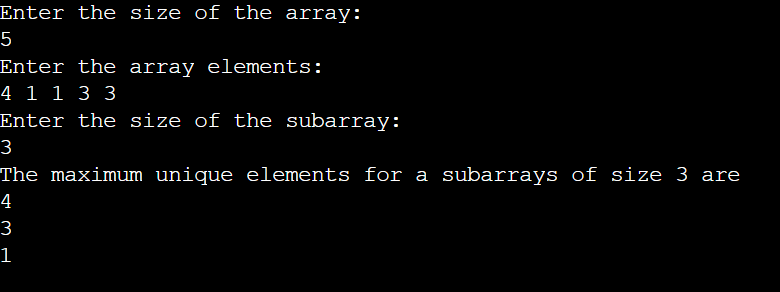
Input:
array = {4, 1, 1, 3, 3}
k = 3
Output:
4 3 1
Explanation:
Sub-array of size 3
Subarray {4, 1, 1}, max = 4
Subarray {1, 1, 3}, max = 3
Subarray {1, 3, 3}, max = 1
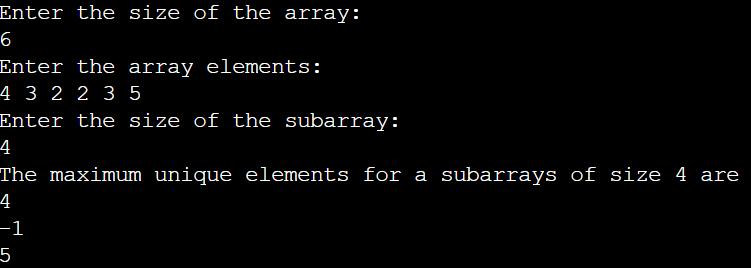
Example 02
Input:
array={ 4, 3, 2, 2, 3, 5}
k=4
Output:
4 -1 5
Explanation:
Sub-array of size 4
Subarray {4, 3, 2, 2}, max = 4
Subarray {3, 2 ,2, 3}, max = -1, since there are no unique elements.
Subarray {2, 3, 3, 5}, max = 5
Solution Approach
Let us look at the solution approaches for the given problem statement.
Simple Approach
