Do you think IIT Guwahati certified course can help you in your career?
Introduction
Pandas is a python library that helps to analyze, clean, and manipulate the data. Pandas stand for “Python data analysis library”. It provides a data structure that helps to manage numerical tables and time series. Pandas is derived from the word “Panel Data” which is an econometric term for multidimensional structured datasets.
Features
1. Handling data
As it is a data analysis library, it provides a fast and efficient way to explore and manage the data. It does that by providing Series and DataFrame data structure.
2. Input and output tools
It has a wide range of input and output tools that make data reading and data writing much easier and faster.
3. Visualization
Visualization is an important part of data science. To analyze patterns and trends it is necessary to visualize data. Pandas have an inbuilt feature that helps to visualize the dataset.
4. Performing mathematical operations
Modification of data in a statistical manner requires lots of mathematical operations. In pandas, nearly every operation has an inbuilt function where simple and complex mathematical operations can be executed.
Installation
For Conda
conda install pandas
For a specific version in conda
conda install pandas=version
For ubuntu
sudo apt-get install python3-pandas
For pip (via anaconda)
!pip install pandas
You can install pandas into your local machine in any of these ways.
After the installation process, import the pandas library to start using it.
Importing library
import pandas as pd
What type of data do Pandas handle?
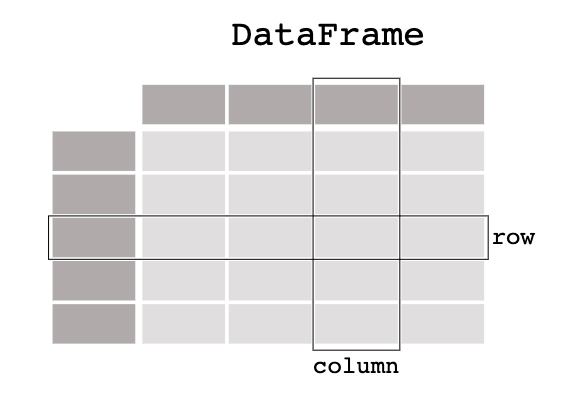
Pandas support two data structures. One is Series, and another is DataFrame. Series is a one-dimensional data structure of the labeled array that can hold data of any type (int, float, double, string, python object, etc.). DataFrame is a two-dimensional data structure that is arranged in rows and columns. Basically, it is a heterogeneous data structure having a tabular form with labeled axes(columns and rows).
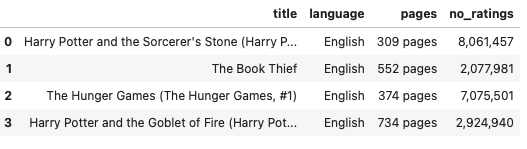
The most used way of reading the data is through a .csv file.
data = pd.read_csv("goodreads.csv")
To write the DataFrame into the .csv file we use the “to_csv” command.
data.to_csv("dataframestored.csv")
A file named “dataframestored.csv” is created in the current working directory.
There are similar functions like “read_excel” and “to_excel” that reads and writes data from a .csv file.
Selecting subset and dropping a column of a DataFrame
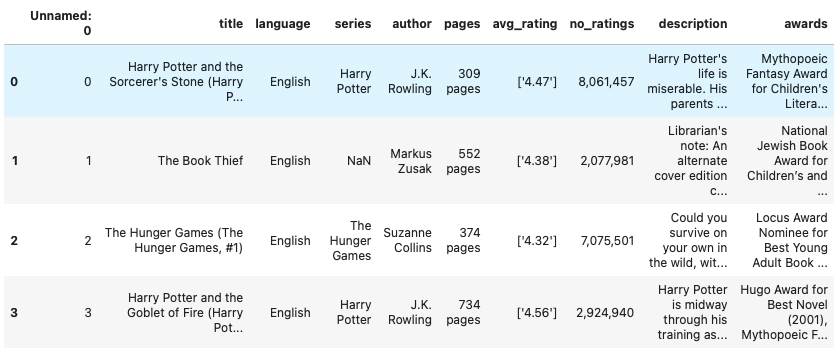
While reading the dataset, some of the columns are necessary, and some are useless, so for analyzing purposes, we must select a subset of the Dataframe. For model training, we have to eliminate some columns. Below are a few code snippets that will help you to select and drop the column of a DataFrame.
We are loading four columns from the data DataFrame.
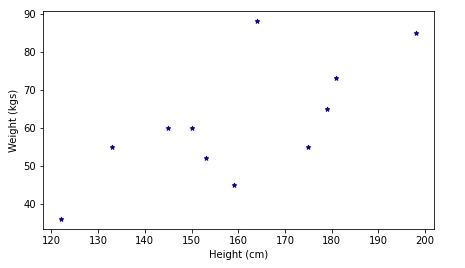
A scatter plot using Height and Weight column, the x-axis represents Height column and the y-axis represents Weight column.
data.plot.scatter(x = "Height (cm)", y = "Weight (kgs)", figsize=(7, 4), color = 'darkblue', marker='*')
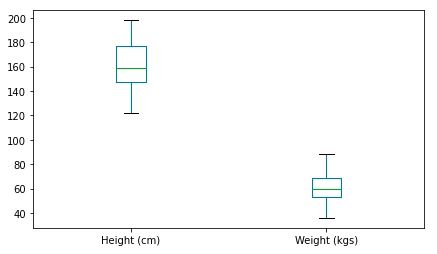
A box plot for the entire DataFrame.
data.plot.box(figsize=(7, 4))
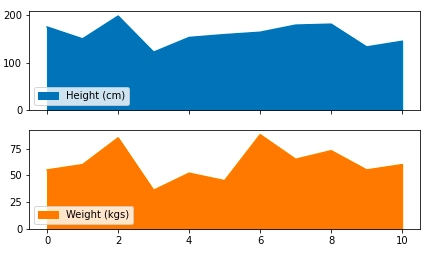
Two area subplots for Height and Weight.
