


























Introduction
MapReduce is a programming model for creating Big Data applications that run parallel on multiple nodes. MapReduce is an analytical framework for evaluating large amounts of detailed data. We need to understand some characteristics of the execution framework to know why things work the way they do. This understanding will help us design better applications and optimize the execution for efficiency.
There are four foundational pillars of behaviors of MapReduce that are being worked on to enrich our programming model:
- Scheduling
- Synchronization
- Colocation of code and data
-
Fault/Error handling
Let’s go through each of them one by one:
Scheduling
As we know, there are two portions in MapReduce. One is the “map,” and the other is “reduce." We divide both parts of the application into distinct tasks. The mapping must be complete before lowering. These tasks are prioritized based on the number of nodes in the cluster. If there are more map tasks than nodes, the execution framework will handle them until they are finished. The decreased tasks will behave in the same way. The procedure is complete only when all of the reduction tasks have been completed successfully.
There are mainly three types of schedulers in Hadoop :
- FIFO (First In First Out) Scheduler.
- Capacity Scheduler.
-
Fair Scheduler.
These Schedulers are a type of algorithm that we use when getting requests from various customers.
FIFO Scheduler
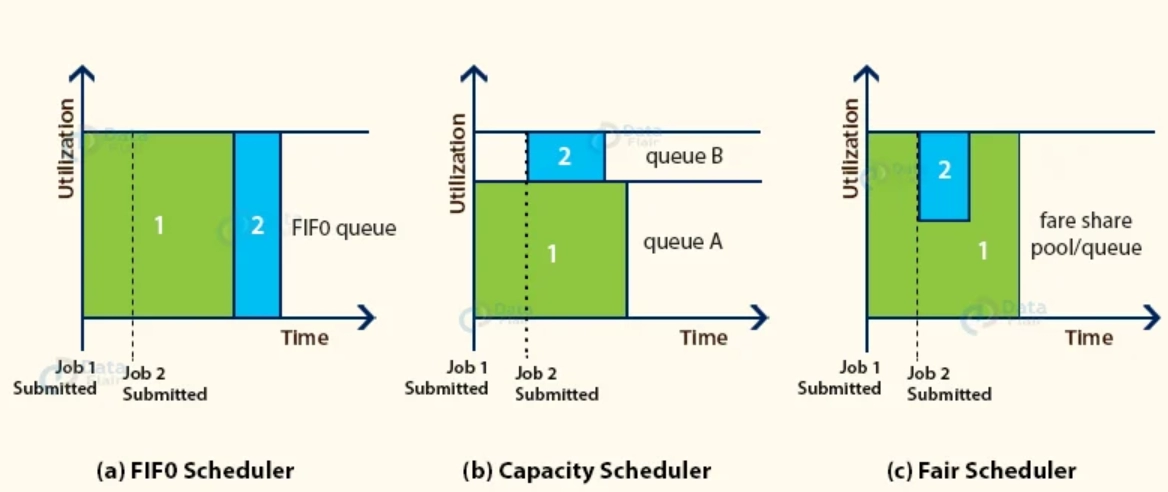
As the name implies, FIFO stands for First In First Out, which means that the tasks or applications that arrive first are served first. The jobs are placed in a queue and completed in the order they are submitted. No intervention is permitted once the project has been booked using this manner. As a result, because the task's priority does not matter in this manner, the high-priority process may have to wait for a lengthy period.
Advantages
- It's easy to use and doesn't require any configuration.
- Jobs are completed in the order in which they were submitted.
Disadvantages
- It is not ideal for clusters that are shared. If the large program runs ahead of the smaller ones, the huge application will consume all of the cluster's resources, and the minor application will have to wait for its turn. This results in hunger.
- It does not account for the resource allocation balance between long and short applications.
Capacity Scheduler
We have many work queues in Capacity Scheduler for scheduling our tasks. Multiple inhabitants can share a large Hadoop cluster with the Capacity Scheduler. We assign some slots or cluster resources for completing job operations in the Capacity Scheduler corresponding to each job queue. Each job queue has its own set of slots for completing its tasks. If we only have tasks to do in one queue, those tasks can access the slots of other queues because they are free to utilize, and when a new task enters another queue, tasks now running in that cluster's slots are replaced with their task.
Advantages
- It maximizes the Hadoop cluster's resource use and throughput.
- Provides groups or organizations with cost-effective elasticity.
- It also provides capacity guarantees and safeguards to the cluster-using organization.
Disadvantages
- Among the other schedulers, it is the most complicated.
Fair Scheduler
The capacity scheduler and the fair scheduler are highly similar. The job's priority is taken into consideration. The resources are allocated so that each application in a cluster receives the same amount of time. A fair scheduler makes scheduling decisions based on memory but can also be configured to work with the CPU.
Advantages
- It provides a suitable solution for a large number of users to share the Hadoop Cluster.
- In addition, the FairScheduler may interact with app priorities, which are utilized as weights in calculating what fraction of total resources each program should receive.
Disadvantages
- It has to be configured.



 9+ registered
9+ registered 