This problem has a simple solution to it, which would be to run two loops and create subarrays. Basically, we have to find all distinct elements for every subarray and then print the maximum unique element in every subarray. In case there are no distinct elements present in a subarray we will return -1.
Outer loop: Takes all subarrays of size K.
Inner loop: Gets the maximum unique element of the current subarray.
Efficient Approach
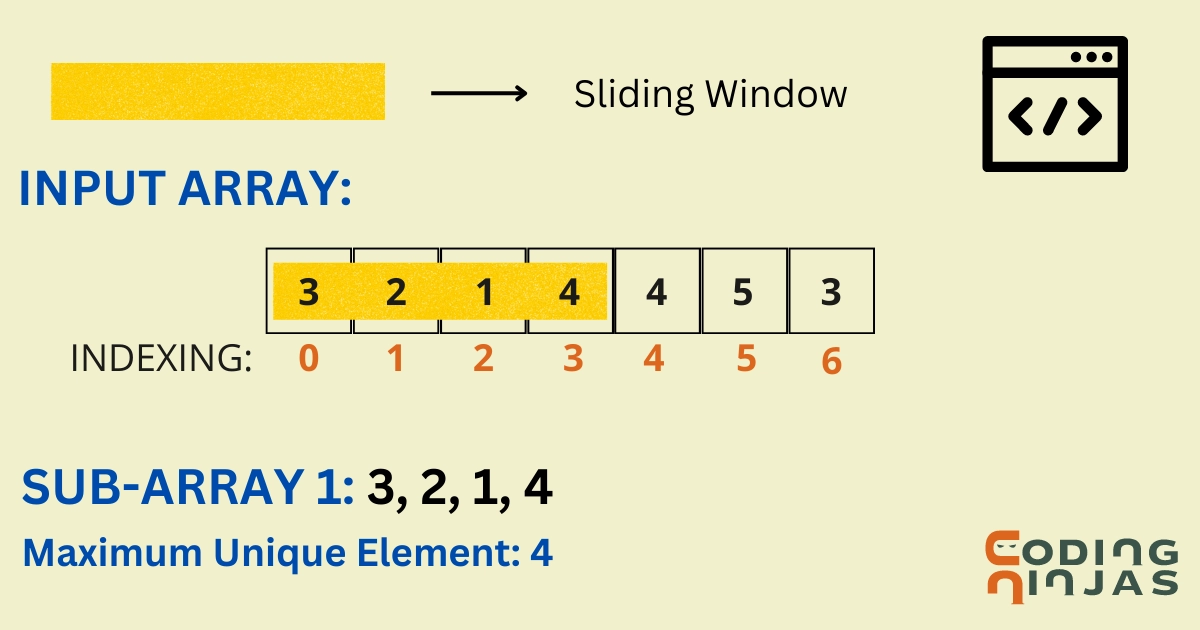
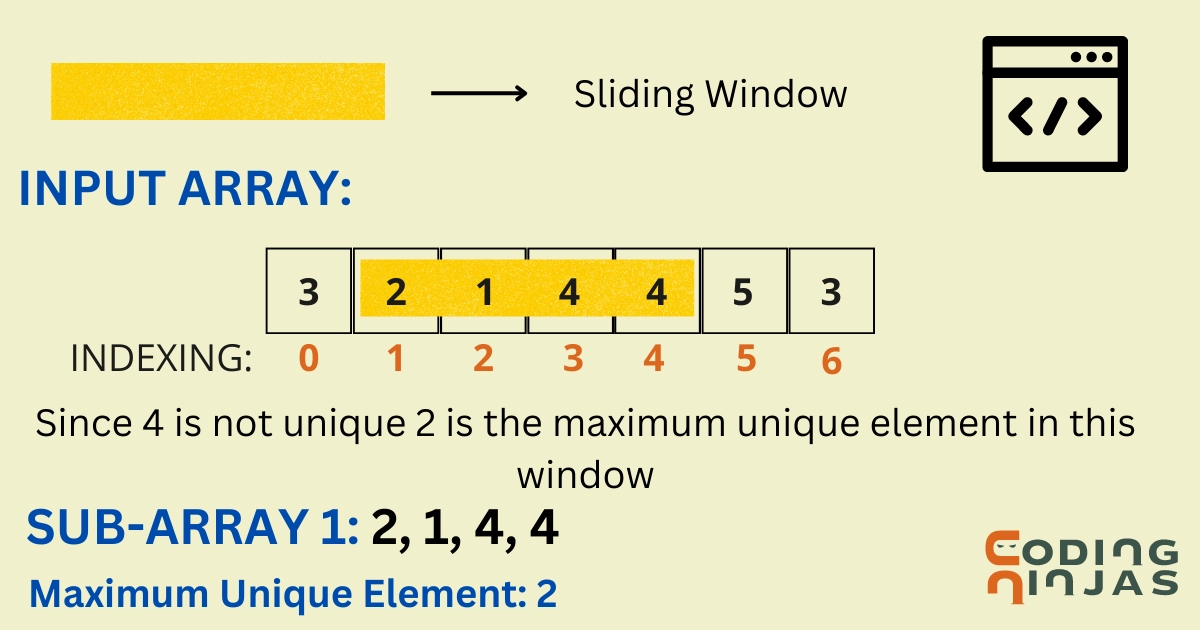
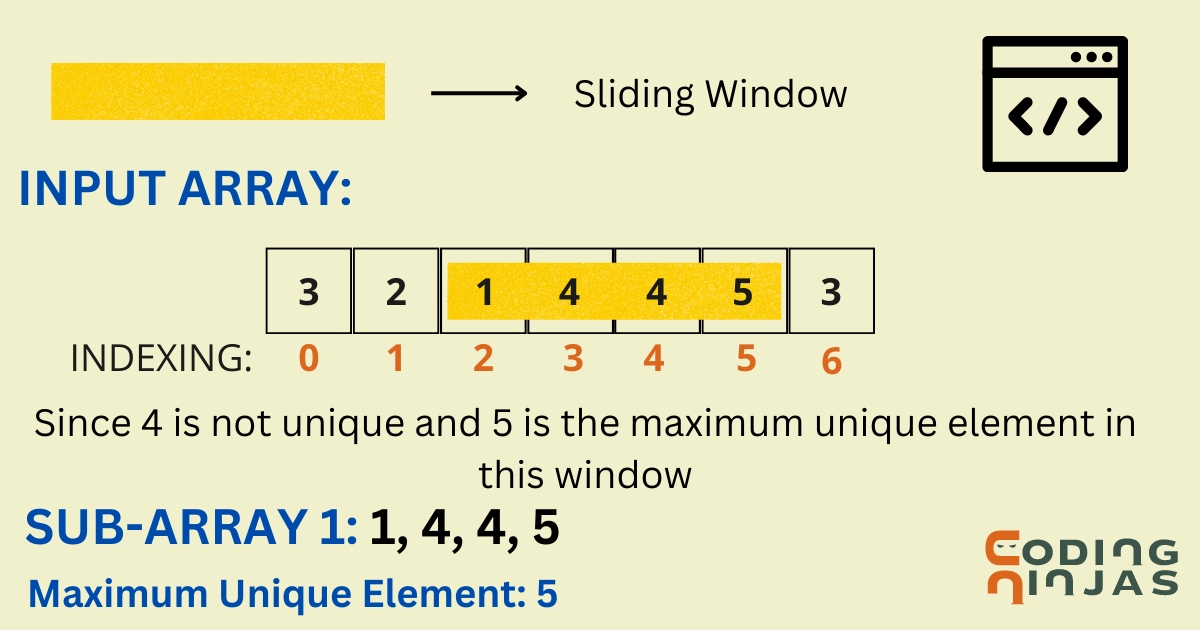
Moving on to the efficient approach, we can use the Sliding Window Method using a hash table. We will also use self-balancing BST(Binary Search Tree) to find the maximum unique element in every subarray.