data.plot.area(figsize=(7, 4), subplots=True)
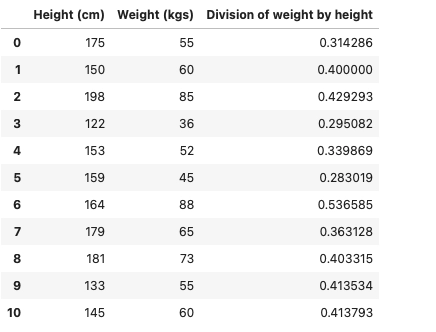
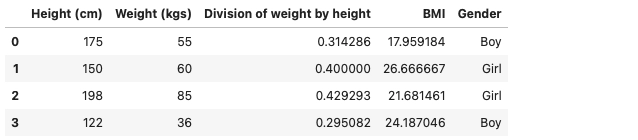
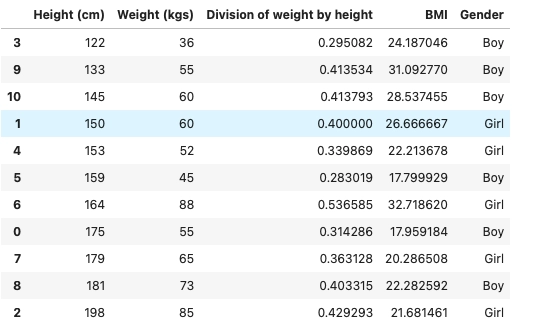
Creating new columns from existing ones
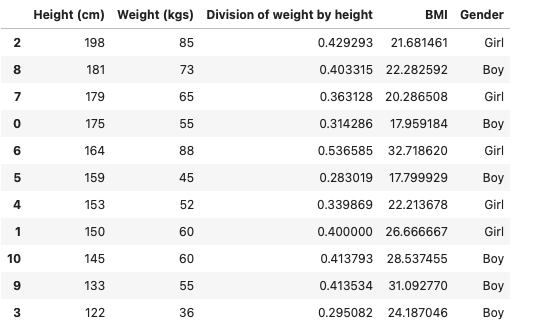
Let us consider the DataFrame of height and weight from the previous example. We will be adding an extra column to the DataFrame, i.e., division of height and weight. Furthermore, I will be calculating the Body Mass Index using the existing DataFrame and adding it into the DataFrame.
data['Division of weight and height'] = data['Weight (kgs)'] / data['Height (cm)']
data
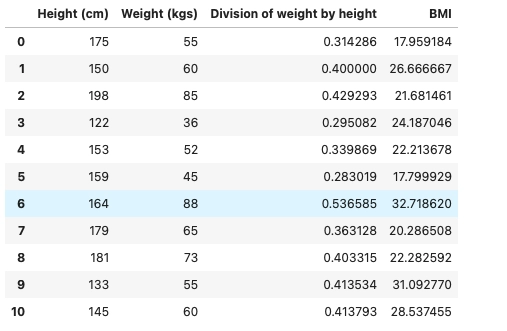
Now we will calculate the Body Mass Index for each row. The formula for Body Mass Index is weight(kgs) / height2(mtr)
data["BMI"] = (data['Division of weight by height']*10000) / data['Height (cm)'] data
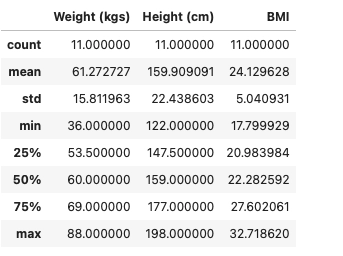
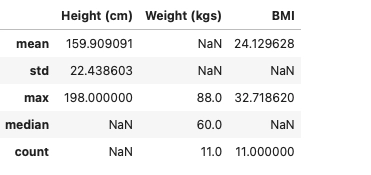
Calculating summary statistics
Let us calculate summary for the above taken DataFrame.
The average weight and the average height of the DataFrame using the “.mean()” method.
How much memory can pandas use? Pandas is very efficient with small data (usually from 100MB up to 1GB), and performance is rarely a concern.
Are pandas DataFrames thread-safe? No, pandas DataFrames are not thread-safe.
Can a Pandas series object hold data of different types? Pandas Series is a one-dimensional labeled array capable of holding data of any type (integer, string, float, python objects, etc.).
Are pandas multithreaded? By default, Pandas executes its functions as a single process using a single CPU core. That works just fine for smaller datasets since you might not notice much difference in speed.
Key Takeaways
In this article, we have seen the installation of pandas.
Pandas data structure format.
Basic functions with examples.
Want to learn more about Machine Learning? Here is an excellent course that can guide you in learning.
Happy Coding!
Live masterclass
Build GenAI Projects that can get you Amazon interview
by Anubhav Sinha
23 Jul, 2026
11:30 AM
Get shortlisted for Amazon data interview: SQL+Python Prep
by Abhishek Soni
20 Jul, 2026
11:30 AM
Top 5 GenAI Projects to Crack 25 LPA+ Roles in 2026
by Shantanu Shubham
21 Jul, 2026
12:30 PM
Interview-Ready Excel & AI Skills for Amazon Analyst Roles
by Prerita Agarwal
22 Jul, 2026
12:30 PM
Build GenAI Projects that can get you Amazon interview
by Anubhav Sinha
23 Jul, 2026
11:30 AM
Get shortlisted for Amazon data interview: SQL+Python Prep






























 6+ registered
6+ registered 