Algorithm
A hash table will be used to store the counts of all the elements present in the current window.
We will use self-balancing BST (Binary Search Tree) to quickly find the maximum element and then update the maximum elements if need be.
We start with processing the first K-1 elements and will store their counts in the hash table. We will also store the distinct elements in a set.
After that, we process the last element of every window.
If the current element is a unique one we will add it to the set and increase the count.
After we process the last element, we are going to print the maximum unique from the set.
Before moving for the next iteration we will remove the first element of the previous window.
Print the maximum unique element in every subarray.
Dry Run
C++ Implementation
# include <bits/stdc++.h>
using namespace std;
// Function to find the maximum unique element in every subarray of size K
void unique_max(int A[], int N, int K)
{
map <int, int> eleCount;
for (int i = 0; i < K - 1; i++)
{
eleCount[A[i]]++;
}
set < int > uniqueMax;
for (auto x: eleCount)
if (x.second == 1)
{
uniqueMax.insert(x.first);
}
for (int i = K - 1; i < N; i++)
{
eleCount[A[i]]++;
if (eleCount[A[i]] == 1)
uniqueMax.insert(A[i]);
else
uniqueMax.erase(A[i]);
if (uniqueMax.size() == 0)
cout << "-1\n";
else
cout << * uniqueMax.rbegin() << "\n";
int x = A[i - K + 1];
eleCount[x]--;
if (eleCount[x] == 1)
uniqueMax.insert(x);
if (eleCount[x] == 0)
uniqueMax.erase(x);
}
}
int main()
{
int n;
cout << "Enter the size of the array:" << endl;
cin >> n;
int a[n], i;
cout << "Enter the array elements:" << endl;
for (i = 0; i < n; i++)
{
// Reading User Input array
cin >> a[i];
}
int k;
cout << "Enter the size of the subarray:" << endl;
cin >> k;
cout << "The maximum unique elements for a subarrays of size " << k << " are\n";
unique_max(a, n, k);
return 0;
}
You can also try this code with Online C++ Compiler
If N is the size of the array and K is the size of the subarray or sliding window, below are the time and space complexity of the approach:
Time Complexity: O(N log K)
Space Complexity: O(N)
Frequently Asked Questions
What is a Hash Table?
A hash table is a data structure that stores data associatively. Data is kept in an array format in a hash table, with each data value having its own unique index value. When we know the index of the needed data, we may get it extremely quickly.
On what metrics do we measure the performance of an algorithm?
We measure the performance of a particular algorithm on the basis of its time and space complexities.
What exactly do you mean by BFS?
BFS is an abbreviation for Breadth First Search. BFS employs a queue to determine the shortest path.
What is the meaning of the “auto” keyword in C++?
The auto keyword is a straightforward approach to declaring a variable with a complex type.
You can use auto, for example, to declare a variable whose initialization phrase contains templates, pointers to functions, or references to members.
Why is the Binary Search Tree employed?
It can be utilized in various instances where we need to compare sorted data.
Conclusion
So, in this blog, we discussed the problem of finding the maximum unique element in every subarray of size k, its solution approaches, its implementation, and time complexity.
We saw how to use the sliding window approach to find the maximum unique element in every subarray most efficiently with the help of a hash tablet and set. We hope that now you have a clear understanding of the problem and that you are ready to give it an attempt yourself!
If you found this one interesting, explore our other Data Structures and Algorithm-related blogs as well:
































 8+ registered
8+ registered 

